 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Pinterest Search Relevance Using Large Language Models
Oct 22, 2024



To improve relevance scoring on Pinterest Search, we integrate Large Language Models (LLMs) into our search relevance model, leveraging carefully designed text representations to predict the relevance of Pins effectively. Our approach uses search queries alongside content representations that include captions extracted from a generative visual language model. These are further enriched with link-based text data, historically high-quality engaged queries, user-curated boards, Pin titles and Pin descriptions, creating robust models for predicting search relevance. We use a semi-supervised learning approach to efficiently scale up the amount of training data, expanding beyond the expensive human labeled data available. By utilizing multilingual LLMs, our system extends training data to include unseen languages and domains, despite initial data and annotator expertise being confined to English. Furthermore, we distill from the LLM-based model into real-time servable model architectures and features. We provide comprehensive offline experimental validation for our proposed techniques and demonstrate the gains achieved through the final deployed system at scale.
Deep Predictive Coding Networks
Mar 15, 2013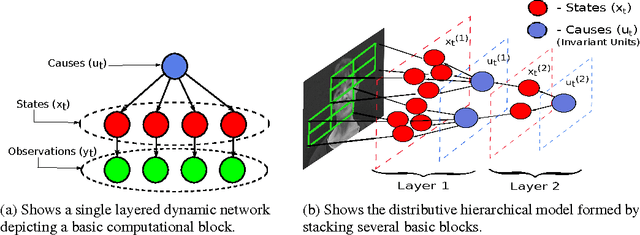

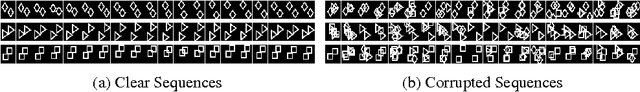
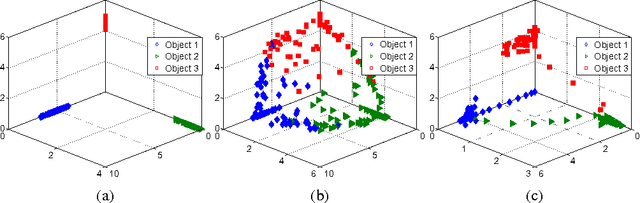
The quality of data representation in deep learning methods is directly related to the prior model imposed on the representations; however, generally used fixed priors are not capable of adjusting to the context in the data. To address this issue, we propose deep predictive coding networks, a hierarchical generative model that empirically alters priors on the latent representations in a dynamic and context-sensitive manner. This model captures the temporal dependencies in time-varying signals and uses top-down information to modulate the representation in lower layers. The centerpiece of our model is a novel procedure to infer sparse states of a dynamic model which is used for feature extraction. We also extend this feature extraction block to introduce a pooling function that captures locally invariant representations. When applied on a natural video data, we show that our method is able to learn high-level visual features. We also demonstrate the role of the top-down connections by showing the robustness of the proposed model to structured noise.