 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Pinterest Search Relevance Using Large Language Models
Oct 22, 2024



To improve relevance scoring on Pinterest Search, we integrate Large Language Models (LLMs) into our search relevance model, leveraging carefully designed text representations to predict the relevance of Pins effectively. Our approach uses search queries alongside content representations that include captions extracted from a generative visual language model. These are further enriched with link-based text data, historically high-quality engaged queries, user-curated boards, Pin titles and Pin descriptions, creating robust models for predicting search relevance. We use a semi-supervised learning approach to efficiently scale up the amount of training data, expanding beyond the expensive human labeled data available. By utilizing multilingual LLMs, our system extends training data to include unseen languages and domains, despite initial data and annotator expertise being confined to English. Furthermore, we distill from the LLM-based model into real-time servable model architectures and features. We provide comprehensive offline experimental validation for our proposed techniques and demonstrate the gains achieved through the final deployed system at scale.
What BERT Based Language Models Learn in Spoken Transcripts: An Empirical Study
Sep 21, 2021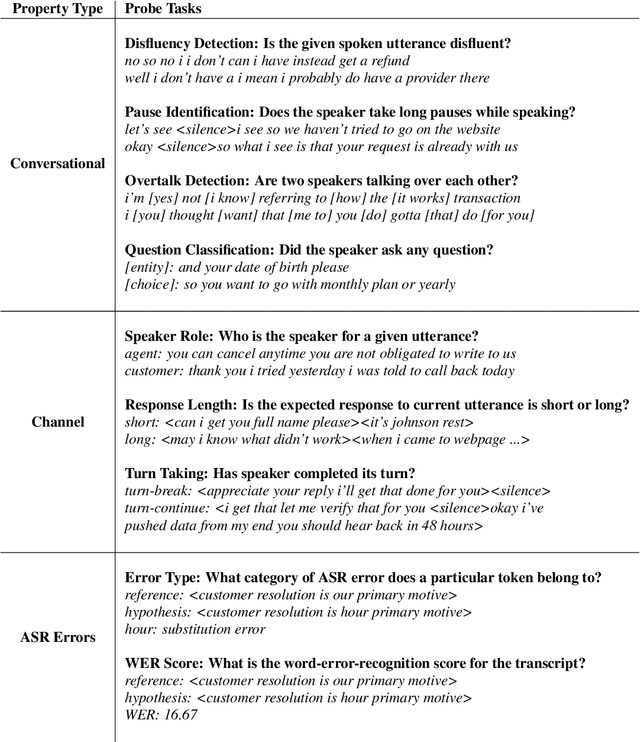
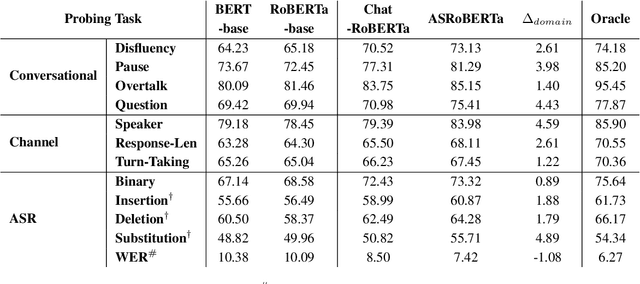


Language Models (LMs) have been ubiquitously leveraged in various tasks including spoken language understanding (SLU). Spoken language requires careful understanding of speaker interactions, dialog states and speech induced multimodal behaviors to generate a meaningful representation of the conversation. In this work, we propose to dissect SLU into three representative properties:conversational (disfluency, pause, overtalk), channel (speaker-type, turn-tasks) and ASR (insertion, deletion,substitution). We probe BERT based language models (BERT, RoBERTa) trained on spoken transcripts to investigate its ability to understand multifarious properties in absence of any speech cues. Empirical results indicate that LM is surprisingly good at capturing conversational properties such as pause prediction and overtalk detection from lexical tokens. On the downsides, the LM scores low on turn-tasks and ASR errors predictions. Additionally, pre-training the LM on spoken transcripts restrain its linguistic understanding. Finally, we establish the efficacy and transferability of the mentioned properties on two benchmark datasets: Switchboard Dialog Act and Disfluency datasets.
Phoneme-BERT: Joint Language Modelling of Phoneme Sequence and ASR Transcript
Feb 01, 2021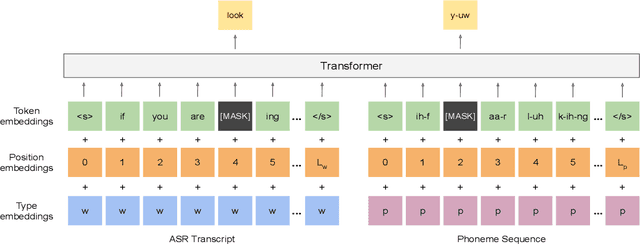
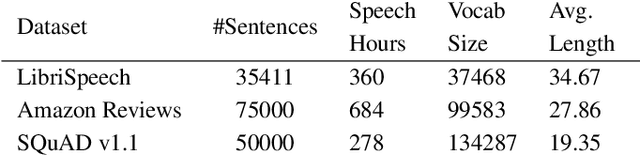

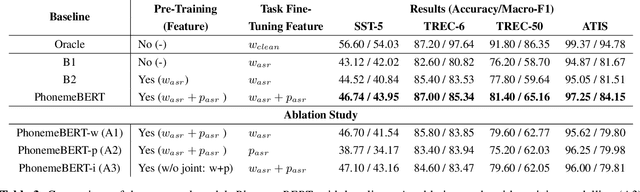
Recent years have witnessed significant improvement in ASR systems to recognize spoken utterances. However, it is still a challenging task for noisy and out-of-domain data, where substitution and deletion errors are prevalent in the transcribed text. These errors significantly degrade the performance of downstream tasks. In this work, we propose a BERT-style language model, referred to as PhonemeBERT, that learns a joint language model with phoneme sequence and ASR transcript to learn phonetic-aware representations that are robust to ASR errors. We show that PhonemeBERT can be used on downstream tasks using phoneme sequences as additional features, and also in low-resource setup where we only have ASR-transcripts for the downstream tasks with no phoneme information available. We evaluate our approach extensively by generating noisy data for three benchmark datasets - Stanford Sentiment Treebank, TREC and ATIS for sentiment, question and intent classification tasks respectively. The results of the proposed approach beats the state-of-the-art baselines comprehensively on each dataset.
Sentiment-Aware Recommendation System for Healthcare using Social Media
Sep 18, 2019



Over the last decade, health communities (known as forums) have evolved into platforms where more and more users share their medical experiences, thereby seeking guidance and interacting with people of the community. The shared content, though informal and unstructured in nature, contains valuable medical and/or health-related information and can be leveraged to produce structured suggestions to the common people. In this paper, at first we propose a stacked deep learning model for sentiment analysis from the medical forum data. The stacked model comprises of Convolutional Neural Network (CNN) followed by a Long Short Term Memory (LSTM) and then by another CNN. For a blog classified with positive sentiment, we retrieve the top-n similar posts. Thereafter, we develop a probabilistic model for suggesting the suitable treatments or procedures for a particular disease or health condition. We believe that integration of medical sentiment and suggestion would be beneficial to the users for finding the relevant contents regarding medications and medical conditions, without having to manually stroll through a large amount of unstructured contents.