 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeoReason: Aligning Thinking And Answering In Remote Sensing Vision-Language Models Via Logical Consistency Reinforcement Learning
Jan 08, 2026The evolution of Remote Sensing Vision-Language Models(RS-VLMs) emphasizes the importance of transitioning from perception-centric recognition toward high-level deductive reasoning to enhance cognitive reliability in complex spatial tasks. However, current models often suffer from logical hallucinations, where correct answers are derived from flawed reasoning chains or rely on positional shortcuts rather than spatial logic. This decoupling undermines reliability in strategic spatial decision-making. To address this, we present GeoReason, a framework designed to synchronize internal thinking with final decisions. We first construct GeoReason-Bench, a logic-driven dataset containing 4,000 reasoning trajectories synthesized from geometric primitives and expert knowledge. We then formulate a two-stage training strategy: (1) Supervised Knowledge Initialization to equip the model with reasoning syntax and domain expertise, and (2) Consistency-Aware Reinforcement Learning to refine deductive reliability. This second stage integrates a novel Logical Consistency Reward, which penalizes logical drift via an option permutation strategy to anchor decisions in verifiable reasoning traces. Experimental results demonstrate that our framework significantly enhances the cognitive reliability and interpretability of RS-VLMs, achieving state-of-the-art performance compared to other advanced methods.
SLGNet: Synergizing Structural Priors and Language-Guided Modulation for Multimodal Object Detection
Jan 05, 2026Multimodal object detection leveraging RGB and Infrared (IR) images is pivotal for robust perception in all-weather scenarios. While recent adapter-based approaches efficiently transfer RGB-pretrained foundation models to this task, they often prioritize model efficiency at the expense of cross-modal structural consistency. Consequently, critical structural cues are frequently lost when significant domain gaps arise, such as in high-contrast or nighttime environments. Moreover, conventional static multimodal fusion mechanisms typically lack environmental awareness, resulting in suboptimal adaptation and constrained detection performance under complex, dynamic scene variations. To address these limitations, we propose SLGNet, a parameter-efficient framework that synergizes hierarchical structural priors and language-guided modulation within a frozen Vision Transformer (ViT)-based foundation model. Specifically, we design a Structure-Aware Adapter to extract hierarchical structural representations from both modalities and dynamically inject them into the ViT to compensate for structural degradation inherent in ViT-based backbones. Furthermore, we propose a Language-Guided Modulation module that exploits VLM-driven structured captions to dynamically recalibrate visual features, thereby endowing the model with robust environmental awareness. Extensive experiments on the LLVIP, FLIR, KAIST, and DroneVehicle datasets demonstrate that SLGNet establishes new state-of-the-art performance. Notably, on the LLVIP benchmark, our method achieves an mAP of 66.1, while reducing trainable parameters by approximately 87% compared to traditional full fine-tuning. This confirms SLGNet as a robust and efficient solution for multimodal perception.
Direct Motion Models for Assessing Generated Videos
Apr 30, 2025A current limitation of video generative video models is that they generate plausible looking frames, but poor motion -- an issue that is not well captured by FVD and other popular methods for evaluating generated videos. Here we go beyond FVD by developing a metric which better measures plausible object interactions and motion. Our novel approach is based on auto-encoding point tracks and yields motion features that can be used to not only compare distributions of videos (as few as one generated and one ground truth, or as many as two datasets), but also for evaluating motion of single videos. We show that using point tracks instead of pixel reconstruction or action recognition features results in a metric which is markedly more sensitive to temporal distortions in synthetic data, and can predict human evaluations of temporal consistency and realism in generated videos obtained from open-source models better than a wide range of alternatives. We also show that by using a point track representation, we can spatiotemporally localize generative video inconsistencies, providing extra interpretability of generated video errors relative to prior work. An overview of the results and link to the code can be found on the project page: http://trajan-paper.github.io.
Distributional Diffusion Models with Scoring Rules
Feb 04, 2025Diffusion models generate high-quality synthetic data. They operate by defining a continuous-time forward process which gradually adds Gaussian noise to data until fully corrupted. The corresponding reverse process progressively "denoises" a Gaussian sample into a sample from the data distribution. However, generating high-quality outputs requires many discretization steps to obtain a faithful approximation of the reverse process. This is expensive and has motivated the development of many acceleration methods. We propose to accomplish sample generation by learning the posterior {\em distribution} of clean data samples given their noisy versions, instead of only the mean of this distribution. This allows us to sample from the probability transitions of the reverse process on a coarse time scale, significantly accelerating inference with minimal degradation of the quality of the output. This is accomplished by replacing the standard regression loss used to estimate conditional means with a scoring rule. We validate our method on image and robot trajectory generation, where we consistently outperform standard diffusion models at few discretization steps.
Diffusion Model Predictive Control
Oct 07, 2024
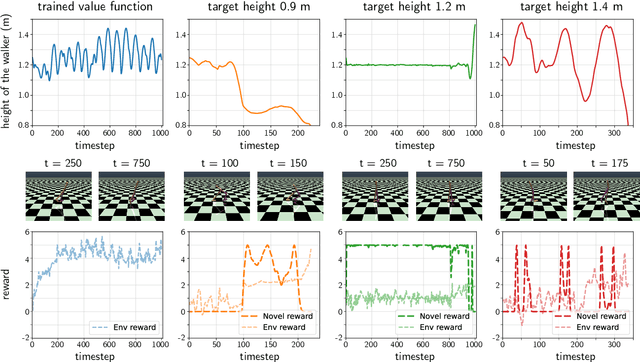
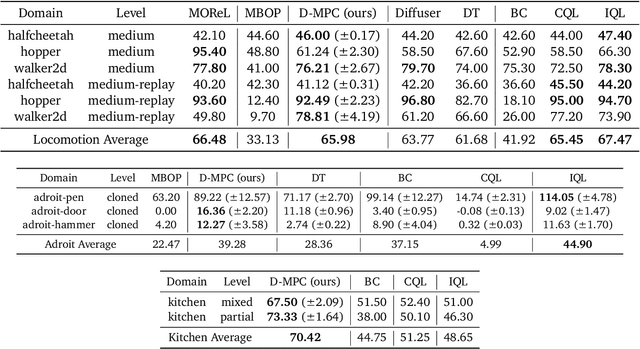
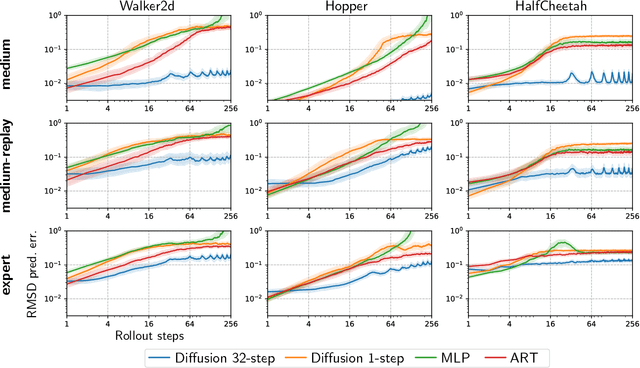
We propose Diffusion Model Predictive Control (D-MPC), a novel MPC approach that learns a multi-step action proposal and a multi-step dynamics model, both using diffusion models, and combines them for use in online MPC. On the popular D4RL benchmark, we show performance that is significantly better than existing model-based offline planning methods using MPC and competitive with state-of-the-art (SOTA) model-based and model-free reinforcement learning methods. We additionally illustrate D-MPC's ability to optimize novel reward functions at run time and adapt to novel dynamics, and highlight its advantages compared to existing diffusion-based planning baselines.
DMC-VB: A Benchmark for Representation Learning for Control with Visual Distractors
Sep 26, 2024



Learning from previously collected data via behavioral cloning or offline reinforcement learning (RL) is a powerful recipe for scaling generalist agents by avoiding the need for expensive online learning. Despite strong generalization in some respects, agents are often remarkably brittle to minor visual variations in control-irrelevant factors such as the background or camera viewpoint. In this paper, we present theDeepMind Control Visual Benchmark (DMC-VB), a dataset collected in the DeepMind Control Suite to evaluate the robustness of offline RL agents for solving continuous control tasks from visual input in the presence of visual distractors. In contrast to prior works, our dataset (a) combines locomotion and navigation tasks of varying difficulties, (b) includes static and dynamic visual variations, (c) considers data generated by policies with different skill levels, (d) systematically returns pairs of state and pixel observation, (e) is an order of magnitude larger, and (f) includes tasks with hidden goals. Accompanying our dataset, we propose three benchmarks to evaluate representation learning methods for pretraining, and carry out experiments on several recently proposed methods. First, we find that pretrained representations do not help policy learning on DMC-VB, and we highlight a large representation gap between policies learned on pixel observations and on states. Second, we demonstrate when expert data is limited, policy learning can benefit from representations pretrained on (a) suboptimal data, and (b) tasks with stochastic hidden goals. Our dataset and benchmark code to train and evaluate agents are available at: https://github.com/google-deepmind/dmc_vision_benchmark.
Learning Cognitive Maps from Transformer Representations for Efficient Planning in Partially Observed Environments
Jan 11, 2024Despite their stellar performance on a wide range of tasks, including in-context tasks only revealed during inference, vanilla transformers and variants trained for next-token predictions (a) do not learn an explicit world model of their environment which can be flexibly queried and (b) cannot be used for planning or navigation. In this paper, we consider partially observed environments (POEs), where an agent receives perceptually aliased observations as it navigates, which makes path planning hard. We introduce a transformer with (multiple) discrete bottleneck(s), TDB, whose latent codes learn a compressed representation of the history of observations and actions. After training a TDB to predict the future observation(s) given the history, we extract interpretable cognitive maps of the environment from its active bottleneck(s) indices. These maps are then paired with an external solver to solve (constrained) path planning problems. First, we show that a TDB trained on POEs (a) retains the near perfect predictive performance of a vanilla transformer or an LSTM while (b) solving shortest path problems exponentially faster. Second, a TDB extracts interpretable representations from text datasets, while reaching higher in-context accuracy than vanilla sequence models. Finally, in new POEs, a TDB (a) reaches near-perfect in-context accuracy, (b) learns accurate in-context cognitive maps (c) solves in-context path planning problems.
Multi Loss-based Feature Fusion and Top Two Voting Ensemble Decision Strategy for Facial Expression Recognition in the Wild
Nov 06, 2023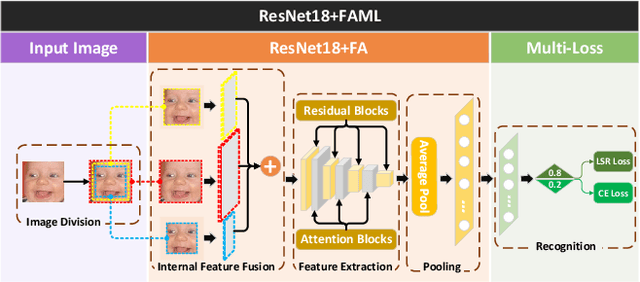
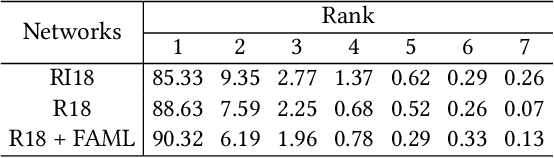
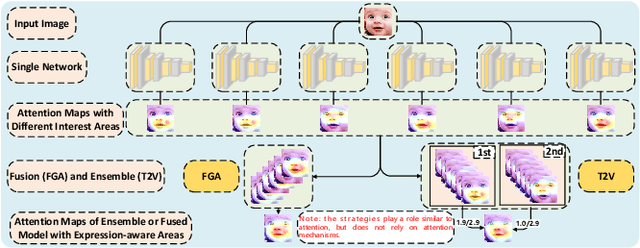
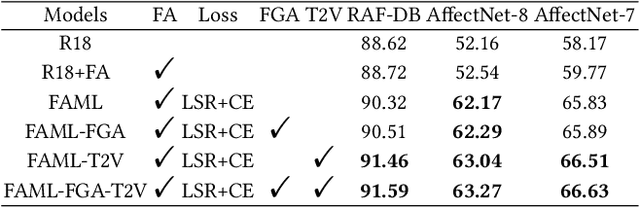
Facial expression recognition (FER) in the wild is a challenging task affected by the image quality and has attracted broad interest in computer vision. There is no research using feature fusion and ensemble strategy for FER simultaneously. Different from previous studies, this paper applies both internal feature fusion for a single model and feature fusion among multiple networks, as well as the ensemble strategy. This paper proposes one novel single model named R18+FAML, as well as one ensemble model named R18+FAML-FGA-T2V to improve the performance of the FER in the wild. Based on the structure of ResNet18 (R18), R18+FAML combines internal Feature fusion and three Attention blocks using Multiple Loss functions (FAML) to improve the diversity of the feature extraction. To improve the performance of R18+FAML, we propose a Feature fusion among networks based on the Genetic Algorithm (FGA), which can fuse the convolution kernels for feature extraction of multiple networks. On the basis of R18+FAML and FGA, we propose one ensemble strategy, i.e., the Top Two Voting (T2V) to support the classification of FER, which can consider more classification information comprehensively. Combining the above strategies, R18+FAML-FGA-T2V can focus on the main expression-aware areas. Extensive experiments demonstrate that our single model R18+FAML and the ensemble model R18+FAML-FGA-T2V achieve the accuracies of $\left( 90.32, 62.17, 65.83 \right)\%$ and $\left( 91.59, 63.27, 66.63 \right)\%$ on three challenging unbalanced FER datasets RAF-DB, AffectNet-8 and AffectNet-7 respectively, both outperforming the state-of-the-art results.
RoboTAP: Tracking Arbitrary Points for Few-Shot Visual Imitation
Aug 31, 2023



For robots to be useful outside labs and specialized factories we need a way to teach them new useful behaviors quickly. Current approaches lack either the generality to onboard new tasks without task-specific engineering, or else lack the data-efficiency to do so in an amount of time that enables practical use. In this work we explore dense tracking as a representational vehicle to allow faster and more general learning from demonstration. Our approach utilizes Track-Any-Point (TAP) models to isolate the relevant motion in a demonstration, and parameterize a low-level controller to reproduce this motion across changes in the scene configuration. We show this results in robust robot policies that can solve complex object-arrangement tasks such as shape-matching, stacking, and even full path-following tasks such as applying glue and sticking objects together, all from demonstrations that can be collected in minutes.
Graph schemas as abstractions for transfer learning, inference, and planning
Feb 14, 2023We propose schemas as a model for abstractions that can be used for rapid transfer learning, inference, and planning. Common structured representations of concepts and behaviors -- schemas -- have been proposed as a powerful way to encode abstractions. Latent graph learning is emerging as a new computational model of the hippocampus to explain map learning and transitive inference. We build on this work to show that learned latent graphs in these models have a slot structure -- schemas -- that allow for quick knowledge transfer across environments. In a new environment, an agent can rapidly learn new bindings between the sensory stream to multiple latent schemas and select the best fitting one to guide behavior. To evaluate these graph schemas, we use two previously published challenging tasks: the memory & planning game and one-shot StreetLearn, that are designed to test rapid task solving in novel environments. Graph schemas can be learned in far fewer episodes than previous baselines, and can model and plan in a few steps in novel variations of these tasks. We further demonstrate learning, matching, and reusing graph schemas in navigation tasks in more challenging environments with aliased observations and size variations, and show how different schemas can be composed to model larger 2D and 3D environments.