 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSYMBIOSIS: Systems Thinking and Machine Intelligence for Better Outcomes in Society
Mar 07, 2025This paper presents SYMBIOSIS, an AI-powered framework and platform designed to make Systems Thinking accessible for addressing societal challenges and unlock paths for leveraging systems thinking frameworks to improve AI systems. The platform establishes a centralized, open-source repository of systems thinking/system dynamics models categorized by Sustainable Development Goals (SDGs) and societal topics using topic modeling and classification techniques. Systems Thinking resources, though critical for articulating causal theories in complex problem spaces, are often locked behind specialized tools and intricate notations, creating high barriers to entry. To address this, we developed a generative co-pilot that translates complex systems representations - such as causal loop and stock-flow diagrams - into natural language (and vice-versa), allowing users to explore and build models without extensive technical training. Rooted in community-based system dynamics (CBSD) and informed by community-driven insights on societal context, we aim to bridge the problem understanding chasm. This gap, driven by epistemic uncertainty, often limits ML developers who lack the community-specific knowledge essential for problem understanding and formulation, often leading to ill informed causal assumptions, reduced intervention effectiveness and harmful biases. Recent research identifies causal and abductive reasoning as crucial frontiers for AI, and Systems Thinking provides a naturally compatible framework for both. By making Systems Thinking frameworks more accessible and user-friendly, SYMBIOSIS aims to serve as a foundational step to unlock future research into responsible and society-centered AI. Our work underscores the need for ongoing research into AI's capacity to understand essential characteristics of complex adaptive systems paving the way for more socially attuned, effective AI systems.
Towards Geo-Culturally Grounded LLM Generations
Feb 20, 2025Generative large language models (LLMs) have been demonstrated to have gaps in diverse, cultural knowledge across the globe. We investigate the effect of retrieval augmented generation and search-grounding techniques on the ability of LLMs to display familiarity with a diverse range of national cultures. Specifically, we compare the performance of standard LLMs, LLMs augmented with retrievals from a bespoke knowledge base (i.e., KB grounding), and LLMs augmented with retrievals from a web search (i.e., search grounding) on a series of cultural familiarity benchmarks. We find that search grounding significantly improves the LLM performance on multiple-choice benchmarks that test propositional knowledge (e.g., the norms, artifacts, and institutions of national cultures), while KB grounding's effectiveness is limited by inadequate knowledge base coverage and a suboptimal retriever. However, search grounding also increases the risk of stereotypical judgments by language models, while failing to improve evaluators' judgments of cultural familiarity in a human evaluation with adequate statistical power. These results highlight the distinction between propositional knowledge about a culture and open-ended cultural fluency when it comes to evaluating the cultural familiarity of generative LLMs.
Advancing Community Engaged Approaches to Identifying Structural Drivers of Racial Bias in Health Diagnostic Algorithms
May 22, 2023Much attention and concern has been raised recently about bias and the use of machine learning algorithms in healthcare, especially as it relates to perpetuating racial discrimination and health disparities. Following an initial system dynamics workshop at the Data for Black Lives II conference hosted at MIT in January of 2019, a group of conference participants interested in building capabilities to use system dynamics to understand complex societal issues convened monthly to explore issues related to racial bias in AI and implications for health disparities through qualitative and simulation modeling. In this paper we present results and insights from the modeling process and highlight the importance of centering the discussion of data and healthcare on people and their experiences with healthcare and science, and recognizing the societal context where the algorithm is operating. Collective memory of community trauma, through deaths attributed to poor healthcare, and negative experiences with healthcare are endogenous drivers of seeking treatment and experiencing effective care, which impact the availability and quality of data for algorithms. These drivers have drastically disparate initial conditions for different racial groups and point to limited impact of focusing solely on improving diagnostic algorithms for achieving better health outcomes for some groups.
Extending the Machine Learning Abstraction Boundary: A Complex Systems Approach to Incorporate Societal Context
Jun 17, 2020

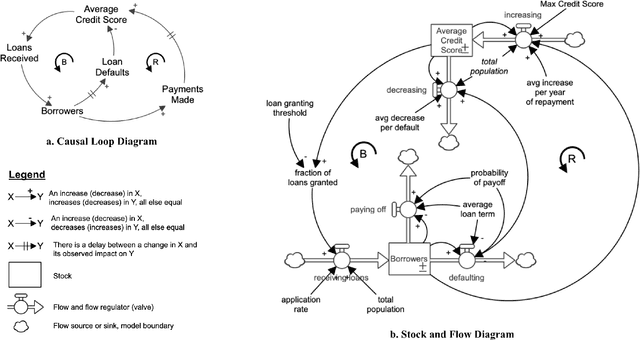
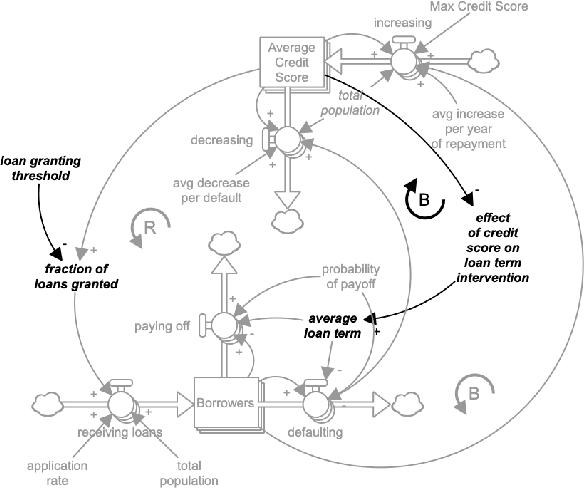
Machine learning (ML) fairness research tends to focus primarily on mathematically-based interventions on often opaque algorithms or models and/or their immediate inputs and outputs. Such oversimplified mathematical models abstract away the underlying societal context where ML models are conceived, developed, and ultimately deployed. As fairness itself is a socially constructed concept that originates from that societal context along with the model inputs and the models themselves, a lack of an in-depth understanding of societal context can easily undermine the pursuit of ML fairness. In this paper, we outline three new tools to improve the comprehension, identification and representation of societal context. First, we propose a complex adaptive systems (CAS) based model and definition of societal context that will help researchers and product developers to expand the abstraction boundary of ML fairness work to include societal context. Second, we introduce collaborative causal theory formation (CCTF) as a key capability for establishing a sociotechnical frame that incorporates diverse mental models and associated causal theories in modeling the problem and solution space for ML-based products. Finally, we identify community based system dynamics (CBSD) as a powerful, transparent and rigorous approach for practicing CCTF during all phases of the ML product development process. We conclude with a discussion of how these systems theoretic approaches to understand the societal context within which sociotechnical systems are embedded can improve the development of fair and inclusive ML-based products.
Participatory Problem Formulation for Fairer Machine Learning Through Community Based System Dynamics
May 22, 2020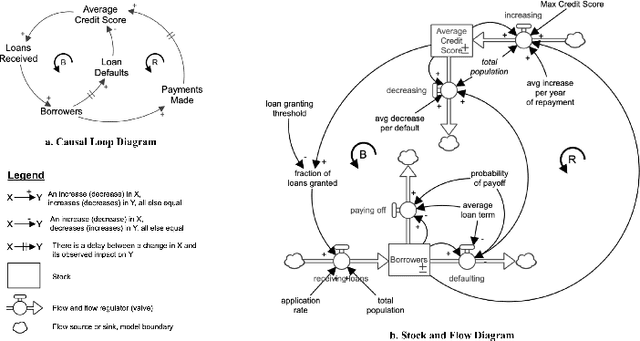
Recent research on algorithmic fairness has highlighted that the problem formulation phase of ML system development can be a key source of bias that has significant downstream impacts on ML system fairness outcomes. However, very little attention has been paid to methods for improving the fairness efficacy of this critical phase of ML system development. Current practice neither accounts for the dynamic complexity of high-stakes domains nor incorporates the perspectives of vulnerable stakeholders. In this paper we introduce community based system dynamics (CBSD) as an approach to enable the participation of typically excluded stakeholders in the problem formulation phase of the ML system development process and facilitate the deep problem understanding required to mitigate bias during this crucial stage.