 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiffusion Model Predictive Control
Oct 07, 2024
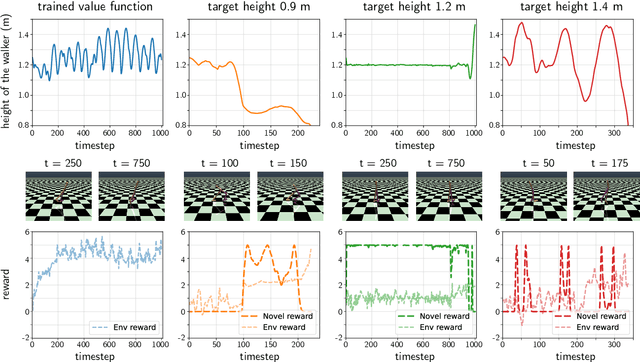
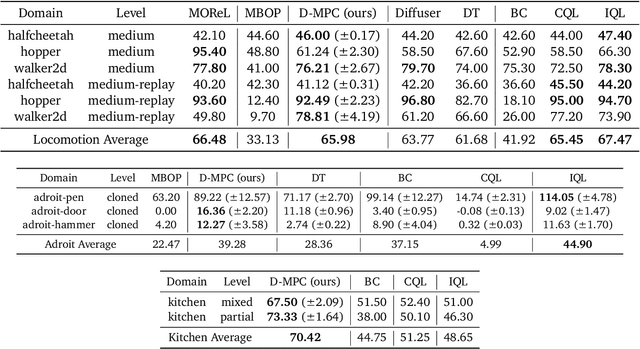
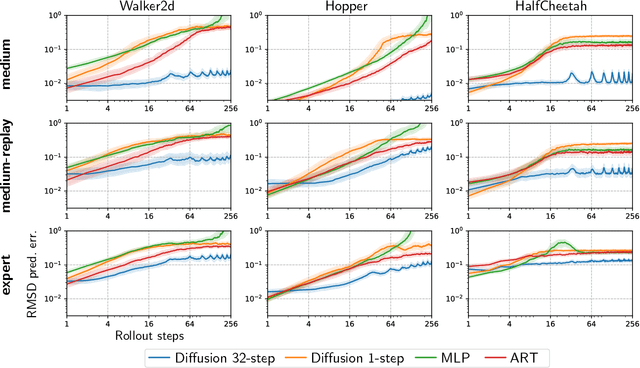
We propose Diffusion Model Predictive Control (D-MPC), a novel MPC approach that learns a multi-step action proposal and a multi-step dynamics model, both using diffusion models, and combines them for use in online MPC. On the popular D4RL benchmark, we show performance that is significantly better than existing model-based offline planning methods using MPC and competitive with state-of-the-art (SOTA) model-based and model-free reinforcement learning methods. We additionally illustrate D-MPC's ability to optimize novel reward functions at run time and adapt to novel dynamics, and highlight its advantages compared to existing diffusion-based planning baselines.
Inferring Inference
Oct 13, 2023Patterns of microcircuitry suggest that the brain has an array of repeated canonical computational units. Yet neural representations are distributed, so the relevant computations may only be related indirectly to single-neuron transformations. It thus remains an open challenge how to define canonical distributed computations. We integrate normative and algorithmic theories of neural computation into a mathematical framework for inferring canonical distributed computations from large-scale neural activity patterns. At the normative level, we hypothesize that the brain creates a structured internal model of its environment, positing latent causes that explain its sensory inputs, and uses those sensory inputs to infer the latent causes. At the algorithmic level, we propose that this inference process is a nonlinear message-passing algorithm on a graph-structured model of the world. Given a time series of neural activity during a perceptual inference task, our framework finds (i) the neural representation of relevant latent variables, (ii) interactions between these variables that define the brain's internal model of the world, and (iii) message-functions specifying the inference algorithm. These targeted computational properties are then statistically distinguishable due to the symmetries inherent in any canonical computation, up to a global transformation. As a demonstration, we simulate recordings for a model brain that implicitly implements an approximate inference algorithm on a probabilistic graphical model. Given its external inputs and noisy neural activity, we recover the latent variables, their neural representation and dynamics, and canonical message-functions. We highlight features of experimental design needed to successfully extract canonical computations from neural data. Overall, this framework provides a new tool for discovering interpretable structure in neural recordings.
Schema-learning and rebinding as mechanisms of in-context learning and emergence
Jun 16, 2023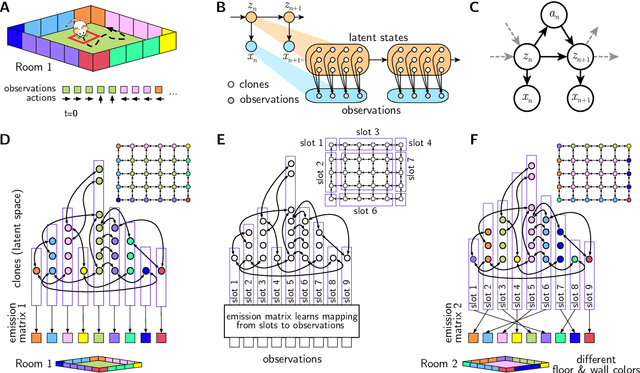
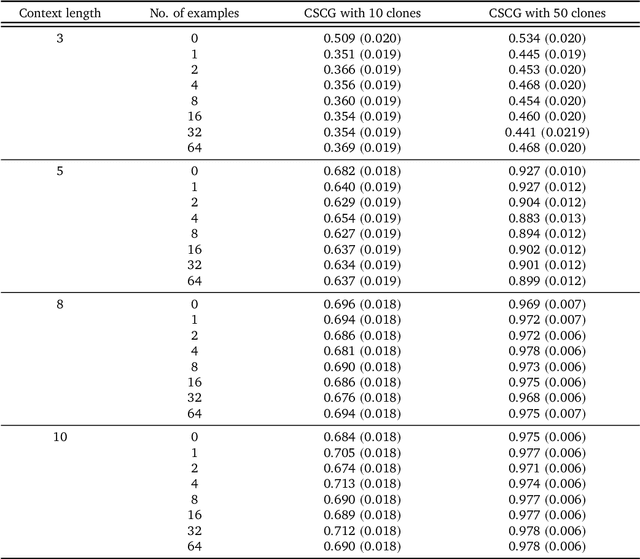
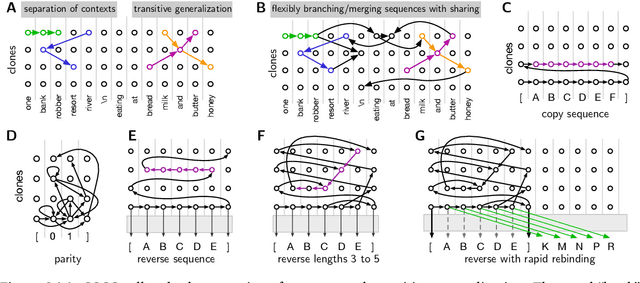
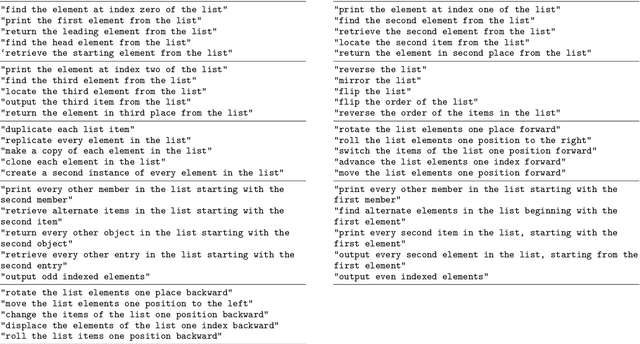
In-context learning (ICL) is one of the most powerful and most unexpected capabilities to emerge in recent transformer-based large language models (LLMs). Yet the mechanisms that underlie it are poorly understood. In this paper, we demonstrate that comparable ICL capabilities can be acquired by an alternative sequence prediction learning method using clone-structured causal graphs (CSCGs). Moreover, a key property of CSCGs is that, unlike transformer-based LLMs, they are {\em interpretable}, which considerably simplifies the task of explaining how ICL works. Specifically, we show that it uses a combination of (a) learning template (schema) circuits for pattern completion, (b) retrieving relevant templates in a context-sensitive manner, and (c) rebinding of novel tokens to appropriate slots in the templates. We go on to marshall evidence for the hypothesis that similar mechanisms underlie ICL in LLMs. For example, we find that, with CSCGs as with LLMs, different capabilities emerge at different levels of overparameterization, suggesting that overparameterization helps in learning more complex template (schema) circuits. By showing how ICL can be achieved with small models and datasets, we open up a path to novel architectures, and take a vital step towards a more general understanding of the mechanics behind this important capability.
Graph schemas as abstractions for transfer learning, inference, and planning
Feb 14, 2023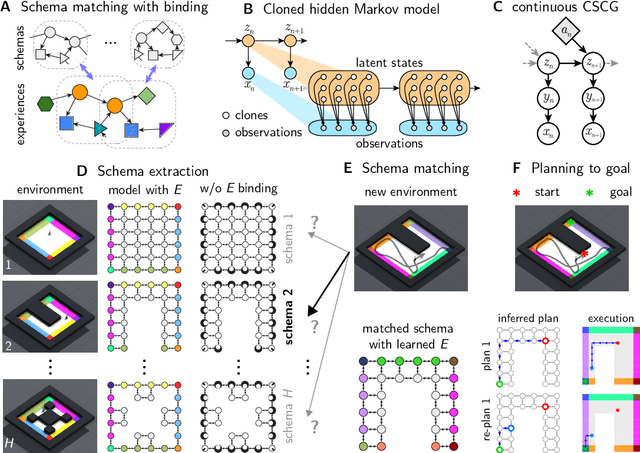



We propose schemas as a model for abstractions that can be used for rapid transfer learning, inference, and planning. Common structured representations of concepts and behaviors -- schemas -- have been proposed as a powerful way to encode abstractions. Latent graph learning is emerging as a new computational model of the hippocampus to explain map learning and transitive inference. We build on this work to show that learned latent graphs in these models have a slot structure -- schemas -- that allow for quick knowledge transfer across environments. In a new environment, an agent can rapidly learn new bindings between the sensory stream to multiple latent schemas and select the best fitting one to guide behavior. To evaluate these graph schemas, we use two previously published challenging tasks: the memory & planning game and one-shot StreetLearn, that are designed to test rapid task solving in novel environments. Graph schemas can be learned in far fewer episodes than previous baselines, and can model and plan in a few steps in novel variations of these tasks. We further demonstrate learning, matching, and reusing graph schemas in navigation tasks in more challenging environments with aliased observations and size variations, and show how different schemas can be composed to model larger 2D and 3D environments.