 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Probing Contact Center Large Language Models
Dec 26, 2023Fine-tuning large language models (LLMs) with domain-specific instructions has emerged as an effective method to enhance their domain-specific understanding. Yet, there is limited work that examines the core characteristics acquired during this process. In this study, we benchmark the fundamental characteristics learned by contact-center (CC) specific instruction fine-tuned LLMs with out-of-the-box (OOB) LLMs via probing tasks encompassing conversational, channel, and automatic speech recognition (ASR) properties. We explore different LLM architectures (Flan-T5 and Llama), sizes (3B, 7B, 11B, 13B), and fine-tuning paradigms (full fine-tuning vs PEFT). Our findings reveal remarkable effectiveness of CC-LLMs on the in-domain downstream tasks, with improvement in response acceptability by over 48% compared to OOB-LLMs. Additionally, we compare the performance of OOB-LLMs and CC-LLMs on the widely used SentEval dataset, and assess their capabilities in terms of surface, syntactic, and semantic information through probing tasks. Intriguingly, we note a relatively consistent performance of probing classifiers on the set of probing tasks. Our observations indicate that CC-LLMs, while outperforming their out-of-the-box counterparts, exhibit a tendency to rely less on encoding surface, syntactic, and semantic properties, highlighting the intricate interplay between domain-specific adaptation and probing task performance opening up opportunities to explore behavior of fine-tuned language models in specialized contexts.
Low Resource Pipeline for Spoken Language Understanding via Weak Supervision
Jun 21, 2022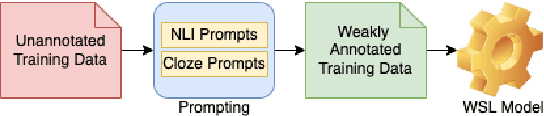
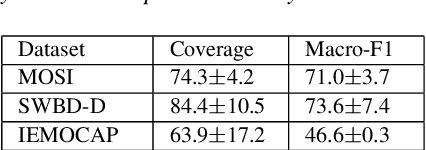
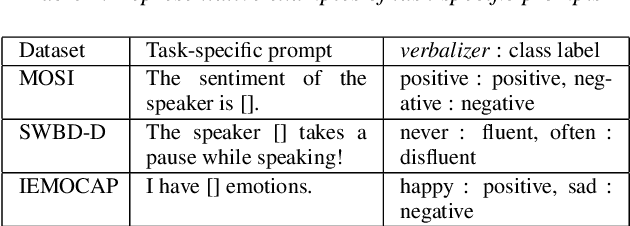

In Weak Supervised Learning (WSL), a model is trained over noisy labels obtained from semantic rules and task-specific pre-trained models. Rules offer limited generalization over tasks and require significant manual efforts while pre-trained models are available only for limited tasks. In this work, we propose to utilize prompt-based methods as weak sources to obtain the noisy labels on unannotated data. We show that task-agnostic prompts are generalizable and can be used to obtain noisy labels for different Spoken Language Understanding (SLU) tasks such as sentiment classification, disfluency detection and emotion classification. These prompts could additionally be updated to add task-specific contexts, thus providing flexibility to design task-specific prompts. We demonstrate that prompt-based methods generate reliable labels for the above SLU tasks and thus can be used as a universal weak source to train a weak-supervised model (WSM) in absence of labeled data. Our proposed WSL pipeline trained over prompt-based weak source outperforms other competitive low-resource benchmarks on zero and few-shot learning by more than 4% on Macro-F1 on all of the three benchmark SLU datasets. The proposed method also outperforms a conventional rule based WSL pipeline by more than 5% on Macro-F1.
What BERT Based Language Models Learn in Spoken Transcripts: An Empirical Study
Sep 21, 2021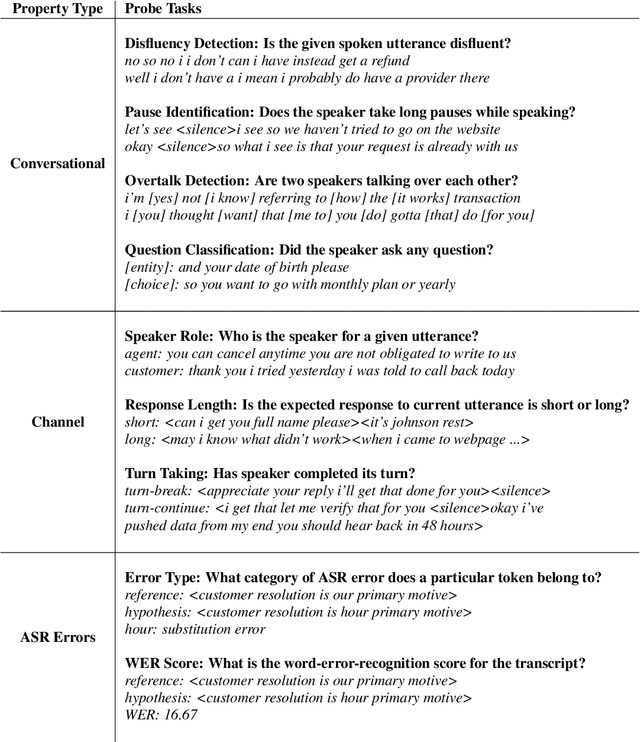
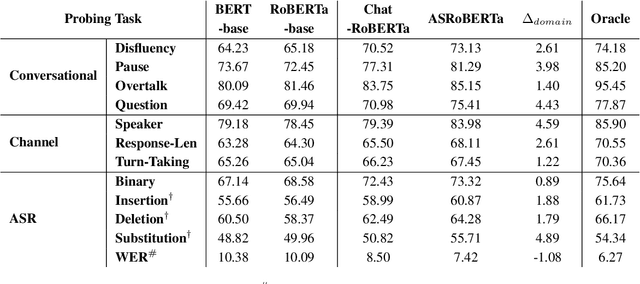


Language Models (LMs) have been ubiquitously leveraged in various tasks including spoken language understanding (SLU). Spoken language requires careful understanding of speaker interactions, dialog states and speech induced multimodal behaviors to generate a meaningful representation of the conversation. In this work, we propose to dissect SLU into three representative properties:conversational (disfluency, pause, overtalk), channel (speaker-type, turn-tasks) and ASR (insertion, deletion,substitution). We probe BERT based language models (BERT, RoBERTa) trained on spoken transcripts to investigate its ability to understand multifarious properties in absence of any speech cues. Empirical results indicate that LM is surprisingly good at capturing conversational properties such as pause prediction and overtalk detection from lexical tokens. On the downsides, the LM scores low on turn-tasks and ASR errors predictions. Additionally, pre-training the LM on spoken transcripts restrain its linguistic understanding. Finally, we establish the efficacy and transferability of the mentioned properties on two benchmark datasets: Switchboard Dialog Act and Disfluency datasets.
Phoneme-BERT: Joint Language Modelling of Phoneme Sequence and ASR Transcript
Feb 01, 2021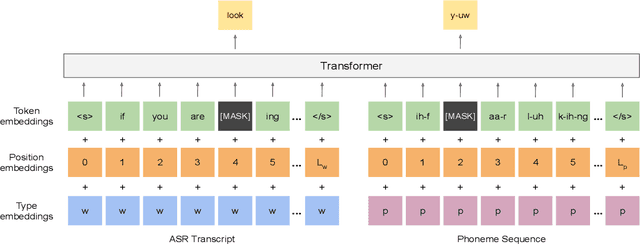
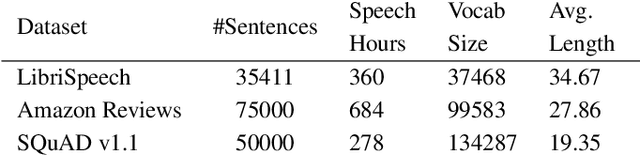

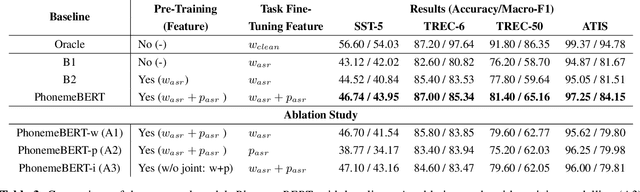
Recent years have witnessed significant improvement in ASR systems to recognize spoken utterances. However, it is still a challenging task for noisy and out-of-domain data, where substitution and deletion errors are prevalent in the transcribed text. These errors significantly degrade the performance of downstream tasks. In this work, we propose a BERT-style language model, referred to as PhonemeBERT, that learns a joint language model with phoneme sequence and ASR transcript to learn phonetic-aware representations that are robust to ASR errors. We show that PhonemeBERT can be used on downstream tasks using phoneme sequences as additional features, and also in low-resource setup where we only have ASR-transcripts for the downstream tasks with no phoneme information available. We evaluate our approach extensively by generating noisy data for three benchmark datasets - Stanford Sentiment Treebank, TREC and ATIS for sentiment, question and intent classification tasks respectively. The results of the proposed approach beats the state-of-the-art baselines comprehensively on each dataset.
Gated Mechanism for Attention Based Multimodal Sentiment Analysis
Feb 21, 2020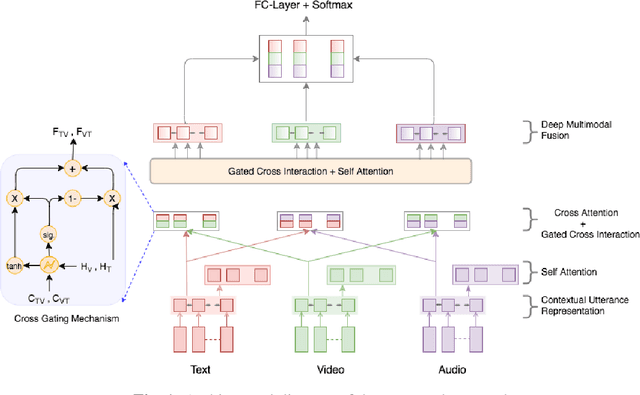

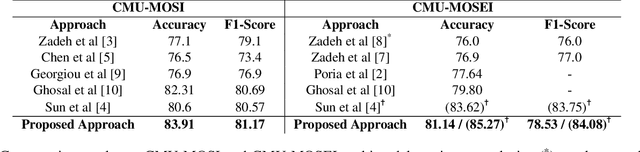
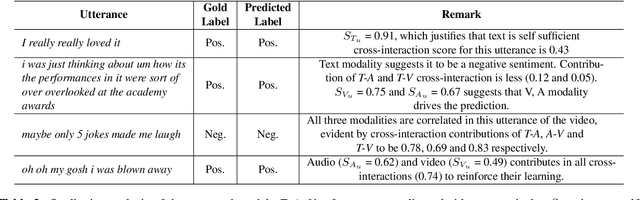
Multimodal sentiment analysis has recently gained popularity because of its relevance to social media posts, customer service calls and video blogs. In this paper, we address three aspects of multimodal sentiment analysis; 1. Cross modal interaction learning, i.e. how multiple modalities contribute to the sentiment, 2. Learning long-term dependencies in multimodal interactions and 3. Fusion of unimodal and cross modal cues. Out of these three, we find that learning cross modal interactions is beneficial for this problem. We perform experiments on two benchmark datasets, CMU Multimodal Opinion level Sentiment Intensity (CMU-MOSI) and CMU Multimodal Opinion Sentiment and Emotion Intensity (CMU-MOSEI) corpus. Our approach on both these tasks yields accuracies of 83.9% and 81.1% respectively, which is 1.6% and 1.34% absolute improvement over current state-of-the-art.