 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJuICE: A Benchmark for Evaluating LLM-Judge in Identifying Cultural Errors
May 26, 2026As large language models (LLMs) are increasingly deployed to users around the world, they are integrated into everyday tasks across diverse cultural contexts, from drafting personal communications to brainstorming creative ideas. These tasks are inherently cultural: they require contextual appropriateness, symbolic resonance, and tacit cultural expectations that native speakers draw on instinctively, meaning that a response can be factually plausible yet unmistakably wrong to a local reader. Existing cultural benchmarks have treated culture as a flat set of facts via fact verification or norm entailment methods, and have adopted LLM-as-a-Judge without examining whether they can capture such thick cultural errors. To address this gap, we present JuICE (Benchmark for LLM-Judge in Identifying Cultural Errors), a multilingual dataset of 7,470 span-level annotations of cultural and linguistic errors in long-form LLM responses. It covers 1,050 query-response pairs from four countries (the United States, South Korea, Indonesia, and Bangladesh), in both English and their countries' main languages. Using JuICE, we find that even the strongest LLM-judge achieves only an F1 of 0.52 in the erroneous span detection task. Furthermore, LLM-judges consistently miss thick cultural errors that local residents readily identify. Our findings suggest that robust cultural evaluation must move beyond surface-level detection toward frameworks that account for the depth and situatedness of cultural meaning.
Cultural Authenticity: Comparing LLM Cultural Representations to Native Human Expectations
Apr 03, 2026Cultural representation in Large Language Model (LLM) outputs has primarily been evaluated through the proxies of cultural diversity and factual accuracy. However, a crucial gap remains in assessing cultural alignment: the degree to which generated content mirrors how native populations perceive and prioritize their own cultural facets. In this paper, we introduce a human-centered framework to evaluate the alignment of LLM generations with local expectations. First, we establish a human-derived ground-truth baseline of importance vectors, called Cultural Importance Vectors based on an induced set of culturally significant facets from open-ended survey responses collected across nine countries. Next, we introduce a method to compute model-derived Cultural Representation Vectors of an LLM based on a syntactically diversified prompt-set and apply it to three frontier LLMs (Gemini 2.5 Pro, GPT-4o, and Claude 3.5 Haiku). Our investigation of the alignment between the human-derived Cultural Importance and model-derived Cultural Representations reveals a Western-centric calibration for some of the models where alignment decreases as a country's cultural distance from the US increases. Furthermore, we identify highly correlated, systemic error signatures ($ρ> 0.97$) across all models, which over-index on some cultural markers while neglecting the deep-seated social and value-based priorities of users. Our approach moves beyond simple diversity metrics toward evaluating the fidelity of AI-generated content in authentically capturing the nuanced hierarchies of global cultures.
A Unified Framework to Quantify Cultural Intelligence of AI
Mar 01, 2026As generative AI technologies are increasingly being launched across the globe, assessing their competence to operate in different cultural contexts is exigently becoming a priority. While recent years have seen numerous and much-needed efforts on cultural benchmarking, these efforts have largely focused on specific aspects of culture and evaluation. While these efforts contribute to our understanding of cultural competence, a unified and systematic evaluation approach is needed for us as a field to comprehensively assess diverse cultural dimensions at scale. Drawing on measurement theory, we present a principled framework to aggregate multifaceted indicators of cultural capabilities into a unified assessment of cultural intelligence. We start by developing a working definition of culture that includes identifying core domains of culture. We then introduce a broad-purpose, systematic, and extensible framework for assessing cultural intelligence of AI systems. Drawing on theoretical framing from psychometric measurement validity theory, we decouple the background concept (i.e., cultural intelligence) from its operationalization via measurement. We conceptualize cultural intelligence as a suite of core capabilities spanning diverse domains, which we then operationalize through a set of indicators designed for reliable measurement. Finally, we identify the considerations, challenges, and research pathways to meaningfully measure these indicators, specifically focusing on data collection, probing strategies, and evaluation metrics.
SAFARI: A Community-Engaged Approach and Dataset of Stereotype Resources in the Sub-Saharan African Context
Feb 25, 2026Stereotype repositories are critical to assess generative AI model safety, but currently lack adequate global coverage. It is imperative to prioritize targeted expansion, strategically addressing existing deficits, over merely increasing data volume. This work introduces a multilingual stereotype resource covering four sub-Saharan African countries that are severely underrepresented in NLP resources: Ghana, Kenya, Nigeria, and South Africa. By utilizing socioculturally-situated, community-engaged methods, including telephonic surveys moderated in native languages, we establish a reproducible methodology that is sensitive to the region's complex linguistic diversity and traditional orality. By deliberately balancing the sample across diverse ethnic and demographic backgrounds, we ensure broad coverage, resulting in a dataset of 3,534 stereotypes in English and 3,206 stereotypes across 15 native languages.
Cultural Compass: A Framework for Organizing Societal Norms to Detect Violations in Human-AI Conversations
Jan 12, 2026Generative AI models ought to be useful and safe across cross-cultural contexts. One critical step toward this goal is understanding how AI models adhere to sociocultural norms. While this challenge has gained attention in NLP, existing work lacks both nuance and coverage in understanding and evaluating models' norm adherence. We address these gaps by introducing a taxonomy of norms that clarifies their contexts (e.g., distinguishing between human-human norms that models should recognize and human-AI interactional norms that apply to the human-AI interaction itself), specifications (e.g., relevant domains), and mechanisms (e.g., modes of enforcement). We demonstrate how our taxonomy can be operationalized to automatically evaluate models' norm adherence in naturalistic, open-ended settings. Our exploratory analyses suggest that state-of-the-art models frequently violate norms, though violation rates vary by model, interactional context, and country. We further show that violation rates also vary by prompt intent and situational framing. Our taxonomy and demonstrative evaluation pipeline enable nuanced, context-sensitive evaluation of cultural norm adherence in realistic settings.
Towards Geo-Culturally Grounded LLM Generations
Feb 20, 2025Generative large language models (LLMs) have been demonstrated to have gaps in diverse, cultural knowledge across the globe. We investigate the effect of retrieval augmented generation and search-grounding techniques on the ability of LLMs to display familiarity with a diverse range of national cultures. Specifically, we compare the performance of standard LLMs, LLMs augmented with retrievals from a bespoke knowledge base (i.e., KB grounding), and LLMs augmented with retrievals from a web search (i.e., search grounding) on a series of cultural familiarity benchmarks. We find that search grounding significantly improves the LLM performance on multiple-choice benchmarks that test propositional knowledge (e.g., the norms, artifacts, and institutions of national cultures), while KB grounding's effectiveness is limited by inadequate knowledge base coverage and a suboptimal retriever. However, search grounding also increases the risk of stereotypical judgments by language models, while failing to improve evaluators' judgments of cultural familiarity in a human evaluation with adequate statistical power. These results highlight the distinction between propositional knowledge about a culture and open-ended cultural fluency when it comes to evaluating the cultural familiarity of generative LLMs.
MisgenderMender: A Community-Informed Approach to Interventions for Misgendering
Apr 23, 2024

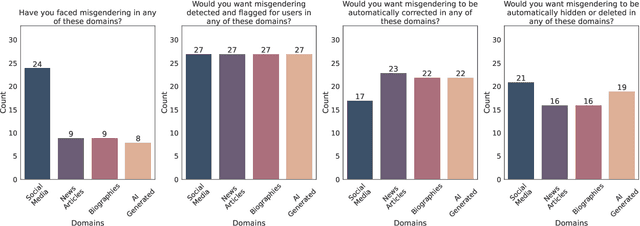

Content Warning: This paper contains examples of misgendering and erasure that could be offensive and potentially triggering. Misgendering, the act of incorrectly addressing someone's gender, inflicts serious harm and is pervasive in everyday technologies, yet there is a notable lack of research to combat it. We are the first to address this lack of research into interventions for misgendering by conducting a survey of gender-diverse individuals in the US to understand perspectives about automated interventions for text-based misgendering. Based on survey insights on the prevalence of misgendering, desired solutions, and associated concerns, we introduce a misgendering interventions task and evaluation dataset, MisgenderMender. We define the task with two sub-tasks: (i) detecting misgendering, followed by (ii) correcting misgendering where misgendering is present in domains where editing is appropriate. MisgenderMender comprises 3790 instances of social media content and LLM-generations about non-cisgender public figures, annotated for the presence of misgendering, with additional annotations for correcting misgendering in LLM-generated text. Using this dataset, we set initial benchmarks by evaluating existing NLP systems and highlighting challenges for future models to address. We release the full dataset, code, and demo at https://tamannahossainkay.github.io/misgendermender/.
GeniL: A Multilingual Dataset on Generalizing Language
Apr 08, 2024



LLMs are increasingly transforming our digital ecosystem, but they often inherit societal biases learned from their training data, for instance stereotypes associating certain attributes with specific identity groups. While whether and how these biases are mitigated may depend on the specific use cases, being able to effectively detect instances of stereotype perpetuation is a crucial first step. Current methods to assess presence of stereotypes in generated language rely on simple template or co-occurrence based measures, without accounting for the variety of sentential contexts they manifest in. We argue that understanding the sentential context is crucial for detecting instances of generalization. We distinguish two types of generalizations: (1) language that merely mentions the presence of a generalization ("people think the French are very rude"), and (2) language that reinforces such a generalization ("as French they must be rude"), from non-generalizing context ("My French friends think I am rude"). For meaningful stereotype evaluations, we need to reliably distinguish such instances of generalizations. We introduce the new task of detecting generalization in language, and build GeniL, a multilingual dataset of over 50K sentences from 9 languages (English, Arabic, Bengali, Spanish, French, Hindi, Indonesian, Malay, and Portuguese) annotated for instances of generalizations. We demonstrate that the likelihood of a co-occurrence being an instance of generalization is usually low, and varies across different languages, identity groups, and attributes. We build classifiers to detect generalization in language with an overall PR-AUC of 58.7, with varying degrees of performance across languages. Our research provides data and tools to enable a nuanced understanding of stereotype perpetuation, a crucial step towards more inclusive and responsible language technologies.
SeeGULL Multilingual: a Dataset of Geo-Culturally Situated Stereotypes
Mar 08, 2024



While generative multilingual models are rapidly being deployed, their safety and fairness evaluations are largely limited to resources collected in English. This is especially problematic for evaluations targeting inherently socio-cultural phenomena such as stereotyping, where it is important to build multi-lingual resources that reflect the stereotypes prevalent in respective language communities. However, gathering these resources, at scale, in varied languages and regions pose a significant challenge as it requires broad socio-cultural knowledge and can also be prohibitively expensive. To overcome this critical gap, we employ a recently introduced approach that couples LLM generations for scale with culturally situated validations for reliability, and build SeeGULL Multilingual, a global-scale multilingual dataset of social stereotypes, containing over 25K stereotypes, spanning 20 languages, with human annotations across 23 regions, and demonstrate its utility in identifying gaps in model evaluations. Content warning: Stereotypes shared in this paper can be offensive.
MiTTenS: A Dataset for Evaluating Misgendering in Translation
Jan 13, 2024



Misgendering is the act of referring to someone in a way that does not reflect their gender identity. Translation systems, including foundation models capable of translation, can produce errors that result in misgendering harms. To measure the extent of such potential harms when translating into and out of English, we introduce a dataset, MiTTenS, covering 26 languages from a variety of language families and scripts, including several traditionally underpresented in digital resources. The dataset is constructed with handcrafted passages that target known failure patterns, longer synthetically generated passages, and natural passages sourced from multiple domains. We demonstrate the usefulness of the dataset by evaluating both dedicated neural machine translation systems and foundation models, and show that all systems exhibit errors resulting in misgendering harms, even in high resource languages.