 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSegmentation-Aware Latent Diffusion for Satellite Image Super-Resolution: Enabling Smallholder Farm Boundary Delineation
Nov 18, 2025Delineating farm boundaries through segmentation of satellite images is a fundamental step in many agricultural applications. The task is particularly challenging for smallholder farms, where accurate delineation requires the use of high resolution (HR) imagery which are available only at low revisit frequencies (e.g., annually). To support more frequent (sub-) seasonal monitoring, HR images could be combined as references (ref) with low resolution (LR) images -- having higher revisit frequency (e.g., weekly) -- using reference-based super-resolution (Ref-SR) methods. However, current Ref-SR methods optimize perceptual quality and smooth over crucial features needed for downstream tasks, and are unable to meet the large scale-factor requirements for this task. Further, previous two-step approaches of SR followed by segmentation do not effectively utilize diverse satellite sources as inputs. We address these problems through a new approach, $\textbf{SEED-SR}$, which uses a combination of conditional latent diffusion models and large-scale multi-spectral, multi-source geo-spatial foundation models. Our key innovation is to bypass the explicit SR task in the pixel space and instead perform SR in a segmentation-aware latent space. This unique approach enables us to generate segmentation maps at an unprecedented 20$\times$ scale factor, and rigorous experiments on two large, real datasets demonstrate up to $\textbf{25.5}$ and $\textbf{12.9}$ relative improvement in instance and semantic segmentation metrics respectively over approaches based on state-of-the-art Ref-SR methods.
Agricultural Landscape Understanding At Country-Scale
Nov 08, 2024Agricultural landscapes are quite complex, especially in the Global South where fields are smaller, and agricultural practices are more varied. In this paper we report on our progress in digitizing the agricultural landscape (natural and man-made) in our study region of India. We use high resolution imagery and a UNet style segmentation model to generate the first of its kind national-scale multi-class panoptic segmentation output. Through this work we have been able to identify individual fields across 151.7M hectares, and delineating key features such as water resources and vegetation. We share how this output was validated by our team and externally by downstream users, including some sample use cases that can lead to targeted data driven decision making. We believe this dataset will contribute towards digitizing agriculture by generating the foundational baselayer.
Fast exploration and learning of latent graphs with aliased observations
Mar 21, 2023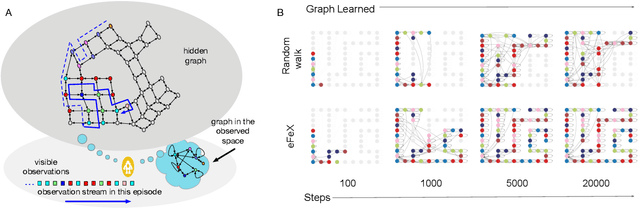
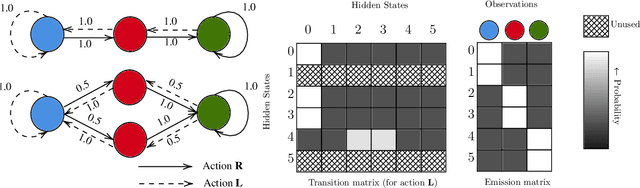
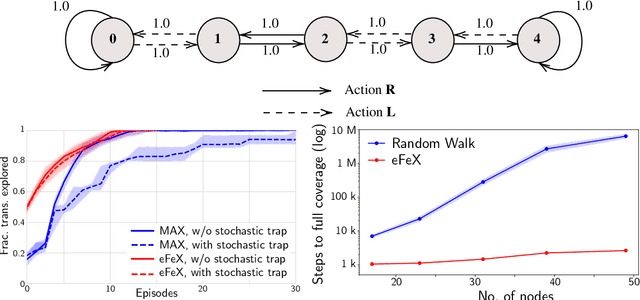
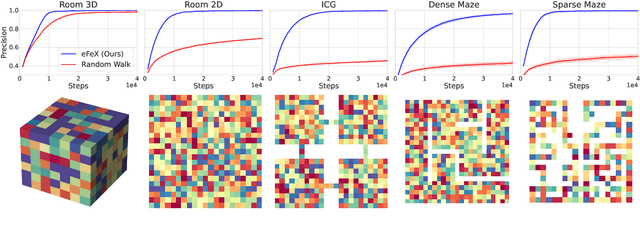
Consider this scenario: an agent navigates a latent graph by performing actions that take it from one node to another. The chosen action determines the probability distribution over the next visited node. At each node, the agent receives an observation, but this observation is not unique, so it does not identify the node, making the problem aliased. The purpose of this work is to provide a policy that approximately maximizes exploration efficiency (i.e., how well the graph is recovered for a given exploration budget). In the unaliased case, we show improved performance w.r.t. state-of-the-art reinforcement learning baselines. For the aliased case we are not aware of suitable baselines and instead show faster recovery w.r.t. a random policy for a wide variety of topologies, and exponentially faster recovery than a random policy for challenging topologies. We dub the algorithm eFeX (from eFficient eXploration).
Graph schemas as abstractions for transfer learning, inference, and planning
Feb 14, 2023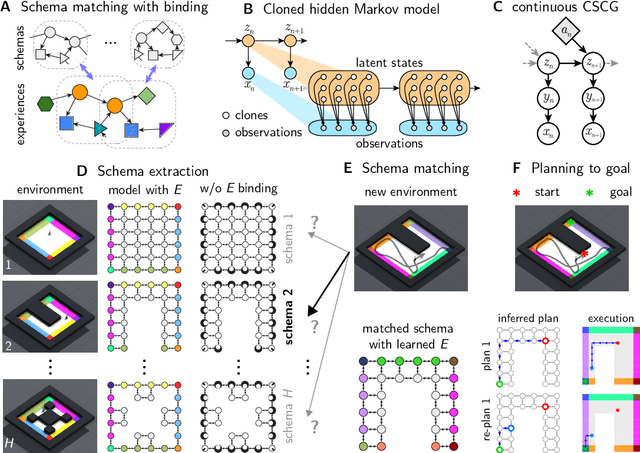



We propose schemas as a model for abstractions that can be used for rapid transfer learning, inference, and planning. Common structured representations of concepts and behaviors -- schemas -- have been proposed as a powerful way to encode abstractions. Latent graph learning is emerging as a new computational model of the hippocampus to explain map learning and transitive inference. We build on this work to show that learned latent graphs in these models have a slot structure -- schemas -- that allow for quick knowledge transfer across environments. In a new environment, an agent can rapidly learn new bindings between the sensory stream to multiple latent schemas and select the best fitting one to guide behavior. To evaluate these graph schemas, we use two previously published challenging tasks: the memory & planning game and one-shot StreetLearn, that are designed to test rapid task solving in novel environments. Graph schemas can be learned in far fewer episodes than previous baselines, and can model and plan in a few steps in novel variations of these tasks. We further demonstrate learning, matching, and reusing graph schemas in navigation tasks in more challenging environments with aliased observations and size variations, and show how different schemas can be composed to model larger 2D and 3D environments.
Max-Sliced Wasserstein Distance and its use for GANs
Apr 11, 2019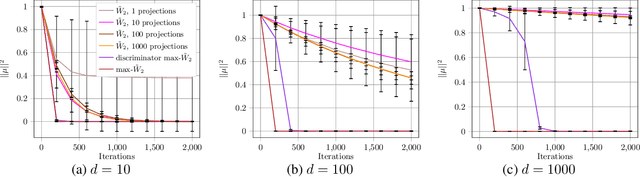

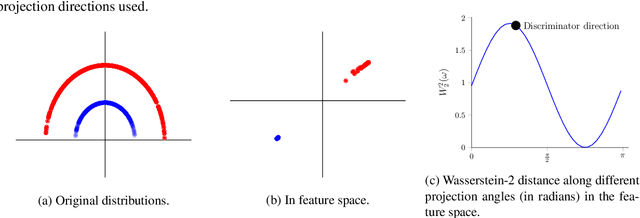

Generative adversarial nets (GANs) and variational auto-encoders have significantly improved our distribution modeling capabilities, showing promise for dataset augmentation, image-to-image translation and feature learning. However, to model high-dimensional distributions, sequential training and stacked architectures are common, increasing the number of tunable hyper-parameters as well as the training time. Nonetheless, the sample complexity of the distance metrics remains one of the factors affecting GAN training. We first show that the recently proposed sliced Wasserstein distance has compelling sample complexity properties when compared to the Wasserstein distance. To further improve the sliced Wasserstein distance we then analyze its `projection complexity' and develop the max-sliced Wasserstein distance which enjoys compelling sample complexity while reducing projection complexity, albeit necessitating a max estimation. We finally illustrate that the proposed distance trains GANs on high-dimensional images up to a resolution of 256x256 easily.
Generative Modeling using the Sliced Wasserstein Distance
Mar 29, 2018

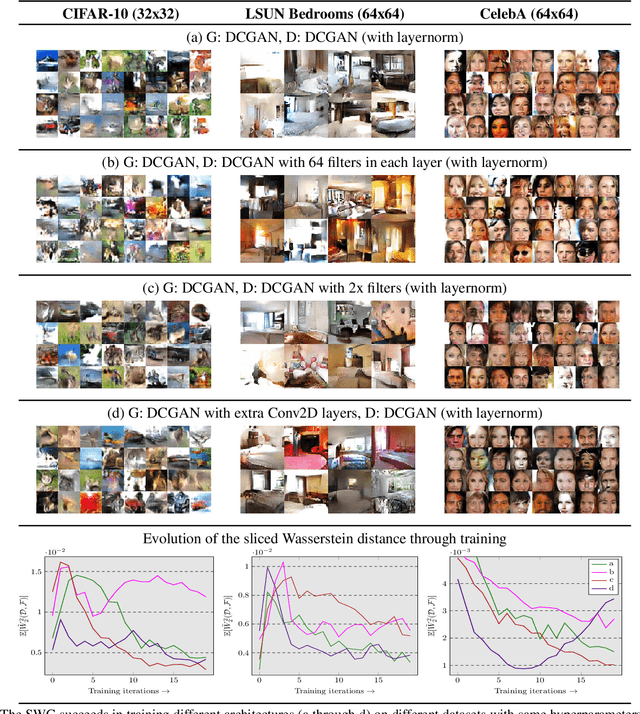
Generative Adversarial Nets (GANs) are very successful at modeling distributions from given samples, even in the high-dimensional case. However, their formulation is also known to be hard to optimize and often not stable. While this is particularly true for early GAN formulations, there has been significant empirically motivated and theoretically founded progress to improve stability, for instance, by using the Wasserstein distance rather than the Jenson-Shannon divergence. Here, we consider an alternative formulation for generative modeling based on random projections which, in its simplest form, results in a single objective rather than a saddle-point formulation. By augmenting this approach with a discriminator we improve its accuracy. We found our approach to be significantly more stable compared to even the improved Wasserstein GAN. Further, unlike the traditional GAN loss, the loss formulated in our method is a good measure of the actual distance between the distributions and, for the first time for GAN training, we are able to show estimates for the same.