 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFair Finetuning Mitigates Distribution Inference Attacks
Jun 01, 2026Machine learning models trained on sensitive data can inadvertently leak population-level information about their training distributions -- a threat known as distribution inference attack (DIA). An adversary with black-box access can infer sensitive demographic properties, such as subgroup proportions, without observing any training data directly. While defenses such as differential privacy and property unlearning have been proposed, the link between fairness constraints and distributional leakage remains unexplored. We propose Fair Fine-tuning (FFt): a trained model is fine-tuned on samples from the complementary distribution under an Equalized Odds (EO) constraint. We provide a complete theoretical characterization, proving the tight bound $\text{Adv}(\mathcal{A},M_f) \le Δ_{\text{EO}} \cdot W$, where $W$ quantifies how distinguishable the two training distributions are by their sensitive-attribute composition. We also establish a necessary condition for FFt to reduce adversarial advantage and prove tightness of the bound. We evaluate across six datasets spanning tabular (ACS Income, COMPAS, German Credit), image (UTKFaces), and NLP (Bias in Bios) modalities. Rehearsal-based FFt consistently reduces the adversarial accuracy gap below the detection threshold $τ!=!0.1$ across all settings; on ACS Income, the gap falls from $\sim!15%$ to under $4%$. Our work provides the first formal bound connecting a model's measured EO disparity directly to its adversarial advantage in the DIA game, opening a new avenue for unified fairness-and-privacy defenses.
Personalized Differential Privacy for Ridge Regression
Jan 30, 2024The increased application of machine learning (ML) in sensitive domains requires protecting the training data through privacy frameworks, such as differential privacy (DP). DP requires to specify a uniform privacy level $\varepsilon$ that expresses the maximum privacy loss that each data point in the entire dataset is willing to tolerate. Yet, in practice, different data points often have different privacy requirements. Having to set one uniform privacy level is usually too restrictive, often forcing a learner to guarantee the stringent privacy requirement, at a large cost to accuracy. To overcome this limitation, we introduce our novel Personalized-DP Output Perturbation method (PDP-OP) that enables to train Ridge regression models with individual per data point privacy levels. We provide rigorous privacy proofs for our PDP-OP as well as accuracy guarantees for the resulting model. This work is the first to provide such theoretical accuracy guarantees when it comes to personalized DP in machine learning, whereas previous work only provided empirical evaluations. We empirically evaluate PDP-OP on synthetic and real datasets and with diverse privacy distributions. We show that by enabling each data point to specify their own privacy requirement, we can significantly improve the privacy-accuracy trade-offs in DP. We also show that PDP-OP outperforms the personalized privacy techniques of Jorgensen et al. (2015).
Toward Operationalizing Pipeline-aware ML Fairness: A Research Agenda for Developing Practical Guidelines and Tools
Sep 29, 2023



While algorithmic fairness is a thriving area of research, in practice, mitigating issues of bias often gets reduced to enforcing an arbitrarily chosen fairness metric, either by enforcing fairness constraints during the optimization step, post-processing model outputs, or by manipulating the training data. Recent work has called on the ML community to take a more holistic approach to tackle fairness issues by systematically investigating the many design choices made through the ML pipeline, and identifying interventions that target the issue's root cause, as opposed to its symptoms. While we share the conviction that this pipeline-based approach is the most appropriate for combating algorithmic unfairness on the ground, we believe there are currently very few methods of \emph{operationalizing} this approach in practice. Drawing on our experience as educators and practitioners, we first demonstrate that without clear guidelines and toolkits, even individuals with specialized ML knowledge find it challenging to hypothesize how various design choices influence model behavior. We then consult the fair-ML literature to understand the progress to date toward operationalizing the pipeline-aware approach: we systematically collect and organize the prior work that attempts to detect, measure, and mitigate various sources of unfairness through the ML pipeline. We utilize this extensive categorization of previous contributions to sketch a research agenda for the community. We hope this work serves as the stepping stone toward a more comprehensive set of resources for ML researchers, practitioners, and students interested in exploring, designing, and testing pipeline-oriented approaches to algorithmic fairness.
Are Chatbots Ready for Privacy-Sensitive Applications? An Investigation into Input Regurgitation and Prompt-Induced Sanitization
May 24, 2023



LLM-powered chatbots are becoming widely adopted in applications such as healthcare, personal assistants, industry hiring decisions, etc. In many of these cases, chatbots are fed sensitive, personal information in their prompts, as samples for in-context learning, retrieved records from a database, or as part of the conversation. The information provided in the prompt could directly appear in the output, which might have privacy ramifications if there is sensitive information there. As such, in this paper, we aim to understand the input copying and regurgitation capabilities of these models during inference and how they can be directly instructed to limit this copying by complying with regulations such as HIPAA and GDPR, based on their internal knowledge of them. More specifically, we find that when ChatGPT is prompted to summarize cover letters of a 100 candidates, it would retain personally identifiable information (PII) verbatim in 57.4% of cases, and we find this retention to be non-uniform between different subgroups of people, based on attributes such as gender identity. We then probe ChatGPT's perception of privacy-related policies and privatization mechanisms by directly instructing it to provide compliant outputs and observe a significant omission of PII from output.
Pruning has a disparate impact on model accuracy
May 26, 2022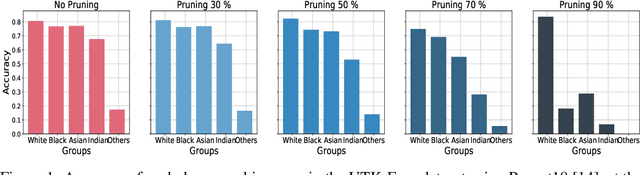
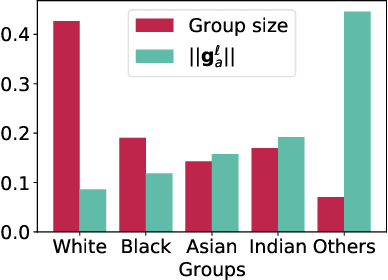

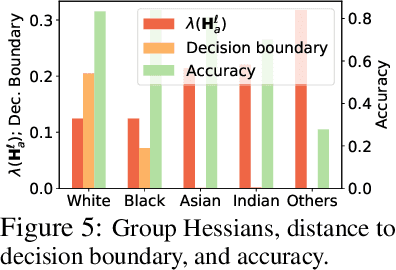
Network pruning is a widely-used compression technique that is able to significantly scale down overparameterized models with minimal loss of accuracy. This paper shows that pruning may create or exacerbate disparate impacts. The paper sheds light on the factors to cause such disparities, suggesting differences in gradient norms and distance to decision boundary across groups to be responsible for this critical issue. It analyzes these factors in detail, providing both theoretical and empirical support, and proposes a simple, yet effective, solution that mitigates the disparate impacts caused by pruning.
Interpretability of Fine-grained Classification of Sadness and Depression
Mar 20, 2022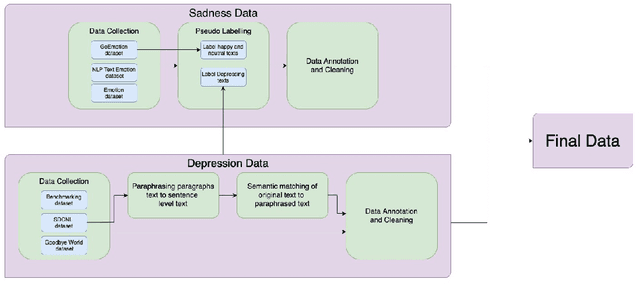


While sadness is a human emotion that people experience at certain times throughout their lives, inflicting them with emotional disappointment and pain, depression is a longer term mental illness which impairs social, occupational, and other vital regions of functioning making it a much more serious issue and needs to be catered to at the earliest. NLP techniques can be utilized for the detection and subsequent diagnosis of these emotions. Most of the open sourced data on the web deal with sadness as a part of depression, as an emotion even though the difference in severity of both is huge. Thus, we create our own novel dataset illustrating the difference between the two. In this paper, we aim to highlight the difference between the two and highlight how interpretable our models are to distinctly label sadness and depression. Due to the sensitive nature of such information, privacy measures need to be taken for handling and training of such data. Hence, we also explore the effect of Federated Learning (FL) on contextualised language models.
Privacy enabled Financial Text Classification using Differential Privacy and Federated Learning
Oct 04, 2021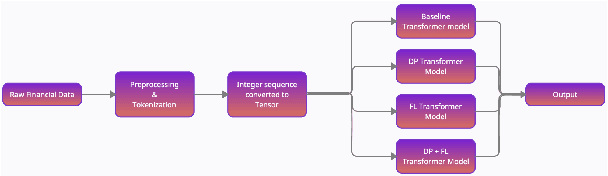
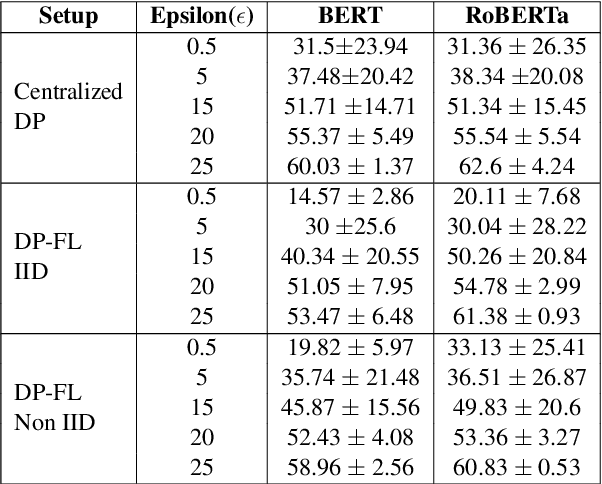
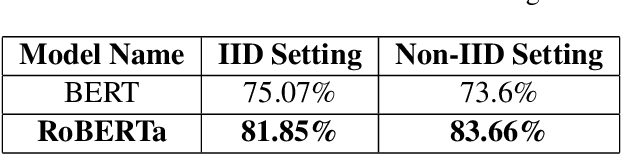
Privacy is important considering the financial Domain as such data is highly confidential and sensitive. Natural Language Processing (NLP) techniques can be applied for text classification and entity detection purposes in financial domains such as customer feedback sentiment analysis, invoice entity detection, categorisation of financial documents by type etc. Due to the sensitive nature of such data, privacy measures need to be taken for handling and training large models with such data. In this work, we propose a contextualized transformer (BERT and RoBERTa) based text classification model integrated with privacy features such as Differential Privacy (DP) and Federated Learning (FL). We present how to privately train NLP models and desirable privacy-utility tradeoffs and evaluate them on the Financial Phrase Bank dataset.
Efficient Hyperparameter Optimization for Differentially Private Deep Learning
Aug 09, 2021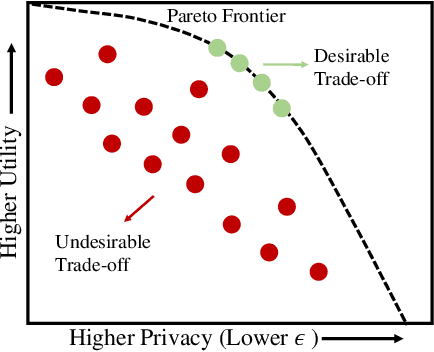
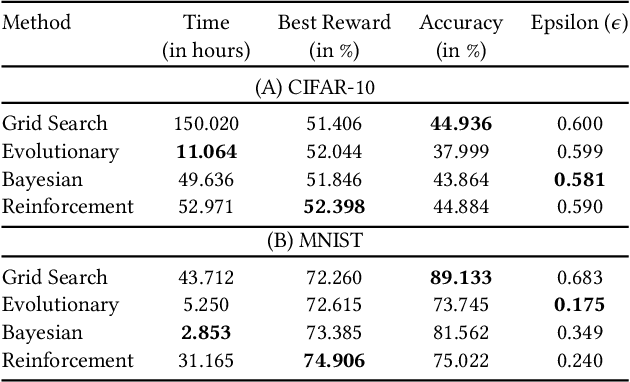
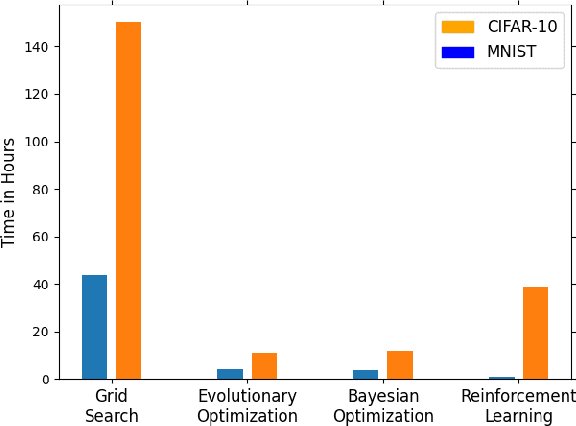
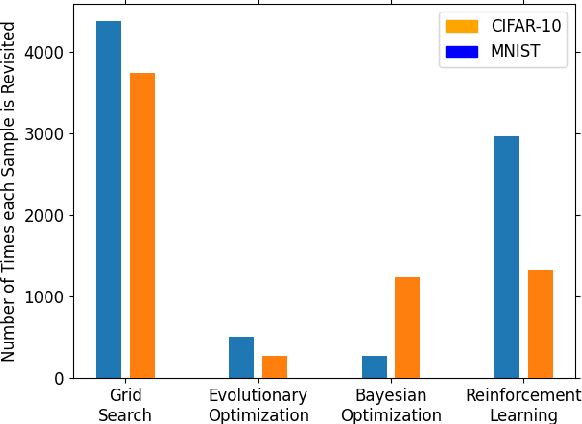
Tuning the hyperparameters in the differentially private stochastic gradient descent (DPSGD) is a fundamental challenge. Unlike the typical SGD, private datasets cannot be used many times for hyperparameter search in DPSGD; e.g., via a grid search. Therefore, there is an essential need for algorithms that, within a given search space, can find near-optimal hyperparameters for the best achievable privacy-utility tradeoffs efficiently. We formulate this problem into a general optimization framework for establishing a desirable privacy-utility tradeoff, and systematically study three cost-effective algorithms for being used in the proposed framework: evolutionary, Bayesian, and reinforcement learning. Our experiments, for hyperparameter tuning in DPSGD conducted on MNIST and CIFAR-10 datasets, show that these three algorithms significantly outperform the widely used grid search baseline. As this paper offers a first-of-a-kind framework for hyperparameter tuning in DPSGD, we discuss existing challenges and open directions for future studies. As we believe our work has implications to be utilized in the pipeline of private deep learning, we open-source our code at https://github.com/AmanPriyanshu/DP-HyperparamTuning.
Towards Quantifying the Carbon Emissions of Differentially Private Machine Learning
Jul 14, 2021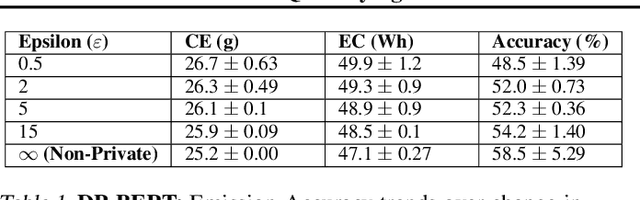
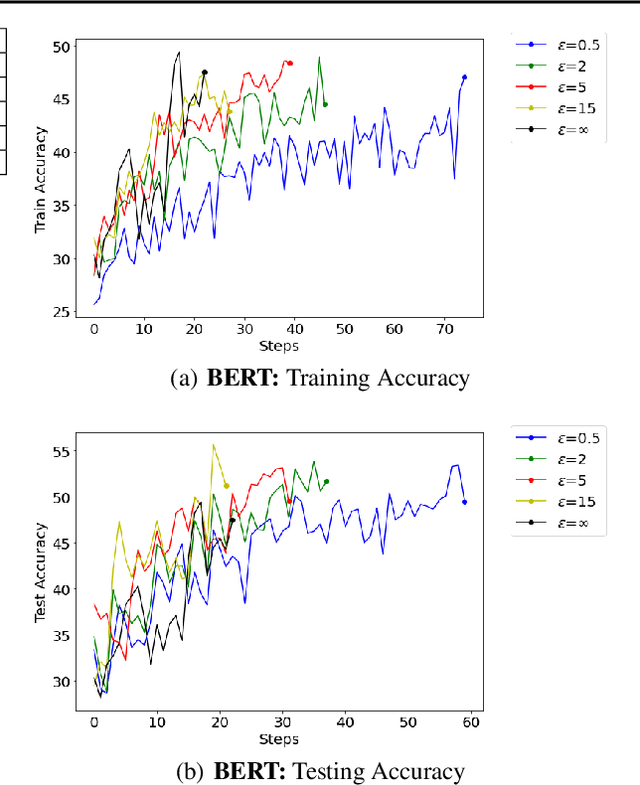
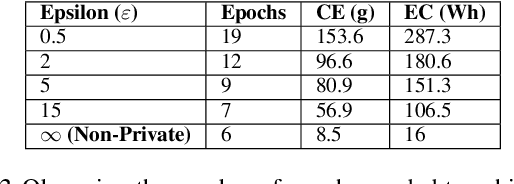
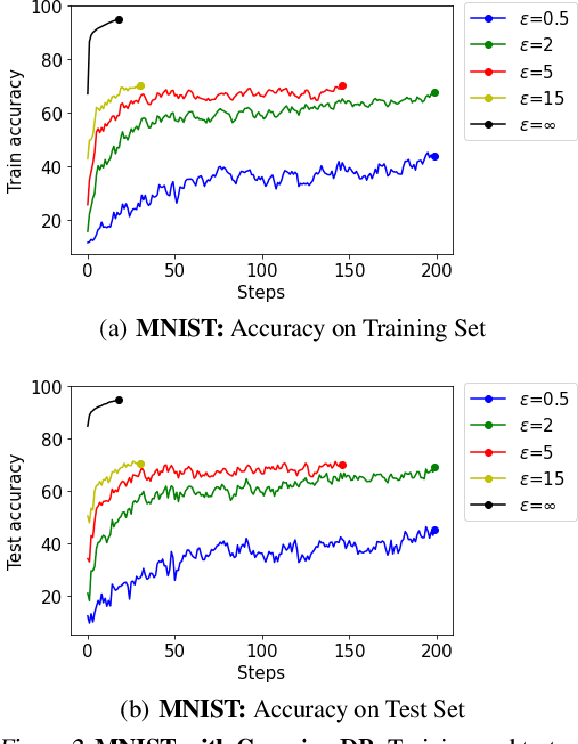
In recent years, machine learning techniques utilizing large-scale datasets have achieved remarkable performance. Differential privacy, by means of adding noise, provides strong privacy guarantees for such learning algorithms. The cost of differential privacy is often a reduced model accuracy and a lowered convergence speed. This paper investigates the impact of differential privacy on learning algorithms in terms of their carbon footprint due to either longer run-times or failed experiments. Through extensive experiments, further guidance is provided on choosing the noise levels which can strike a balance between desired privacy levels and reduced carbon emissions.
Benchmarking Differential Privacy and Federated Learning for BERT Models
Jun 26, 2021
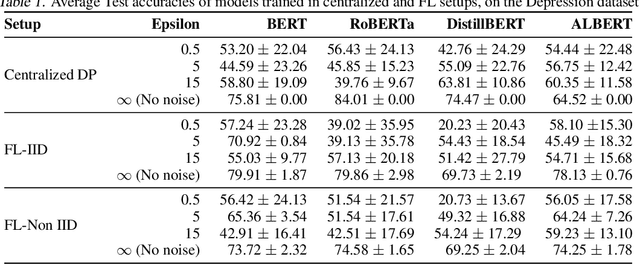
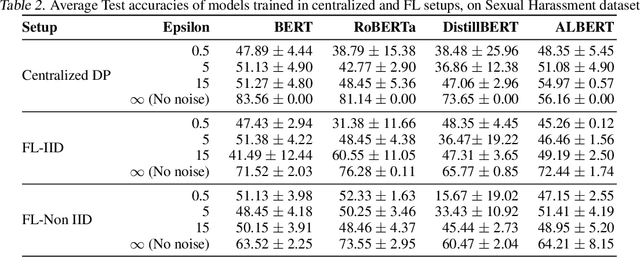
Natural Language Processing (NLP) techniques can be applied to help with the diagnosis of medical conditions such as depression, using a collection of a person's utterances. Depression is a serious medical illness that can have adverse effects on how one feels, thinks, and acts, which can lead to emotional and physical problems. Due to the sensitive nature of such data, privacy measures need to be taken for handling and training models with such data. In this work, we study the effects that the application of Differential Privacy (DP) has, in both a centralized and a Federated Learning (FL) setup, on training contextualized language models (BERT, ALBERT, RoBERTa and DistilBERT). We offer insights on how to privately train NLP models and what architectures and setups provide more desirable privacy utility trade-offs. We envisage this work to be used in future healthcare and mental health studies to keep medical history private. Therefore, we provide an open-source implementation of this work.