 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCURVE: A Benchmark for Cultural and Multilingual Long Video Reasoning
Jan 15, 2026Recent advancements in video models have shown tremendous progress, particularly in long video understanding. However, current benchmarks predominantly feature western-centric data and English as the dominant language, introducing significant biases in evaluation. To address this, we introduce CURVE (Cultural Understanding and Reasoning in Video Evaluation), a challenging benchmark for multicultural and multilingual video reasoning. CURVE comprises high-quality, entirely human-generated annotations from diverse, region-specific cultural videos across 18 global locales. Unlike prior work that relies on automatic translations, CURVE provides complex questions, answers, and multi-step reasoning steps, all crafted in native languages. Making progress on CURVE requires a deeply situated understanding of visual cultural context. Furthermore, we leverage CURVE's reasoning traces to construct evidence-based graphs and propose a novel iterative strategy using these graphs to identify fine-grained errors in reasoning. Our evaluations reveal that SoTA Video-LLMs struggle significantly, performing substantially below human-level accuracy, with errors primarily stemming from the visual perception of cultural elements. CURVE will be publicly available under https://github.com/google-deepmind/neptune?tab=readme-ov-file\#minerva-cultural
SMOL: Professionally translated parallel data for 115 under-represented languages
Feb 17, 2025
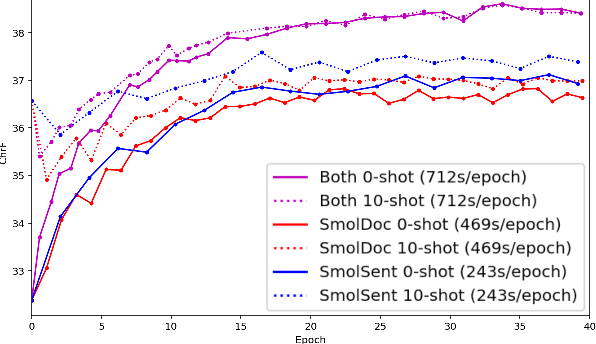
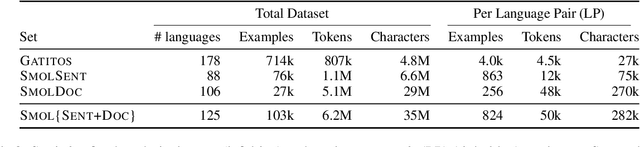
We open-source SMOL (Set of Maximal Overall Leverage), a suite of training data to unlock translation for low-resource languages (LRLs). SMOL has been translated into 115 under-resourced languages, including many for which there exist no previous public resources, for a total of 6.1M translated tokens. SMOL comprises two sub-datasets, each carefully chosen for maximum impact given its size: SMOL-Sent, a set of sentences chosen for broad unique token coverage, and SMOL-Doc, a document-level source focusing on a broad topic coverage. They join the already released GATITOS for a trifecta of paragraph, sentence, and token-level content. We demonstrate that using SMOL to prompt or fine-tune Large Language Models yields robust ChrF improvements. In addition to translation, we provide factuality ratings and rationales for all documents in SMOL-Doc, yielding the first factuality datasets for most of these languages.
Agricultural Landscape Understanding At Country-Scale
Nov 08, 2024Agricultural landscapes are quite complex, especially in the Global South where fields are smaller, and agricultural practices are more varied. In this paper we report on our progress in digitizing the agricultural landscape (natural and man-made) in our study region of India. We use high resolution imagery and a UNet style segmentation model to generate the first of its kind national-scale multi-class panoptic segmentation output. Through this work we have been able to identify individual fields across 151.7M hectares, and delineating key features such as water resources and vegetation. We share how this output was validated by our team and externally by downstream users, including some sample use cases that can lead to targeted data driven decision making. We believe this dataset will contribute towards digitizing agriculture by generating the foundational baselayer.
IndicGenBench: A Multilingual Benchmark to Evaluate Generation Capabilities of LLMs on Indic Languages
Apr 25, 2024As large language models (LLMs) see increasing adoption across the globe, it is imperative for LLMs to be representative of the linguistic diversity of the world. India is a linguistically diverse country of 1.4 Billion people. To facilitate research on multilingual LLM evaluation, we release IndicGenBench - the largest benchmark for evaluating LLMs on user-facing generation tasks across a diverse set 29 of Indic languages covering 13 scripts and 4 language families. IndicGenBench is composed of diverse generation tasks like cross-lingual summarization, machine translation, and cross-lingual question answering. IndicGenBench extends existing benchmarks to many Indic languages through human curation providing multi-way parallel evaluation data for many under-represented Indic languages for the first time. We evaluate a wide range of proprietary and open-source LLMs including GPT-3.5, GPT-4, PaLM-2, mT5, Gemma, BLOOM and LLaMA on IndicGenBench in a variety of settings. The largest PaLM-2 models performs the best on most tasks, however, there is a significant performance gap in all languages compared to English showing that further research is needed for the development of more inclusive multilingual language models. IndicGenBench is released at www.github.com/google-research-datasets/indic-gen-bench
Building Socio-culturally Inclusive Stereotype Resources with Community Engagement
Jul 20, 2023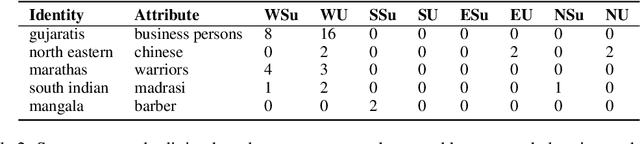



With rapid development and deployment of generative language models in global settings, there is an urgent need to also scale our measurements of harm, not just in the number and types of harms covered, but also how well they account for local cultural contexts, including marginalized identities and the social biases experienced by them. Current evaluation paradigms are limited in their abilities to address this, as they are not representative of diverse, locally situated but global, socio-cultural perspectives. It is imperative that our evaluation resources are enhanced and calibrated by including people and experiences from different cultures and societies worldwide, in order to prevent gross underestimations or skews in measurements of harm. In this work, we demonstrate a socio-culturally aware expansion of evaluation resources in the Indian societal context, specifically for the harm of stereotyping. We devise a community engaged effort to build a resource which contains stereotypes for axes of disparity that are uniquely present in India. The resultant resource increases the number of stereotypes known for and in the Indian context by over 1000 stereotypes across many unique identities. We also demonstrate the utility and effectiveness of such expanded resources for evaluations of language models. CONTENT WARNING: This paper contains examples of stereotypes that may be offensive.