 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemantic Segmentation of Legal Documents via Rhetorical Roles
Dec 03, 2021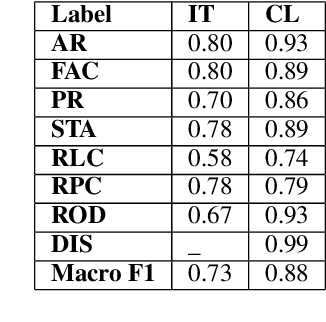
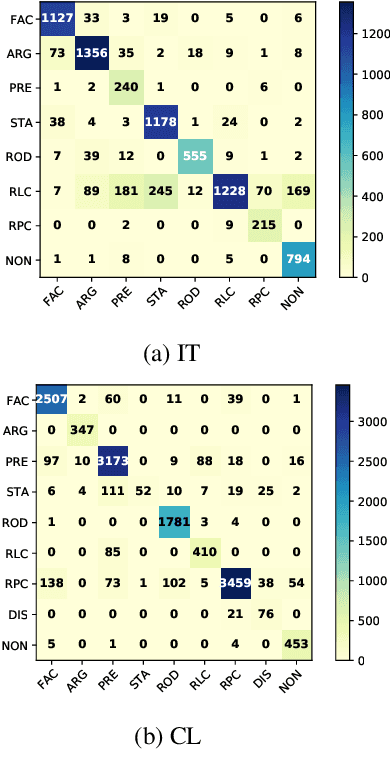
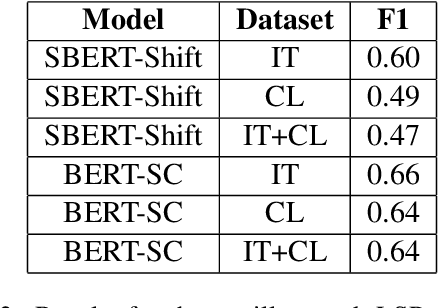
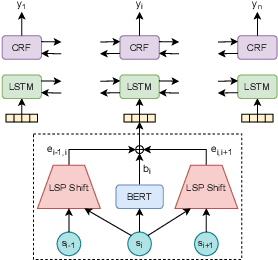
Legal documents are unstructured, use legal jargon, and have considerable length, making it difficult to process automatically via conventional text processing techniques. A legal document processing system would benefit substantially if the documents could be semantically segmented into coherent units of information. This paper proposes a Rhetorical Roles (RR) system for segmenting a legal document into semantically coherent units: facts, arguments, statute, issue, precedent, ruling, and ratio. With the help of legal experts, we propose a set of 13 fine-grained rhetorical role labels and create a new corpus of legal documents annotated with the proposed RR. We develop a system for segmenting a document into rhetorical role units. In particular, we develop a multitask learning-based deep learning model with document rhetorical role label shift as an auxiliary task for segmenting a legal document. We experiment extensively with various deep learning models for predicting rhetorical roles in a document, and the proposed model shows superior performance over the existing models. Further, we apply RR for predicting the judgment of legal cases and show that the use of RR enhances the prediction compared to the transformer-based models.