 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCorrSynth -- A Correlated Sampling Method for Diverse Dataset Generation from LLMs
Nov 13, 2024



Large language models (LLMs) have demonstrated remarkable performance in diverse tasks using zero-shot and few-shot prompting. Even though their capabilities of data synthesis have been studied well in recent years, the generated data suffers from a lack of diversity, less adherence to the prompt, and potential biases that creep into the data from the generator model. In this work, we tackle the challenge of generating datasets with high diversity, upon which a student model is trained for downstream tasks. Taking the route of decoding-time guidance-based approaches, we propose CorrSynth, which generates data that is more diverse and faithful to the input prompt using a correlated sampling strategy. Further, our method overcomes the complexity drawbacks of some other guidance-based techniques like classifier-based guidance. With extensive experiments, we show the effectiveness of our approach and substantiate our claims. In particular, we perform intrinsic evaluation to show the improvements in diversity. Our experiments show that CorrSynth improves both student metrics and intrinsic metrics upon competitive baselines across four datasets, showing the innate advantage of our method.
Exploring the Limits of Natural Language Inference Based Setup for Few-Shot Intent Detection
Dec 14, 2021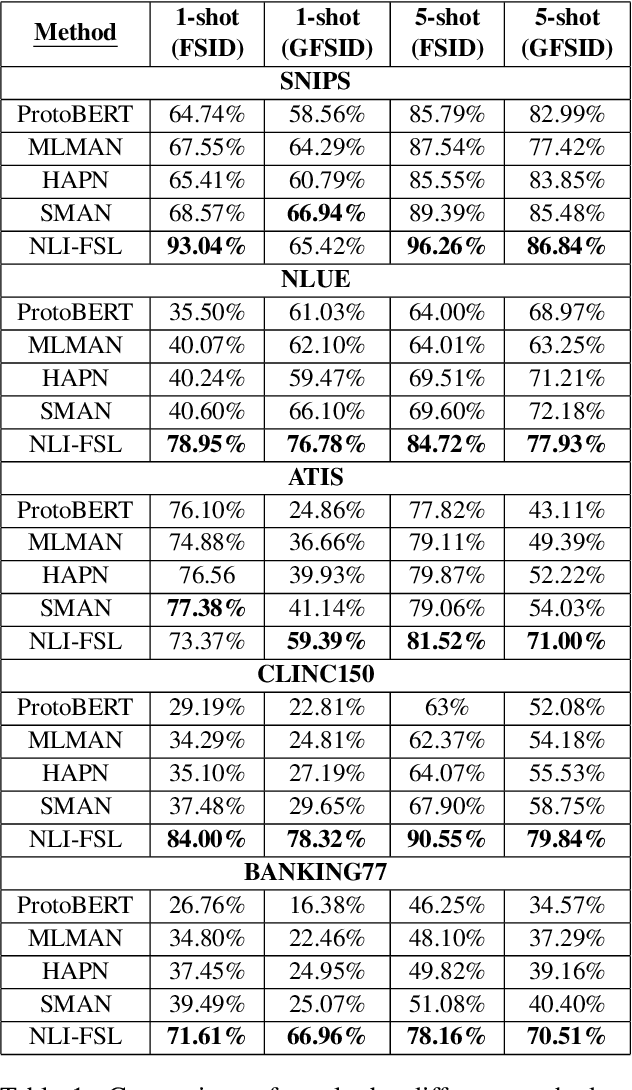

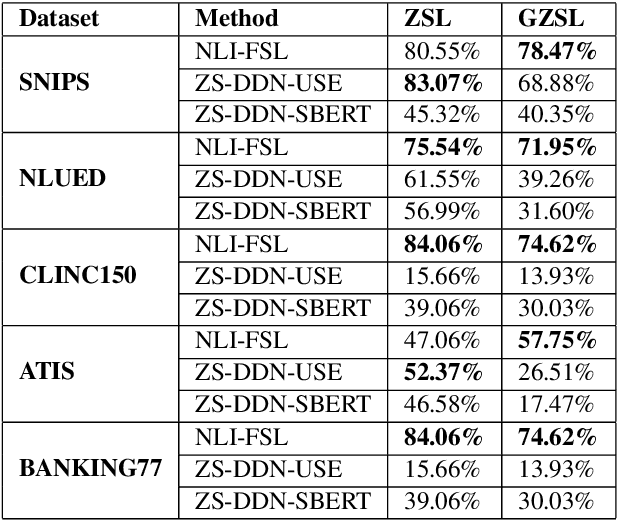

One of the core components of goal-oriented dialog systems is the task of Intent Detection. Few-shot Learning upon Intent Detection is challenging due to the scarcity of available annotated utterances. Although recent works making use of metric-based and optimization-based methods have been proposed, the task is still challenging in large label spaces and much smaller number of shots. Generalized Few-shot learning is more difficult due to the presence of both novel and seen classes during the testing phase. In this work, we propose a simple and effective method based on Natural Language Inference that not only tackles the problem of few shot intent detection, but also proves useful in zero-shot and generalized few shot learning problems. Our extensive experiments on a number of Natural Language Understanding (NLU) and Spoken Language Understanding (SLU) datasets show the effectiveness of our approach. In addition, we highlight the settings in which our NLI based method outperforms the baselines by huge margins.
Semantic Segmentation of Legal Documents via Rhetorical Roles
Dec 03, 2021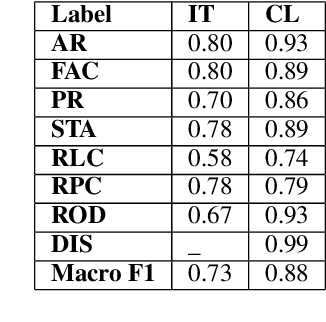
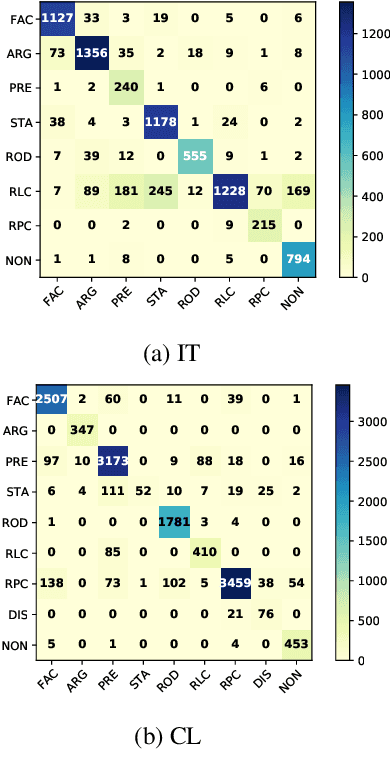
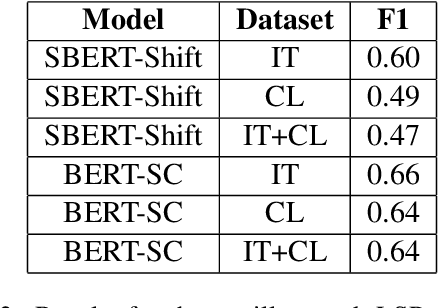
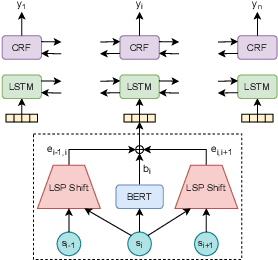
Legal documents are unstructured, use legal jargon, and have considerable length, making it difficult to process automatically via conventional text processing techniques. A legal document processing system would benefit substantially if the documents could be semantically segmented into coherent units of information. This paper proposes a Rhetorical Roles (RR) system for segmenting a legal document into semantically coherent units: facts, arguments, statute, issue, precedent, ruling, and ratio. With the help of legal experts, we propose a set of 13 fine-grained rhetorical role labels and create a new corpus of legal documents annotated with the proposed RR. We develop a system for segmenting a document into rhetorical role units. In particular, we develop a multitask learning-based deep learning model with document rhetorical role label shift as an auxiliary task for segmenting a legal document. We experiment extensively with various deep learning models for predicting rhetorical roles in a document, and the proposed model shows superior performance over the existing models. Further, we apply RR for predicting the judgment of legal cases and show that the use of RR enhances the prediction compared to the transformer-based models.
Socially Aware Bias Measurements for Hindi Language Representations
Oct 15, 2021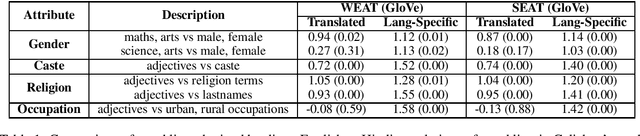
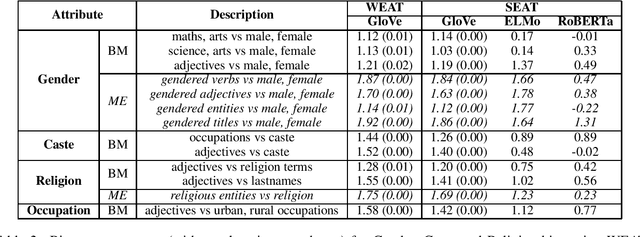
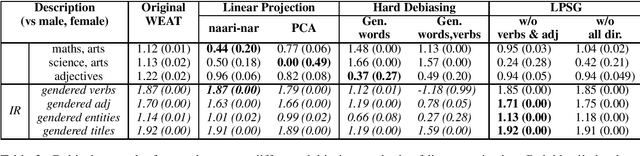
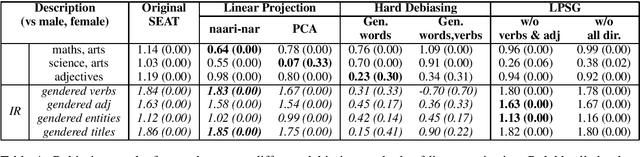
Language representations are an efficient tool used across NLP, but they are strife with encoded societal biases. These biases are studied extensively, but with a primary focus on English language representations and biases common in the context of Western society. In this work, we investigate the biases present in Hindi language representations such as caste and religion associated biases. We demonstrate how biases are unique to specific language representations based on the history and culture of the region they are widely spoken in, and also how the same societal bias (such as binary gender associated biases) when investigated across languages is encoded by different words and text spans. With this work, we emphasize on the necessity of social-awareness along with linguistic and grammatical artefacts when modeling language representations, in order to understand the biases encoded.
ILDC for CJPE: Indian Legal Documents Corpus for Court Judgment Prediction and Explanation
May 31, 2021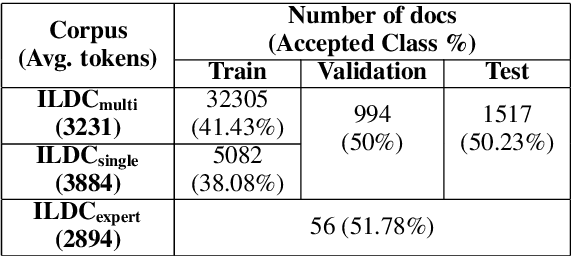
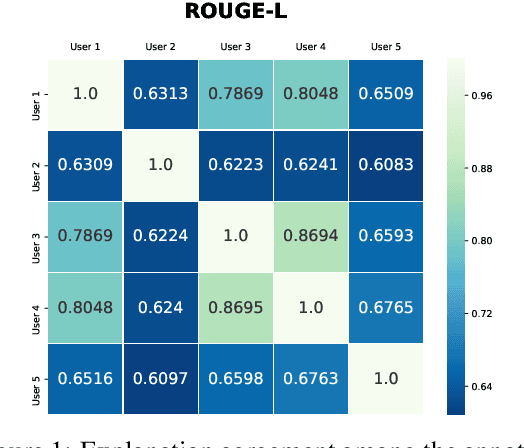

An automated system that could assist a judge in predicting the outcome of a case would help expedite the judicial process. For such a system to be practically useful, predictions by the system should be explainable. To promote research in developing such a system, we introduce ILDC (Indian Legal Documents Corpus). ILDC is a large corpus of 35k Indian Supreme Court cases annotated with original court decisions. A portion of the corpus (a separate test set) is annotated with gold standard explanations by legal experts. Based on ILDC, we propose the task of Court Judgment Prediction and Explanation (CJPE). The task requires an automated system to predict an explainable outcome of a case. We experiment with a battery of baseline models for case predictions and propose a hierarchical occlusion based model for explainability. Our best prediction model has an accuracy of 78% versus 94% for human legal experts, pointing towards the complexity of the prediction task. The analysis of explanations by the proposed algorithm reveals a significant difference in the point of view of the algorithm and legal experts for explaining the judgments, pointing towards scope for future research.
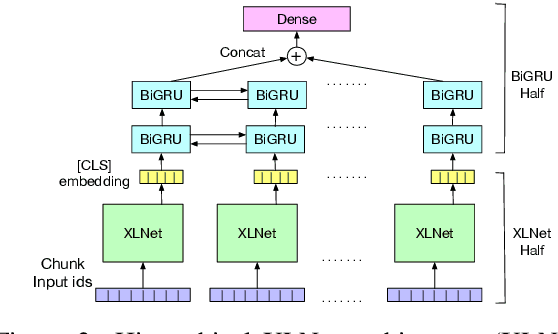
BreakingBERT@IITK at SemEval-2021 Task 9 : Statement Verification and Evidence Finding with Tables
Apr 10, 2021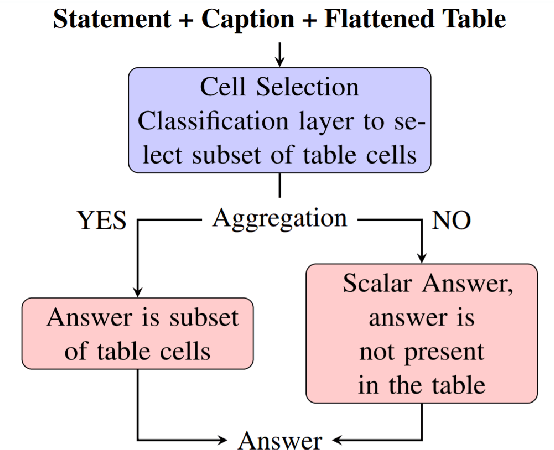
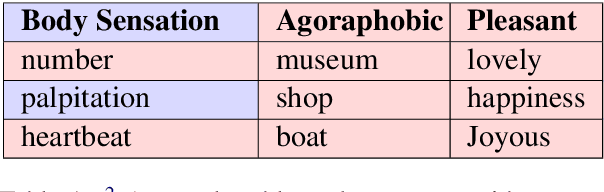

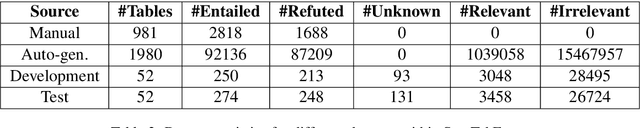
Recently, there has been an interest in factual verification and prediction over structured data like tables and graphs. To circumvent any false news incident, it is necessary to not only model and predict over structured data efficiently but also to explain those predictions. In this paper, as part of the SemEval-2021 Task 9, we tackle the problem of fact verification and evidence finding over tabular data. There are two subtasks. Given a table and a statement/fact, subtask A determines whether the statement is inferred from the tabular data, and subtask B determines which cells in the table provide evidence for the former subtask. We make a comparison of the baselines and state-of-the-art approaches over the given SemTabFact dataset. We also propose a novel approach CellBERT to solve evidence finding as a form of the Natural Language Inference task. We obtain a 3-way F1 score of 0.69 on subtask A and an F1 score of 0.65 on subtask B.
Adv-OLM: Generating Textual Adversaries via OLM
Jan 21, 2021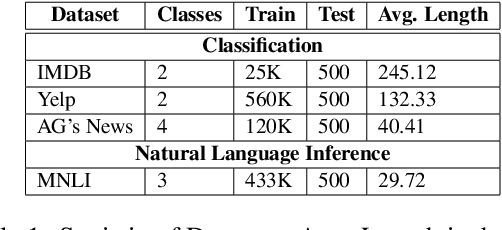
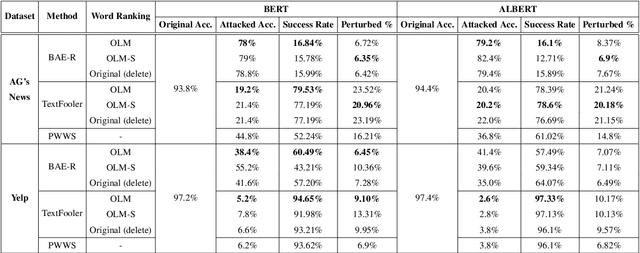
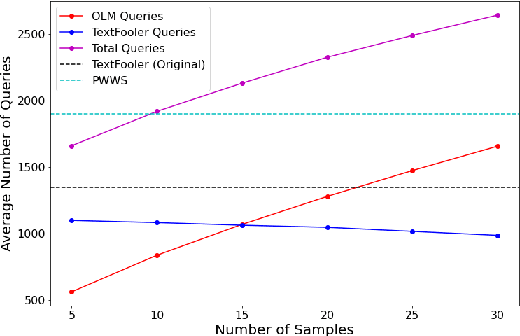
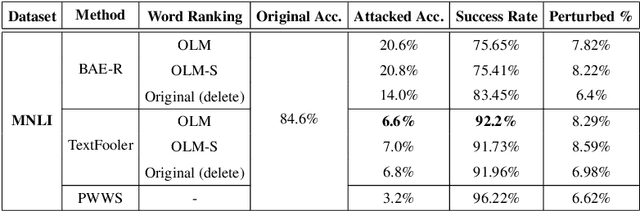
Deep learning models are susceptible to adversarial examples that have imperceptible perturbations in the original input, resulting in adversarial attacks against these models. Analysis of these attacks on the state of the art transformers in NLP can help improve the robustness of these models against such adversarial inputs. In this paper, we present Adv-OLM, a black-box attack method that adapts the idea of Occlusion and Language Models (OLM) to the current state of the art attack methods. OLM is used to rank words of a sentence, which are later substituted using word replacement strategies. We experimentally show that our approach outperforms other attack methods for several text classification tasks.