 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAggregating Concepts of Accuracy and Fairness in Prediction Algorithms
May 15, 2025An algorithm that outputs predictions about the state of the world will almost always be designed with the implicit or explicit goal of outputting accurate predictions (i.e., predictions that are likely to be true). In addition, the rise of increasingly powerful predictive algorithms brought about by the recent revolution in artificial intelligence has led to an emphasis on building predictive algorithms that are fair, in the sense that their predictions do not systematically evince bias or bring about harm to certain individuals or groups. This state of affairs presents two conceptual challenges. First, the goals of accuracy and fairness can sometimes be in tension, and there are no obvious normative guidelines for managing the trade-offs between these two desiderata when they arise. Second, there are many distinct ways of measuring both the accuracy and fairness of a predictive algorithm; here too, there are no obvious guidelines on how to aggregate our preferences for predictive algorithms that satisfy disparate measures of fairness and accuracy to various extents. The goal of this paper is to address these challenges by arguing that there are good reasons for using a linear combination of accuracy and fairness metrics to measure the all-things-considered value of a predictive algorithm for agents who care about both accuracy and fairness. My argument depends crucially on a classic result in the preference aggregation literature due to Harsanyi. After making this formal argument, I apply my result to an analysis of accuracy-fairness trade-offs using the COMPAS dataset compiled by Angwin et al.
Towards Geo-Culturally Grounded LLM Generations
Feb 20, 2025Generative large language models (LLMs) have been demonstrated to have gaps in diverse, cultural knowledge across the globe. We investigate the effect of retrieval augmented generation and search-grounding techniques on the ability of LLMs to display familiarity with a diverse range of national cultures. Specifically, we compare the performance of standard LLMs, LLMs augmented with retrievals from a bespoke knowledge base (i.e., KB grounding), and LLMs augmented with retrievals from a web search (i.e., search grounding) on a series of cultural familiarity benchmarks. We find that search grounding significantly improves the LLM performance on multiple-choice benchmarks that test propositional knowledge (e.g., the norms, artifacts, and institutions of national cultures), while KB grounding's effectiveness is limited by inadequate knowledge base coverage and a suboptimal retriever. However, search grounding also increases the risk of stereotypical judgments by language models, while failing to improve evaluators' judgments of cultural familiarity in a human evaluation with adequate statistical power. These results highlight the distinction between propositional knowledge about a culture and open-ended cultural fluency when it comes to evaluating the cultural familiarity of generative LLMs.
Causal Theories and Structural Data Representations for Improving Out-of-Distribution Classification
Sep 18, 2023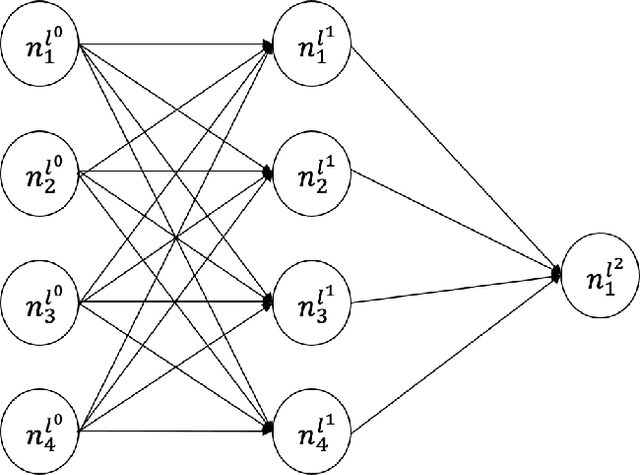
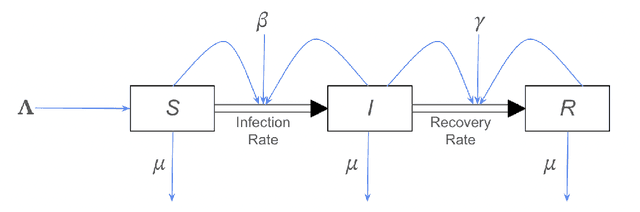
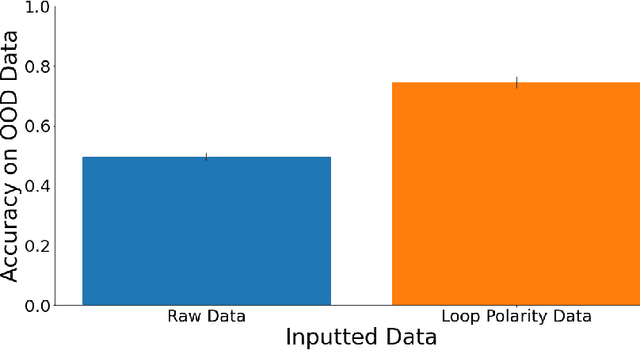
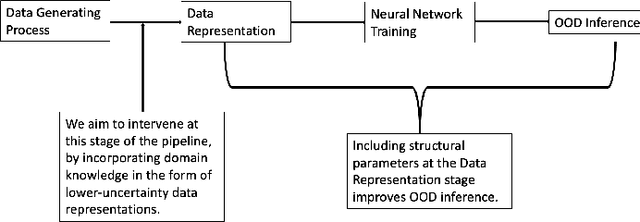
We consider how human-centered causal theories and tools from the dynamical systems literature can be deployed to guide the representation of data when training neural networks for complex classification tasks. Specifically, we use simulated data to show that training a neural network with a data representation that makes explicit the invariant structural causal features of the data generating process of an epidemic system improves out-of-distribution (OOD) generalization performance on a classification task as compared to a more naive approach to data representation. We take these results to demonstrate that using human-generated causal knowledge to reduce the epistemic uncertainty of ML developers can lead to more well-specified ML pipelines. This, in turn, points to the utility of a dynamical systems approach to the broader effort aimed at improving the robustness and safety of machine learning systems via improved ML system development practices.
Causal Feature Learning for Utility-Maximizing Agents
Jun 06, 2020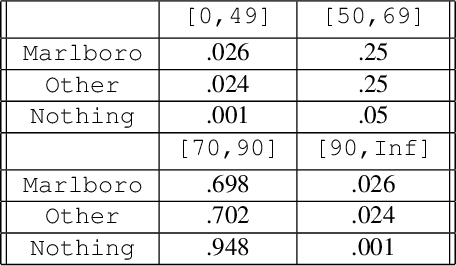
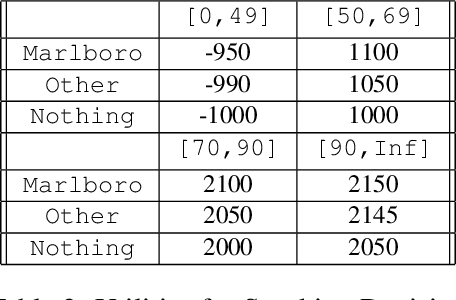

Discovering high-level causal relations from low-level data is an important and challenging problem that comes up frequently in the natural and social sciences. In a series of papers, Chalupka et al. (2015, 2016a, 2016b, 2017) develop a procedure for causal feature learning (CFL) in an effort to automate this task. We argue that CFL does not recommend coarsening in cases where pragmatic considerations rule in favor of it, and recommends coarsening in cases where pragmatic considerations rule against it. We propose a new technique, pragmatic causal feature learning (PCFL), which extends the original CFL algorithm in useful and intuitive ways. We show that PCFL has the same attractive measure-theoretic properties as the original CFL algorithm. We compare the performance of both methods through theoretical analysis and experiments.