 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemantic Segmentation of Legal Documents via Rhetorical Roles
Dec 03, 2021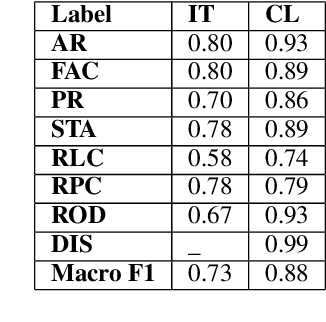
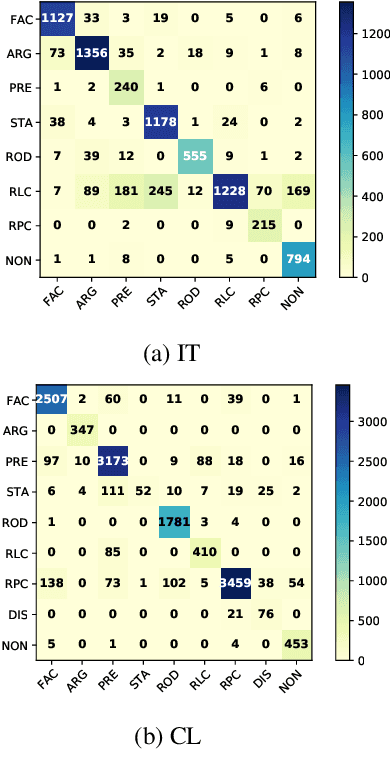
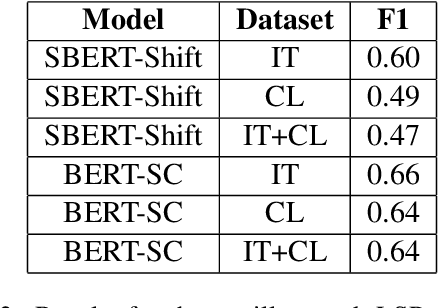
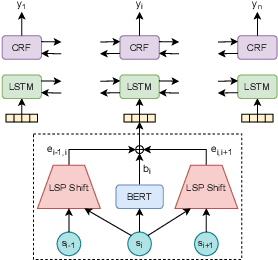
Legal documents are unstructured, use legal jargon, and have considerable length, making it difficult to process automatically via conventional text processing techniques. A legal document processing system would benefit substantially if the documents could be semantically segmented into coherent units of information. This paper proposes a Rhetorical Roles (RR) system for segmenting a legal document into semantically coherent units: facts, arguments, statute, issue, precedent, ruling, and ratio. With the help of legal experts, we propose a set of 13 fine-grained rhetorical role labels and create a new corpus of legal documents annotated with the proposed RR. We develop a system for segmenting a document into rhetorical role units. In particular, we develop a multitask learning-based deep learning model with document rhetorical role label shift as an auxiliary task for segmenting a legal document. We experiment extensively with various deep learning models for predicting rhetorical roles in a document, and the proposed model shows superior performance over the existing models. Further, we apply RR for predicting the judgment of legal cases and show that the use of RR enhances the prediction compared to the transformer-based models.
ILDC for CJPE: Indian Legal Documents Corpus for Court Judgment Prediction and Explanation
May 31, 2021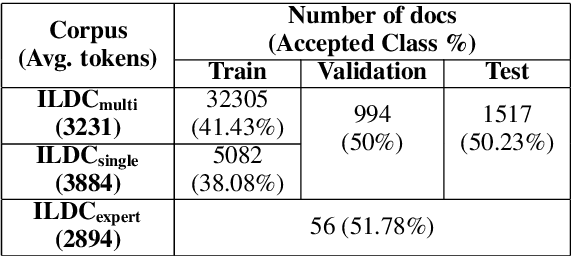
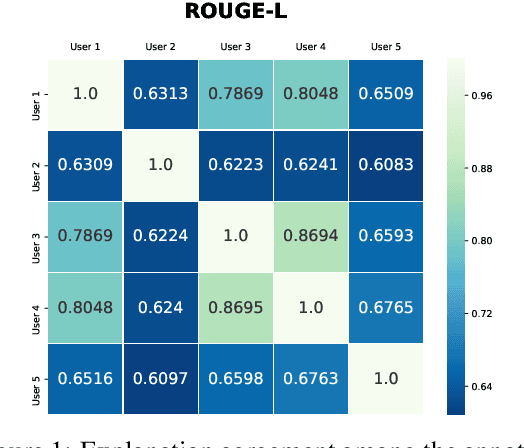
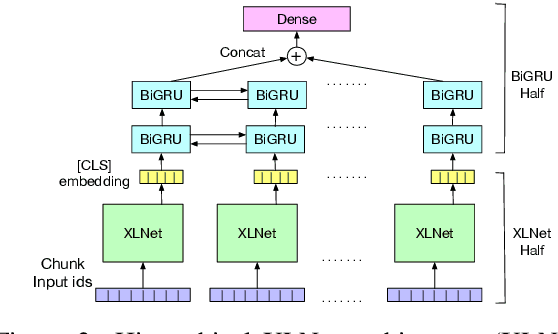

An automated system that could assist a judge in predicting the outcome of a case would help expedite the judicial process. For such a system to be practically useful, predictions by the system should be explainable. To promote research in developing such a system, we introduce ILDC (Indian Legal Documents Corpus). ILDC is a large corpus of 35k Indian Supreme Court cases annotated with original court decisions. A portion of the corpus (a separate test set) is annotated with gold standard explanations by legal experts. Based on ILDC, we propose the task of Court Judgment Prediction and Explanation (CJPE). The task requires an automated system to predict an explainable outcome of a case. We experiment with a battery of baseline models for case predictions and propose a hierarchical occlusion based model for explainability. Our best prediction model has an accuracy of 78% versus 94% for human legal experts, pointing towards the complexity of the prediction task. The analysis of explanations by the proposed algorithm reveals a significant difference in the point of view of the algorithm and legal experts for explaining the judgments, pointing towards scope for future research.