 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModel Predictive Simulation Using Structured Graphical Models and Transformers
Jun 28, 2024We propose an approach to simulating trajectories of multiple interacting agents (road users) based on transformers and probabilistic graphical models (PGMs), and apply it to the Waymo SimAgents challenge. The transformer baseline is based on the MTR model, which predicts multiple future trajectories conditioned on the past trajectories and static road layout features. We then improve upon these generated trajectories using a PGM, which contains factors which encode prior knowledge, such as a preference for smooth trajectories, and avoidance of collisions with static obstacles and other moving agents. We perform (approximate) MAP inference in this PGM using the Gauss-Newton method. Finally we sample $K=32$ trajectories for each of the $N \sim 100$ agents for the next $T=8 \Delta$ time steps, where $\Delta=10$ is the sampling rate per second. Following the Model Predictive Control (MPC) paradigm, we only return the first element of our forecasted trajectories at each step, and then we replan, so that the simulation can constantly adapt to its changing environment. We therefore call our approach "Model Predictive Simulation" or MPS. We show that MPS improves upon the MTR baseline, especially in safety critical metrics such as collision rate. Furthermore, our approach is compatible with any underlying forecasting model, and does not require extra training, so we believe it is a valuable contribution to the community.
Fast exploration and learning of latent graphs with aliased observations
Mar 21, 2023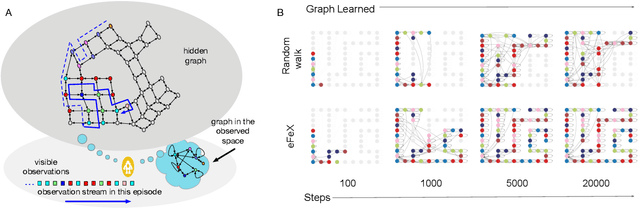
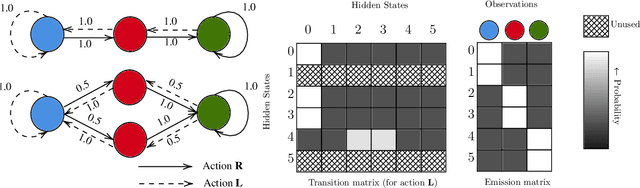
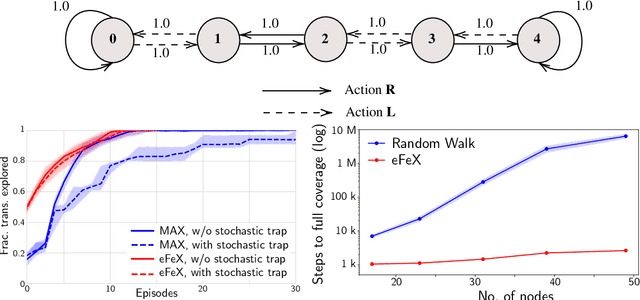
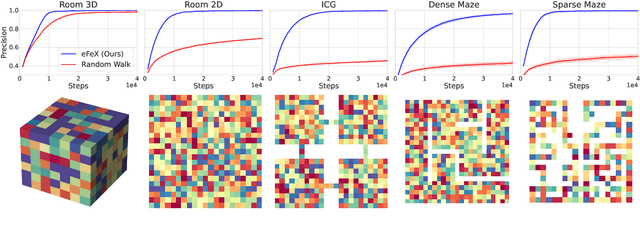
Consider this scenario: an agent navigates a latent graph by performing actions that take it from one node to another. The chosen action determines the probability distribution over the next visited node. At each node, the agent receives an observation, but this observation is not unique, so it does not identify the node, making the problem aliased. The purpose of this work is to provide a policy that approximately maximizes exploration efficiency (i.e., how well the graph is recovered for a given exploration budget). In the unaliased case, we show improved performance w.r.t. state-of-the-art reinforcement learning baselines. For the aliased case we are not aware of suitable baselines and instead show faster recovery w.r.t. a random policy for a wide variety of topologies, and exponentially faster recovery than a random policy for challenging topologies. We dub the algorithm eFeX (from eFficient eXploration).