 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModel Predictive Simulation Using Structured Graphical Models and Transformers
Jun 28, 2024We propose an approach to simulating trajectories of multiple interacting agents (road users) based on transformers and probabilistic graphical models (PGMs), and apply it to the Waymo SimAgents challenge. The transformer baseline is based on the MTR model, which predicts multiple future trajectories conditioned on the past trajectories and static road layout features. We then improve upon these generated trajectories using a PGM, which contains factors which encode prior knowledge, such as a preference for smooth trajectories, and avoidance of collisions with static obstacles and other moving agents. We perform (approximate) MAP inference in this PGM using the Gauss-Newton method. Finally we sample $K=32$ trajectories for each of the $N \sim 100$ agents for the next $T=8 \Delta$ time steps, where $\Delta=10$ is the sampling rate per second. Following the Model Predictive Control (MPC) paradigm, we only return the first element of our forecasted trajectories at each step, and then we replan, so that the simulation can constantly adapt to its changing environment. We therefore call our approach "Model Predictive Simulation" or MPS. We show that MPS improves upon the MTR baseline, especially in safety critical metrics such as collision rate. Furthermore, our approach is compatible with any underlying forecasting model, and does not require extra training, so we believe it is a valuable contribution to the community.
Graph schemas as abstractions for transfer learning, inference, and planning
Feb 14, 2023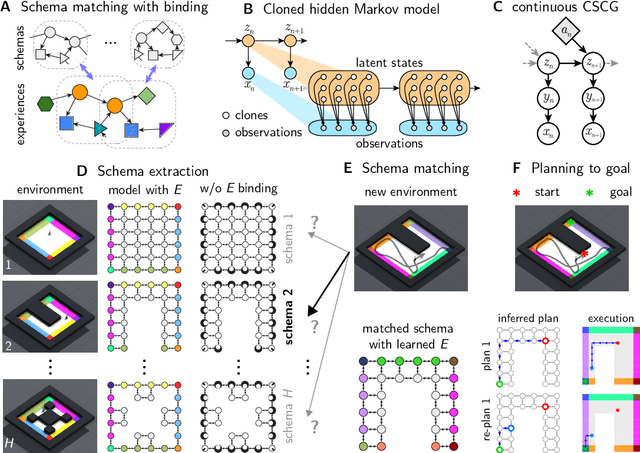



We propose schemas as a model for abstractions that can be used for rapid transfer learning, inference, and planning. Common structured representations of concepts and behaviors -- schemas -- have been proposed as a powerful way to encode abstractions. Latent graph learning is emerging as a new computational model of the hippocampus to explain map learning and transitive inference. We build on this work to show that learned latent graphs in these models have a slot structure -- schemas -- that allow for quick knowledge transfer across environments. In a new environment, an agent can rapidly learn new bindings between the sensory stream to multiple latent schemas and select the best fitting one to guide behavior. To evaluate these graph schemas, we use two previously published challenging tasks: the memory & planning game and one-shot StreetLearn, that are designed to test rapid task solving in novel environments. Graph schemas can be learned in far fewer episodes than previous baselines, and can model and plan in a few steps in novel variations of these tasks. We further demonstrate learning, matching, and reusing graph schemas in navigation tasks in more challenging environments with aliased observations and size variations, and show how different schemas can be composed to model larger 2D and 3D environments.
PGMax: Factor Graphs for Discrete Probabilistic Graphical Models and Loopy Belief Propagation in JAX
Feb 08, 2022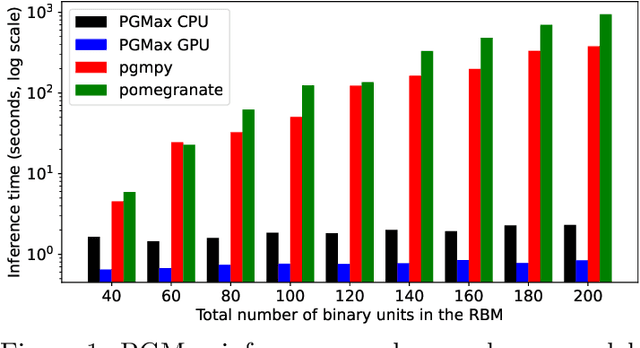
PGMax is an open-source Python package for easy specification of discrete Probabilistic Graphical Models (PGMs) as factor graphs, and automatic derivation of efficient and scalable loopy belief propagation (LBP) implementation in JAX. It supports general factor graphs, and can effectively leverage modern accelerators like GPUs for inference. Compared with existing alternatives, PGMax obtains higher-quality inference results with orders-of-magnitude inference speedups. PGMax additionally interacts seamlessly with the rapidly growing JAX ecosystem, opening up exciting new possibilities. Our source code, examples and documentation are available at https://github.com/vicariousinc/PGMax.
On sampling from data with duplicate records
Aug 24, 2020
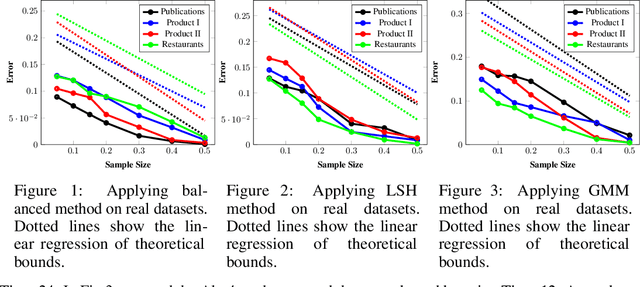
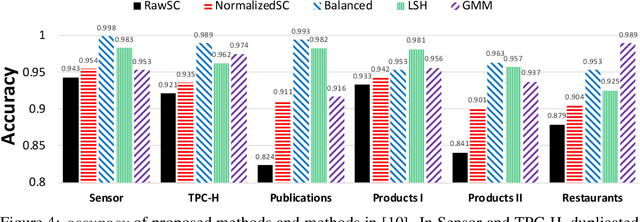
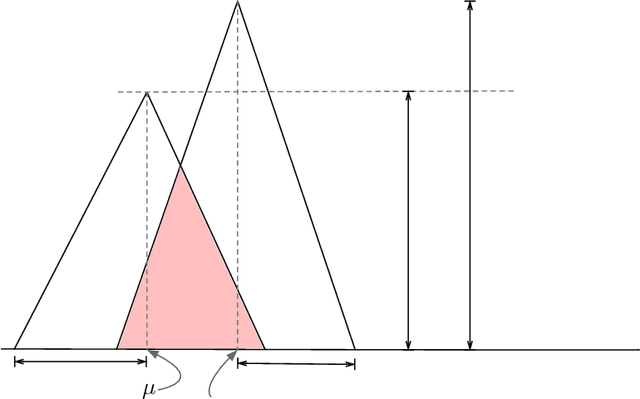
Data deduplication is the task of detecting records in a database that correspond to the same real-world entity. Our goal is to develop a procedure that samples uniformly from the set of entities present in the database in the presence of duplicates. We accomplish this by a two-stage process. In the first step, we estimate the frequencies of all the entities in the database. In the second step, we use rejection sampling to obtain a (approximately) uniform sample from the set of entities. However, efficiently estimating the frequency of all the entities is a non-trivial task and not attainable in the general case. Hence, we consider various natural properties of the data under which such frequency estimation (and consequently uniform sampling) is possible. Under each of those assumptions, we provide sampling algorithms and give proofs of the complexity (both statistical and computational) of our approach. We complement our study by conducting extensive experiments on both real and synthetic datasets.
Record fusion: A learning approach
Jun 18, 2020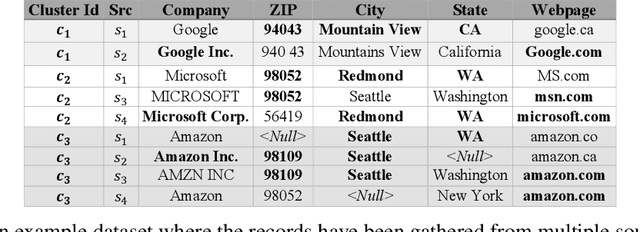
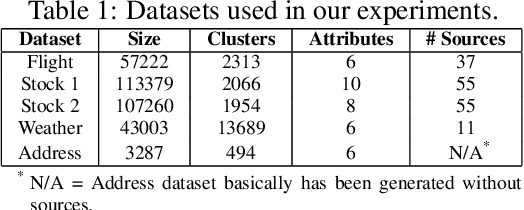
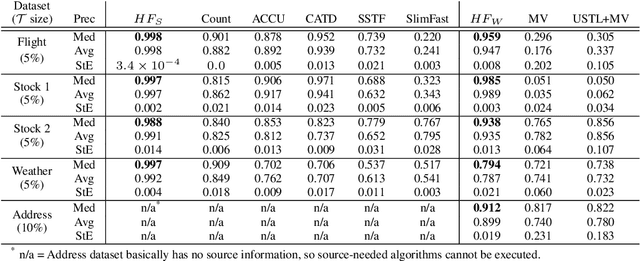
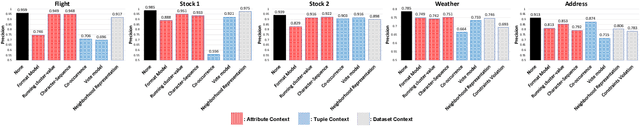
Record fusion is the task of aggregating multiple records that correspond to the same real-world entity in a database. We can view record fusion as a machine learning problem where the goal is to predict the "correct" value for each attribute for each entity. Given a database, we use a combination of attribute-level, recordlevel, and database-level signals to construct a feature vector for each cell (or (row, col)) of that database. We use this feature vector alongwith the ground-truth information to learn a classifier for each of the attributes of the database. Our learning algorithm uses a novel stagewise additive model. At each stage, we construct a new feature vector by combining a part of the original feature vector with features computed by the predictions from the previous stage. We then learn a softmax classifier over the new feature space. This greedy stagewise approach can be viewed as a deep model where at each stage, we are adding more complicated non-linear transformations of the original feature vector. We show that our approach fuses records with an average precision of ~98% when source information of records is available, and ~94% without source information across a diverse array of real-world datasets. We compare our approach to a comprehensive collection of data fusion and entity consolidation methods considered in the literature. We show that our approach can achieve an average precision improvement of ~20%/~45% with/without source information respectively.
Better Together: Resnet-50 accuracy with $13x$ fewer parameters and at $3x$ speed
Jun 10, 2020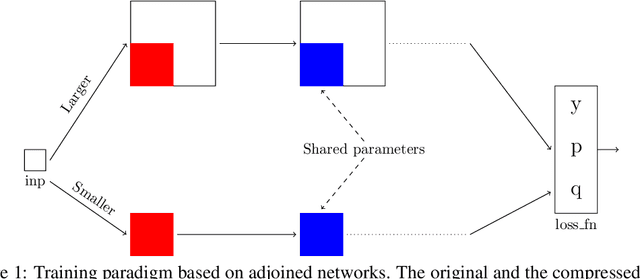
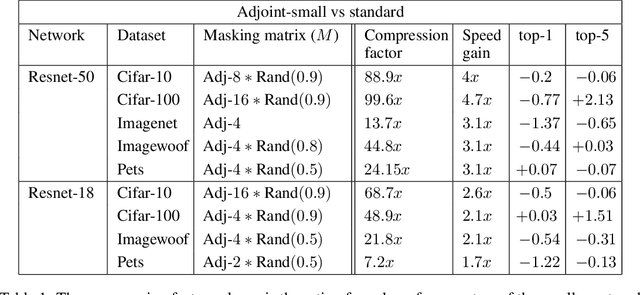
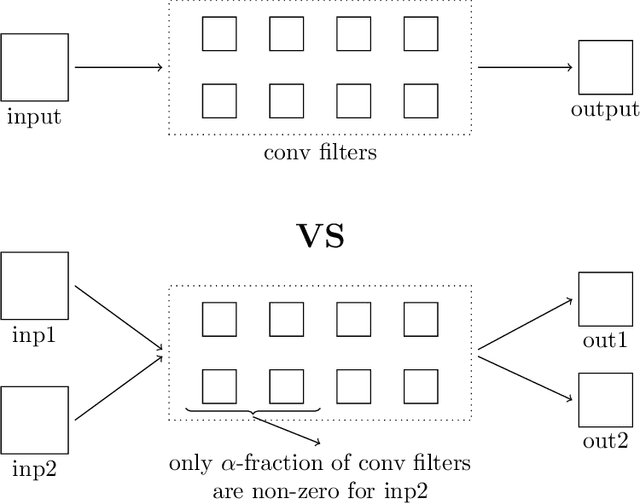
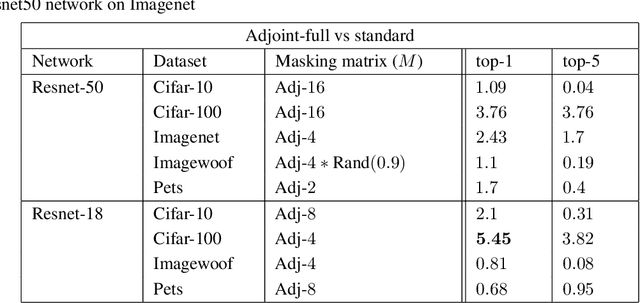
Recent research on compressing deep neural networks has focused on reducing the number of parameters. Smaller networks are easier to export and deploy on edge-devices. We introduce Adjoined networks as a training approach that can compress and regularize any CNN-based neural architecture. Our one-shot learning paradigm trains both the original and the smaller networks together. The parameters of the smaller network are shared across both the architectures. For resnet-50 trained on Imagenet, we are able to achieve a $13.7x$ reduction in the number of parameters and a $3x$ improvement in inference time without any significant drop in accuracy. For the same architecture on CIFAR-100, we are able to achieve a $99.7x$ reduction in the number of parameters and a $5x$ improvement in inference time. On both these datasets, the original network trained in the adjoint fashion gains about $3\%$ in top-1 accuracy as compared to the same network trained in the standard fashion.
Semi-supervised clustering for de-duplication
Oct 10, 2018
Data de-duplication is the task of detecting multiple records that correspond to the same real-world entity in a database. In this work, we view de-duplication as a clustering problem where the goal is to put records corresponding to the same physical entity in the same cluster and putting records corresponding to different physical entities into different clusters. We introduce a framework which we call promise correlation clustering. Given a complete graph $G$ with the edges labelled $0$ and $1$, the goal is to find a clustering that minimizes the number of $0$ edges within a cluster plus the number of $1$ edges across different clusters (or correlation loss). The optimal clustering can also be viewed as a complete graph $G^*$ with edges corresponding to points in the same cluster being labelled $0$ and other edges being labelled $1$. Under the promise that the edge difference between $G$ and $G^*$ is "small", we prove that finding the optimal clustering (or $G^*$) is still NP-Hard. [Ashtiani et. al, 2016] introduced the framework of semi-supervised clustering, where the learning algorithm has access to an oracle, which answers whether two points belong to the same or different clusters. We further prove that even with access to a same-cluster oracle, the promise version is NP-Hard as long as the number queries to the oracle is not too large ($o(n)$ where $n$ is the number of vertices). Given these negative results, we consider a restricted version of correlation clustering. As before, the goal is to find a clustering that minimizes the correlation loss. However, we restrict ourselves to a given class $\mathcal F$ of clusterings. We offer a semi-supervised algorithmic approach to solve the restricted variant with success guarantees.
Provably noise-robust, regularised $k$-means clustering
Aug 27, 2018

We consider the problem of clustering in the presence of noise. That is, when on top of cluster structure, the data also contains a subset of \emph{unstructured} points. Our goal is to detect the clusters despite the presence of many unstructured points. Any algorithm that achieves this goal is noise-robust. We consider a regularisation method which converts any center-based clustering objective into a noise-robust one. We focus on the $k$-means objective and we prove that the regularised version of $k$-means is NP-Hard even for $k=1$. We consider two algorithms based on the convex (sdp and lp) relaxation of the regularised objective and prove robustness guarantees for both. The sdp and lp relaxation of the standard (non-regularised) $k$-means objective has been previously studied by [ABC+15]. Under the stochastic ball model of the data they show that the sdp-based algorithm recovers the underlying structure as long as the balls are separated by $\delta > 2\sqrt{2} + \epsilon$. We improve upon this result in two ways. First, we show recovery even for $\delta > 2 + \epsilon$. Second, our regularised algorithm recovers the balls even in the presence of noise so long as the number of noisy points is not too large. We complement our theoretical analysis with simulations and analyse the effect of various parameters like regularization constant, noise-level etc. on the performance of our algorithm. In the presence of noise, our algorithm performs better than $k$-means++ on MNIST.
Clustering with Same-Cluster Queries
Nov 22, 2016
We propose a framework for Semi-Supervised Active Clustering framework (SSAC), where the learner is allowed to interact with a domain expert, asking whether two given instances belong to the same cluster or not. We study the query and computational complexity of clustering in this framework. We consider a setting where the expert conforms to a center-based clustering with a notion of margin. We show that there is a trade off between computational complexity and query complexity; We prove that for the case of $k$-means clustering (i.e., when the expert conforms to a solution of $k$-means), having access to relatively few such queries allows efficient solutions to otherwise NP hard problems. In particular, we provide a probabilistic polynomial-time (BPP) algorithm for clustering in this setting that asks $O\big(k^2\log k + k\log n)$ same-cluster queries and runs with time complexity $O\big(kn\log n)$ (where $k$ is the number of clusters and $n$ is the number of instances). The algorithm succeeds with high probability for data satisfying margin conditions under which, without queries, we show that the problem is NP hard. We also prove a lower bound on the number of queries needed to have a computationally efficient clustering algorithm in this setting.