 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBetter Together: Resnet-50 accuracy with $13x$ fewer parameters and at $3x$ speed
Paper and Code
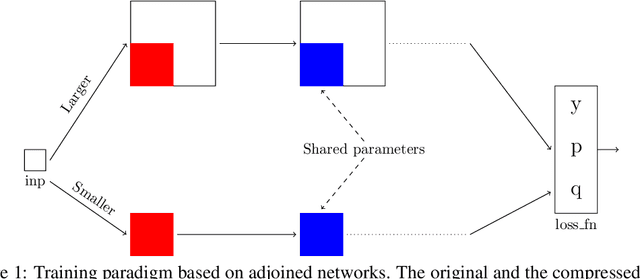
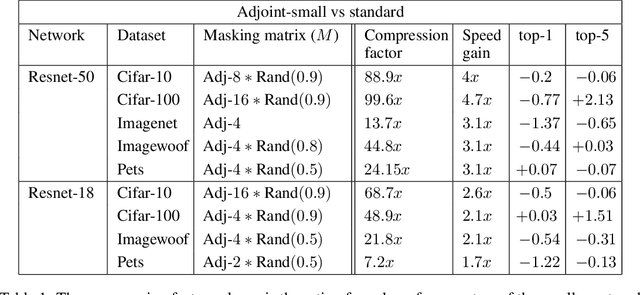
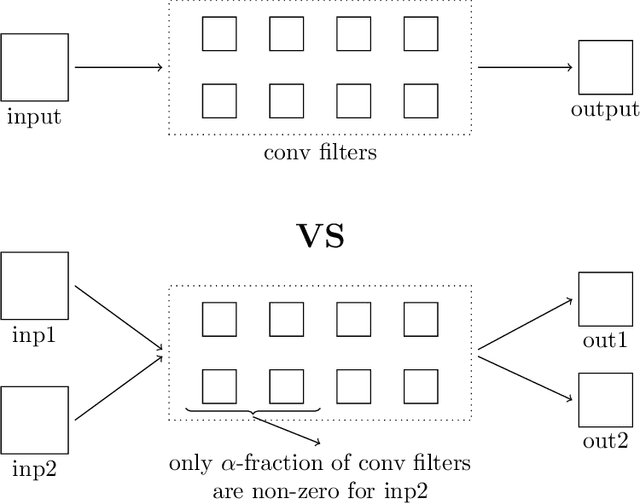
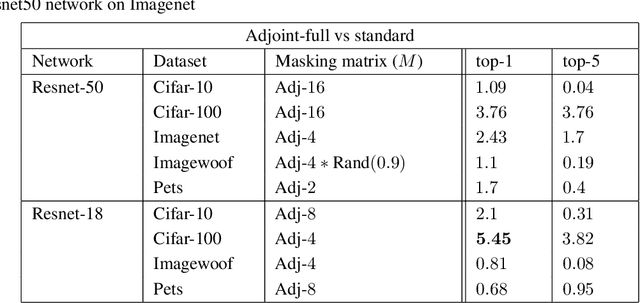
Recent research on compressing deep neural networks has focused on reducing the number of parameters. Smaller networks are easier to export and deploy on edge-devices. We introduce Adjoined networks as a training approach that can compress and regularize any CNN-based neural architecture. Our one-shot learning paradigm trains both the original and the smaller networks together. The parameters of the smaller network are shared across both the architectures. For resnet-50 trained on Imagenet, we are able to achieve a $13.7x$ reduction in the number of parameters and a $3x$ improvement in inference time without any significant drop in accuracy. For the same architecture on CIFAR-100, we are able to achieve a $99.7x$ reduction in the number of parameters and a $5x$ improvement in inference time. On both these datasets, the original network trained in the adjoint fashion gains about $3\%$ in top-1 accuracy as compared to the same network trained in the standard fashion.