 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTool-Aware Planning in Contact Center AI: Evaluating LLMs through Lineage-Guided Query Decomposition
Feb 16, 2026We present a domain-grounded framework and benchmark for tool-aware plan generation in contact centers, where answering a query for business insights, our target use case, requires decomposing it into executable steps over structured tools (Text2SQL (T2S)/Snowflake) and unstructured tools (RAG/transcripts) with explicit depends_on for parallelism. Our contributions are threefold: (i) a reference-based plan evaluation framework operating in two modes - a metric-wise evaluator spanning seven dimensions (e.g., tool-prompt alignment, query adherence) and a one-shot evaluator; (ii) a data curation methodology that iteratively refines plans via an evaluator->optimizer loop to produce high-quality plan lineages (ordered plan revisions) while reducing manual effort; and (iii) a large-scale study of 14 LLMs across sizes and families for their ability to decompose queries into step-by-step, executable, and tool-assigned plans, evaluated under prompts with and without lineage. Empirically, LLMs struggle on compound queries and on plans exceeding 4 steps (typically 5-15); the best total metric score reaches 84.8% (Claude-3-7-Sonnet), while the strongest one-shot match rate at the "A+" tier (Extremely Good, Very Good) is only 49.75% (o3-mini). Plan lineage yields mixed gains overall but benefits several top models and improves step executability for many. Our results highlight persistent gaps in tool-understanding, especially in tool-prompt alignment and tool-usage completeness, and show that shorter, simpler plans are markedly easier. The framework and findings provide a reproducible path for assessing and improving agentic planning with tools for answering data-analysis queries in contact-center settings.
Counterfactual Fairness Evaluation of LLM-Based Contact Center Agent Quality Assurance System
Feb 16, 2026Large Language Models (LLMs) are increasingly deployed in contact-center Quality Assurance (QA) to automate agent performance evaluation and coaching feedback. While LLMs offer unprecedented scalability and speed, their reliance on web-scale training data raises concerns regarding demographic and behavioral biases that may distort workforce assessment. We present a counterfactual fairness evaluation of LLM-based QA systems across 13 dimensions spanning three categories: Identity, Context, and Behavioral Style. Fairness is quantified using the Counterfactual Flip Rate (CFR), the frequency of binary judgment reversals, and the Mean Absolute Score Difference (MASD), the average shift in coaching or confidence scores across counterfactual pairs. Evaluating 18 LLMs on 3,000 real-world contact center transcripts, we find systematic disparities, with CFR ranging from 5.4% to 13.0% and consistent MASD shifts across confidence, positive, and improvement scores. Larger, more strongly aligned models show lower unfairness, though fairness does not track accuracy. Contextual priming of historical performance induces the most severe degradations (CFR up to 16.4%), while implicit linguistic identity cues remain a persistent bias source. Finally, we analyze the efficacy of fairness-aware prompting, finding that explicit instructions yield only modest improvements in evaluative consistency. Our findings underscore the need for standardized fairness auditing pipelines prior to deploying LLMs in high-stakes workforce evaluation.
Why Synthetic Isn't Real Yet: A Diagnostic Framework for Contact Center Dialogue Generation
Aug 25, 2025Synthetic transcript generation is critical in contact center domains, where privacy and data scarcity limit model training and evaluation. Unlike prior synthetic dialogue generation work on open-domain or medical dialogues, contact center conversations are goal-oriented, role-asymmetric, and behaviorally complex, featuring disfluencies, ASR noise, and compliance-driven agent actions. In deployments where transcripts are unavailable, standard pipelines still yield derived call attributes such as Intent Summaries, Topic Flow, and QA Evaluation Forms. We leverage these as supervision signals to guide generation. To assess the quality of such outputs, we introduce a diagnostic framework of 18 linguistically and behaviorally grounded metrics for comparing real and synthetic transcripts. We benchmark four language-agnostic generation strategies, from simple prompting to characteristic-aware multi-stage approaches, alongside reference-free baselines. Results reveal persistent challenges: no method excels across all traits, with notable deficits in disfluency, sentiment, and behavioral realism. Our diagnostic tool exposes these gaps, enabling fine-grained evaluation and stress testing of synthetic dialogue across languages.
Instance Segmentation and Teeth Classification in Panoramic X-rays
Jun 06, 2024Teeth segmentation and recognition are critical in various dental applications and dental diagnosis. Automatic and accurate segmentation approaches have been made possible by integrating deep learning models. Although teeth segmentation has been studied in the past, only some techniques were able to effectively classify and segment teeth simultaneously. This article offers a pipeline of two deep learning models, U-Net and YOLOv8, which results in BB-UNet, a new architecture for the classification and segmentation of teeth on panoramic X-rays that is efficient and reliable. We have improved the quality and reliability of teeth segmentation by utilising the YOLOv8 and U-Net capabilities. The proposed networks have been evaluated using the mean average precision (mAP) and dice coefficient for YOLOv8 and BB-UNet, respectively. We have achieved a 3\% increase in mAP score for teeth classification compared to existing methods, and a 10-15\% increase in dice coefficient for teeth segmentation compared to U-Net across different categories of teeth. A new Dental dataset was created based on UFBA-UESC dataset with Bounding-Box and Polygon annotations of 425 dental panoramic X-rays. The findings of this research pave the way for a wider adoption of object detection models in the field of dental diagnosis.
Automatic AI controller that can drive with confidence: steering vehicle with uncertainty knowledge
Apr 24, 2024
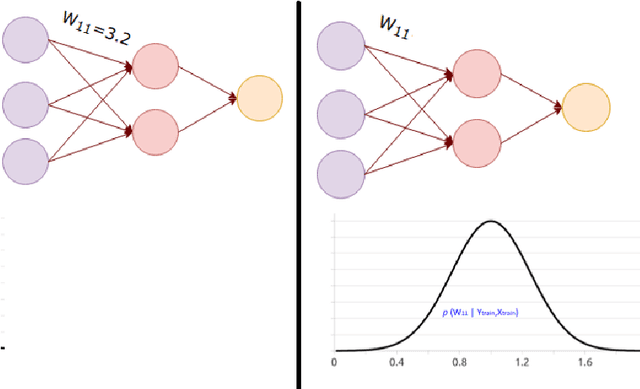

In safety-critical systems that interface with the real world, the role of uncertainty in decision-making is pivotal, particularly in the context of machine learning models. For the secure functioning of Cyber-Physical Systems (CPS), it is imperative to manage such uncertainty adeptly. In this research, we focus on the development of a vehicle's lateral control system using a machine learning framework. Specifically, we employ a Bayesian Neural Network (BNN), a probabilistic learning model, to address uncertainty quantification. This capability allows us to gauge the level of confidence or uncertainty in the model's predictions. The BNN based controller is trained using simulated data gathered from the vehicle traversing a single track and subsequently tested on various other tracks. We want to share two significant results: firstly, the trained model demonstrates the ability to adapt and effectively control the vehicle on multiple similar tracks. Secondly, the quantification of prediction confidence integrated into the controller serves as an early-warning system, signaling when the algorithm lacks confidence in its predictions and is therefore susceptible to failure. By establishing a confidence threshold, we can trigger manual intervention, ensuring that control is relinquished from the algorithm when it operates outside of safe parameters.
Towards Probing Contact Center Large Language Models
Dec 26, 2023Fine-tuning large language models (LLMs) with domain-specific instructions has emerged as an effective method to enhance their domain-specific understanding. Yet, there is limited work that examines the core characteristics acquired during this process. In this study, we benchmark the fundamental characteristics learned by contact-center (CC) specific instruction fine-tuned LLMs with out-of-the-box (OOB) LLMs via probing tasks encompassing conversational, channel, and automatic speech recognition (ASR) properties. We explore different LLM architectures (Flan-T5 and Llama), sizes (3B, 7B, 11B, 13B), and fine-tuning paradigms (full fine-tuning vs PEFT). Our findings reveal remarkable effectiveness of CC-LLMs on the in-domain downstream tasks, with improvement in response acceptability by over 48% compared to OOB-LLMs. Additionally, we compare the performance of OOB-LLMs and CC-LLMs on the widely used SentEval dataset, and assess their capabilities in terms of surface, syntactic, and semantic information through probing tasks. Intriguingly, we note a relatively consistent performance of probing classifiers on the set of probing tasks. Our observations indicate that CC-LLMs, while outperforming their out-of-the-box counterparts, exhibit a tendency to rely less on encoding surface, syntactic, and semantic properties, highlighting the intricate interplay between domain-specific adaptation and probing task performance opening up opportunities to explore behavior of fine-tuned language models in specialized contexts.
Are Chatbots Ready for Privacy-Sensitive Applications? An Investigation into Input Regurgitation and Prompt-Induced Sanitization
May 24, 2023



LLM-powered chatbots are becoming widely adopted in applications such as healthcare, personal assistants, industry hiring decisions, etc. In many of these cases, chatbots are fed sensitive, personal information in their prompts, as samples for in-context learning, retrieved records from a database, or as part of the conversation. The information provided in the prompt could directly appear in the output, which might have privacy ramifications if there is sensitive information there. As such, in this paper, we aim to understand the input copying and regurgitation capabilities of these models during inference and how they can be directly instructed to limit this copying by complying with regulations such as HIPAA and GDPR, based on their internal knowledge of them. More specifically, we find that when ChatGPT is prompted to summarize cover letters of a 100 candidates, it would retain personally identifiable information (PII) verbatim in 57.4% of cases, and we find this retention to be non-uniform between different subgroups of people, based on attributes such as gender identity. We then probe ChatGPT's perception of privacy-related policies and privatization mechanisms by directly instructing it to provide compliant outputs and observe a significant omission of PII from output.
Malaria detection using Deep Convolution Neural Network
Mar 04, 2023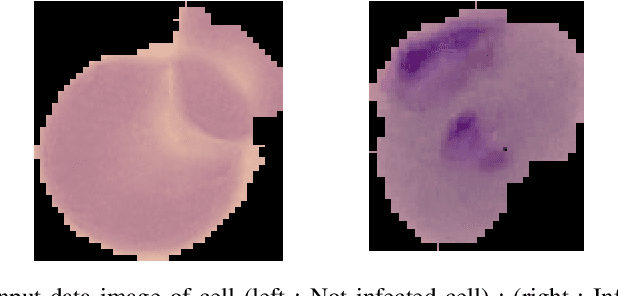
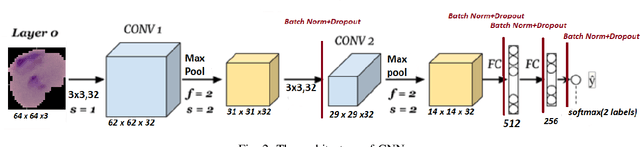

The latest WHO report showed that the number of malaria cases climbed to 219 million last year, two million higher than last year. The global efforts to fight malaria have hit a plateau and the most significant underlying reason is international funding has declined. Malaria, which is spread to people through the bites of infected female mosquitoes, occurs in 91 countries but about 90% of the cases and deaths are in sub-Saharan Africa. The disease killed 4,35,000 people last year, the majority of them children under five in Africa. AI-backed technology has revolutionized malaria detection in some regions of Africa and the future impact of such work can be revolutionary. The malaria Cell Image Data-set is taken from the official NIH Website NIH data. The aim of the collection of the dataset was to reduce the burden for microscopists in resource-constrained regions and improve diagnostic accuracy using an AI-based algorithm to detect and segment the red blood cells. The goal of this work is to show that the state of the art accuracy can be obtained even by using 2 layer convolution network and show a new baseline in Malaria detection efforts using AI.
Deep Learning Driven Natural Languages Text to SQL Query Conversion: A Survey
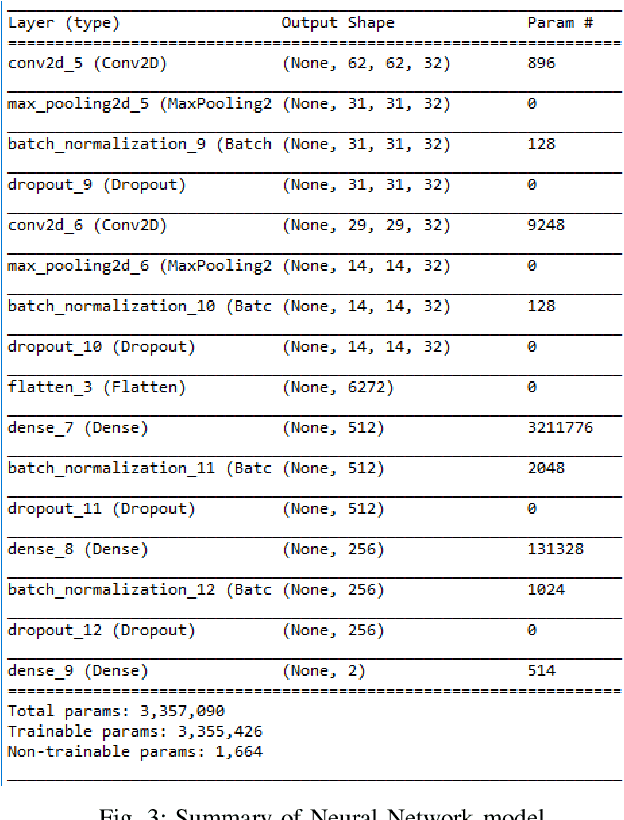
Aug 08, 2022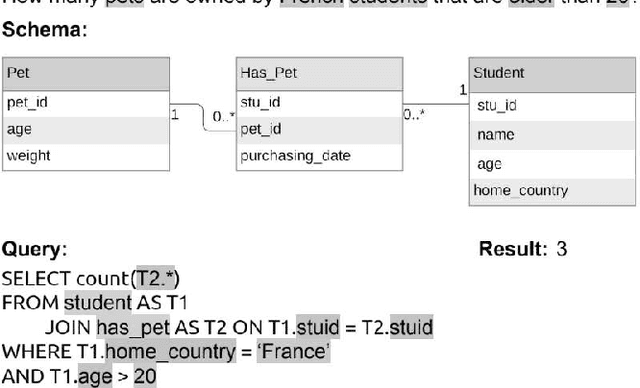
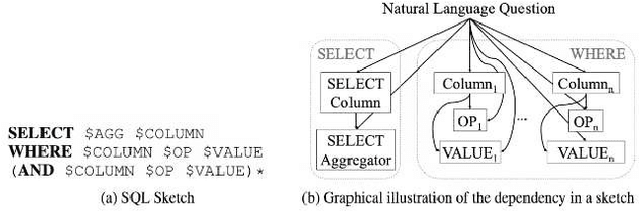
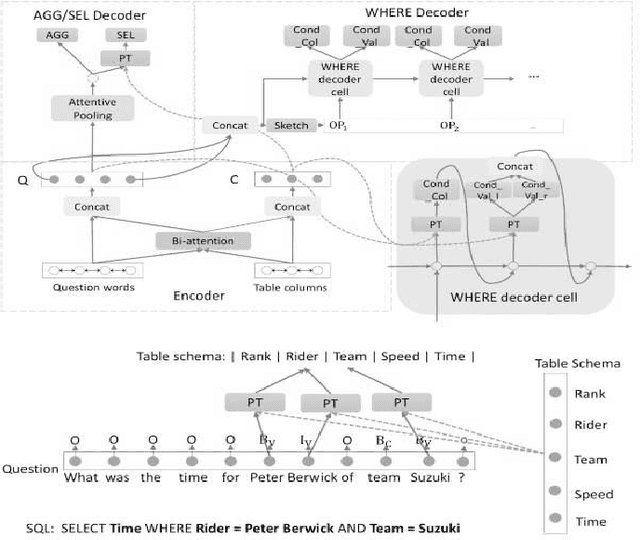
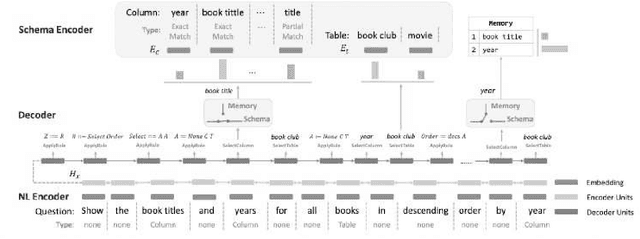
With the future striving toward data-centric decision-making, seamless access to databases is of utmost importance. There is extensive research on creating an efficient text-to-sql (TEXT2SQL) model to access data from the database. Using a Natural language is one of the best interfaces that can bridge the gap between the data and results by accessing the database efficiently, especially for non-technical users. It will open the doors and create tremendous interest among users who are well versed in technical skills or not very skilled in query languages. Even if numerous deep learning-based algorithms are proposed or studied, there still is very challenging to have a generic model to solve the data query issues using natural language in a real-work scenario. The reason is the use of different datasets in different studies, which comes with its limitations and assumptions. At the same time, we do lack a thorough understanding of these proposed models and their limitations with the specific dataset it is trained on. In this paper, we try to present a holistic overview of 24 recent neural network models studied in the last couple of years, including their architectures involving convolutional neural networks, recurrent neural networks, pointer networks, reinforcement learning, generative models, etc. We also give an overview of the 11 datasets that are widely used to train the models for TEXT2SQL technologies. We also discuss the future application possibilities of TEXT2SQL technologies for seamless data queries.
An Open Source Interactive Visual Analytics Tool for Comparative Programming Comprehension
Jul 29, 2022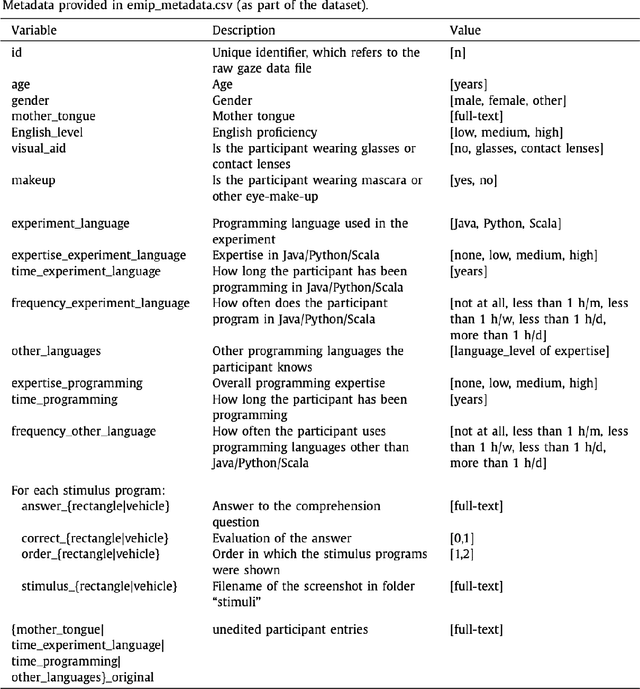



This paper proposes an open source visual analytics tool consisting of several views and perspectives on eye movement data collected during code reading tasks when writing computer programs. Hence the focus of this work is on code and program comprehension. The source code is shown as a visual stimulus. It can be inspected in combination with overlaid scanpaths in which the saccades can be visually encoded in several forms, including straight, curved, and orthogonal lines, modifiable by interaction techniques. The tool supports interaction techniques like filter functions, aggregations, data sampling, and many more. We illustrate the usefulness of our tool by applying it to the eye movements of 216 programmers of multiple expertise levels that were collected during two code comprehension tasks. Our tool helped to analyze the difference between the strategic program comprehension of programmers based on their demographic background, time taken to complete the task, choice of programming task, and expertise.