 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat Kind of Reasoning (if any) is an LLM actually doing? On the Stochastic Nature and Abductive Appearance of Large Language Models
Dec 10, 2025This article looks at how reasoning works in current Large Language Models (LLMs) that function using the token-completion method. It examines their stochastic nature and their similarity to human abductive reasoning. The argument is that these LLMs create text based on learned patterns rather than performing actual abductive reasoning. When their output seems abductive, this is largely because they are trained on human-generated texts that include reasoning structures. Examples are used to show how LLMs can produce plausible ideas, mimic commonsense reasoning, and give explanatory answers without being grounded in truth, semantics, verification, or understanding, and without performing any real abductive reasoning. This dual nature, where the models have a stochastic base but appear abductive in use, has important consequences for how LLMs are evaluated and applied. They can assist with generating ideas and supporting human thinking, but their outputs must be critically assessed because they cannot identify truth or verify their explanations. The article concludes by addressing five objections to these points, noting some limitations in the analysis, and offering an overall evaluation.
Multi-omic Causal Discovery using Genotypes and Gene Expression
May 21, 2025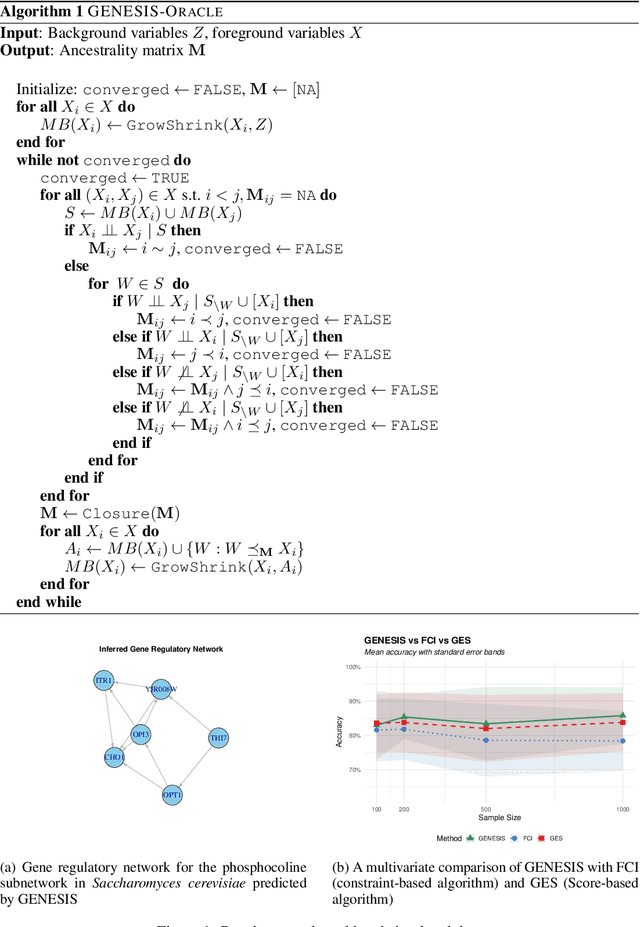
Causal discovery in multi-omic datasets is crucial for understanding the bigger picture of gene regulatory mechanisms, but remains challenging due to high dimensionality, differentiation of direct from indirect relationships, and hidden confounders. We introduce GENESIS (GEne Network inference from Expression SIgnals and SNPs), a constraint-based algorithm that leverages the natural causal precedence of genotypes to infer ancestral relationships in transcriptomic data. Unlike traditional causal discovery methods that start with a fully connected graph, GENESIS initialises an empty ancestrality matrix and iteratively populates it with direct, indirect or non-causal relationships using a series of provably sound marginal and conditional independence tests. By integrating genotypes as fixed causal anchors, GENESIS provides a principled ``head start'' to classical causal discovery algorithms, restricting the search space to biologically plausible edges. We test GENESIS on synthetic and real-world genomic datasets. This framework offers a powerful avenue for uncovering causal pathways in complex traits, with promising applications to functional genomics, drug discovery, and precision medicine.
The Switch, the Ladder, and the Matrix: Models for Classifying AI Systems
Jul 07, 2024Organisations that design and deploy artificial intelligence (AI) systems increasingly commit themselves to high-level, ethical principles. However, there still exists a gap between principles and practices in AI ethics. One major obstacle organisations face when attempting to operationalise AI Ethics is the lack of a well-defined material scope. Put differently, the question to which systems and processes AI ethics principles ought to apply remains unanswered. Of course, there exists no universally accepted definition of AI, and different systems pose different ethical challenges. Nevertheless, pragmatic problem-solving demands that things should be sorted so that their grouping will promote successful actions for some specific end. In this article, we review and compare previous attempts to classify AI systems for the purpose of implementing AI governance in practice. We find that attempts to classify AI systems found in previous literature use one of three mental model. The Switch, i.e., a binary approach according to which systems either are or are not considered AI systems depending on their characteristics. The Ladder, i.e., a risk-based approach that classifies systems according to the ethical risks they pose. And the Matrix, i.e., a multi-dimensional classification of systems that take various aspects into account, such as context, data input, and decision-model. Each of these models for classifying AI systems comes with its own set of strengths and weaknesses. By conceptualising different ways of classifying AI systems into simple mental models, we hope to provide organisations that design, deploy, or regulate AI systems with the conceptual tools needed to operationalise AI governance in practice.
The US Algorithmic Accountability Act of 2022 vs. The EU Artificial Intelligence Act: What can they learn from each other?
Jul 07, 2024On the whole, the U.S. Algorithmic Accountability Act of 2022 (US AAA) is a pragmatic approach to balancing the benefits and risks of automated decision systems. Yet there is still room for improvement. This commentary highlights how the US AAA can both inform and learn from the European Artificial Intelligence Act (EU AIA).
Causal discovery under a confounder blanket
May 11, 2022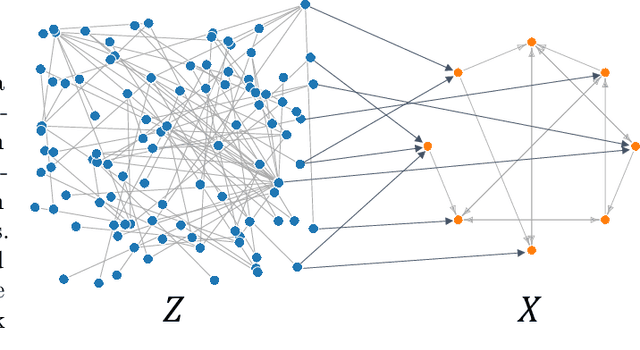
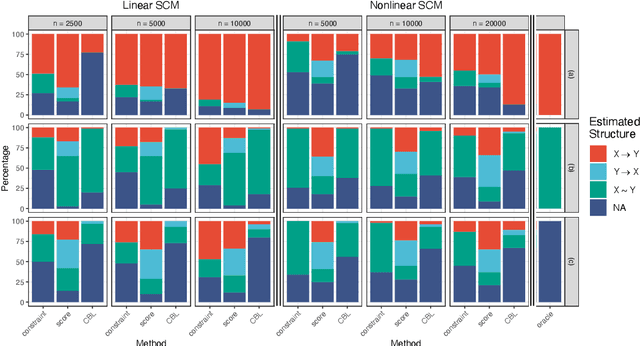
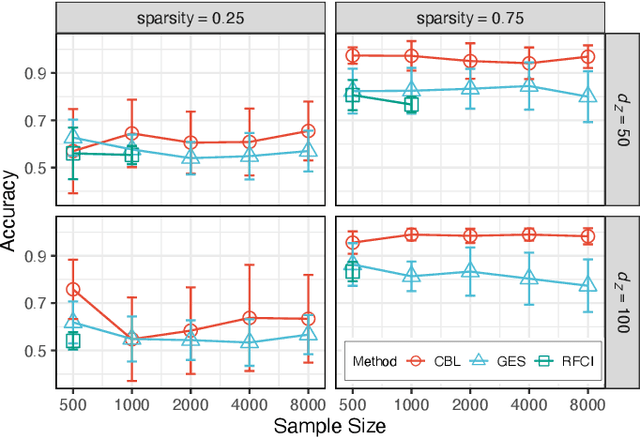

Inferring causal relationships from observational data is rarely straightforward, but the problem is especially difficult in high dimensions. For these applications, causal discovery algorithms typically require parametric restrictions or extreme sparsity constraints. We relax these assumptions and focus on an important but more specialized problem, namely recovering a directed acyclic subgraph of variables known to be causally descended from some (possibly large) set of confounding covariates, i.e. a $\textit{confounder blanket}$. This is useful in many settings, for example when studying a dynamic biomolecular subsystem with genetic data providing causally relevant background information. Under a structural assumption that, we argue, must be satisfied in practice if informative answers are to be found, our method accommodates graphs of low or high sparsity while maintaining polynomial time complexity. We derive a sound and complete algorithm for identifying causal relationships under these conditions and implement testing procedures with provable error control for linear and nonlinear systems. We demonstrate our approach on a range of simulation settings.
Stochastic Causal Programming for Bounding Treatment Effects
Feb 22, 2022
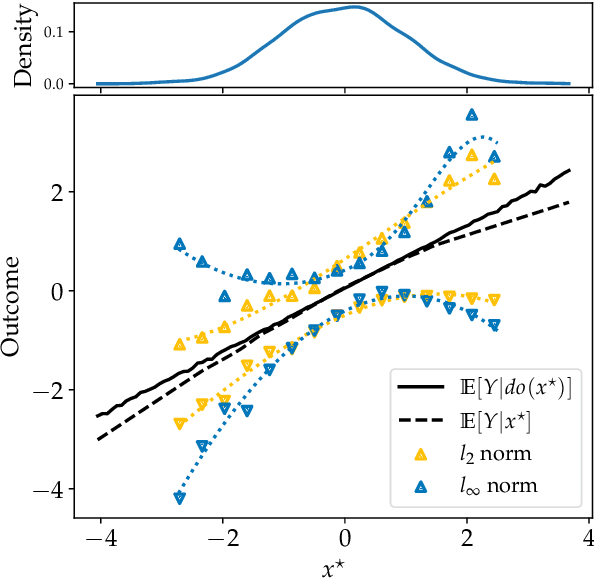
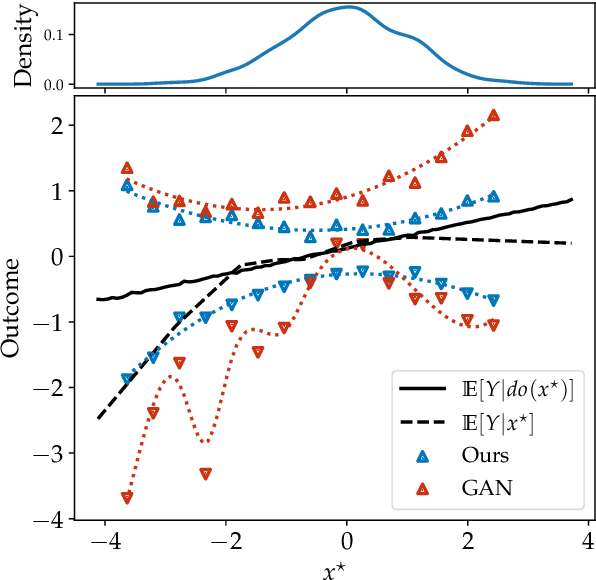
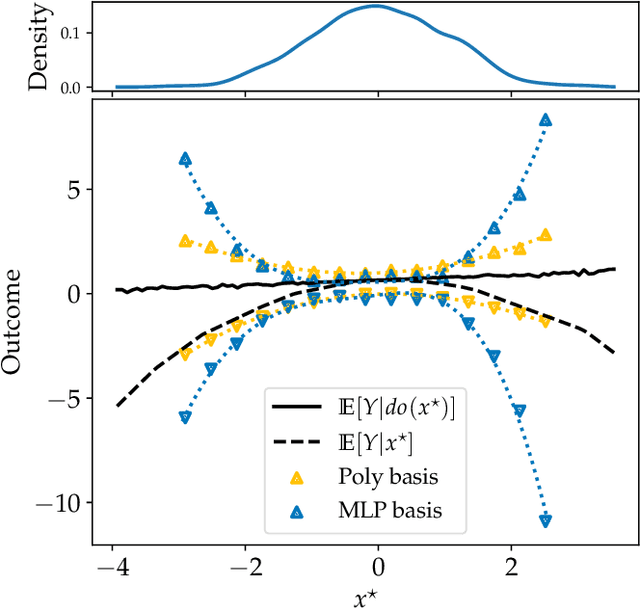
Causal effect estimation is important for numerous tasks in the natural and social sciences. However, identifying effects is impossible from observational data without making strong, often untestable assumptions. We consider algorithms for the partial identification problem, bounding treatment effects from multivariate, continuous treatments over multiple possible causal models when unmeasured confounding makes identification impossible. We consider a framework where observable evidence is matched to the implications of constraints encoded in a causal model by norm-based criteria. This generalizes classical approaches based purely on generative models. Casting causal effects as objective functions in a constrained optimization problem, we combine flexible learning algorithms with Monte Carlo methods to implement a family of solutions under the name of stochastic causal programming. In particular, we present ways by which such constrained optimization problems can be parameterized without likelihood functions for the causal or the observed data model, reducing the computational and statistical complexity of the task.
Local Explanations via Necessity and Sufficiency: Unifying Theory and Practice
Mar 27, 2021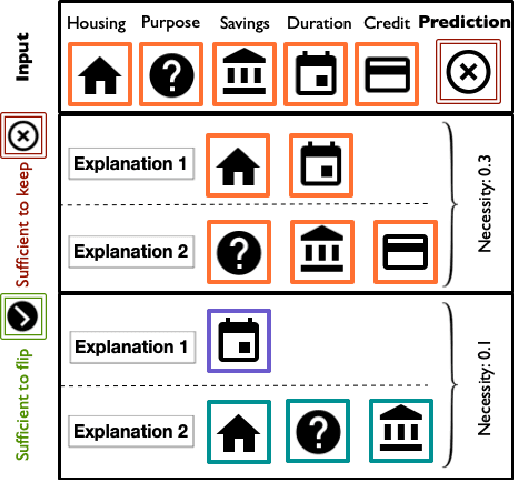

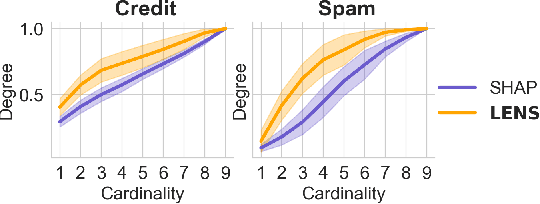

Necessity and sufficiency are the building blocks of all successful explanations. Yet despite their importance, these notions have been conceptually underdeveloped and inconsistently applied in explainable artificial intelligence (XAI), a fast-growing research area that is so far lacking in firm theoretical foundations. Building on work in logic, probability, and causality, we establish the central role of necessity and sufficiency in XAI, unifying seemingly disparate methods in a single formal framework. We provide a sound and complete algorithm for computing explanatory factors with respect to a given context, and demonstrate its flexibility and competitive performance against state of the art alternatives on various tasks.
Causal Feature Learning for Utility-Maximizing Agents
Jun 06, 2020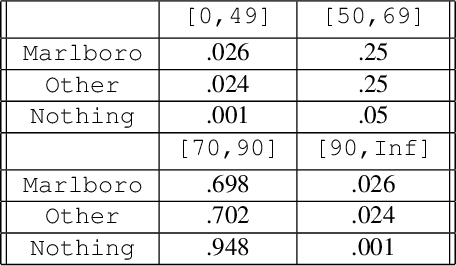
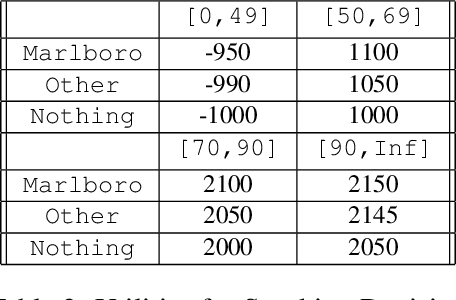

Discovering high-level causal relations from low-level data is an important and challenging problem that comes up frequently in the natural and social sciences. In a series of papers, Chalupka et al. (2015, 2016a, 2016b, 2017) develop a procedure for causal feature learning (CFL) in an effort to automate this task. We argue that CFL does not recommend coarsening in cases where pragmatic considerations rule in favor of it, and recommends coarsening in cases where pragmatic considerations rule against it. We propose a new technique, pragmatic causal feature learning (PCFL), which extends the original CFL algorithm in useful and intuitive ways. We show that PCFL has the same attractive measure-theoretic properties as the original CFL algorithm. We compare the performance of both methods through theoretical analysis and experiments.