 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProToken: Token-Level Attribution for Federated Large Language Models
Jan 27, 2026Federated Learning (FL) enables collaborative training of Large Language Models (LLMs) across distributed data sources while preserving privacy. However, when federated LLMs are deployed in critical applications, it remains unclear which client(s) contributed to specific generated responses, hindering debugging, malicious client identification, fair reward allocation, and trust verification. We present ProToken, a novel Provenance methodology for Token-level attribution in federated LLMs that addresses client attribution during autoregressive text generation while maintaining FL privacy constraints. ProToken leverages two key insights to enable provenance at each token: (1) transformer architectures concentrate task-specific signals in later blocks, enabling strategic layer selection for computational tractability, and (2) gradient-based relevance weighting filters out irrelevant neural activations, focusing attribution on neurons that directly influence token generation. We evaluate ProToken across 16 configurations spanning four LLM architectures (Gemma, Llama, Qwen, SmolLM) and four domains (medical, financial, mathematical, coding). ProToken achieves 98% average attribution accuracy in correctly localizing responsible client(s), and maintains high accuracy when the number of clients are scaled, validating its practical viability for real-world deployment settings.
How Accurately Do Large Language Models Understand Code?
Apr 09, 2025
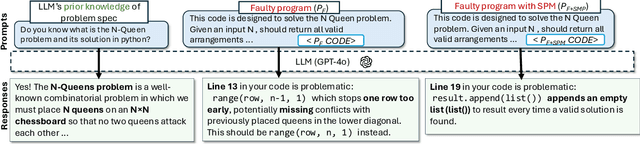


Large Language Models (LLMs) are increasingly used in post-development tasks such as code repair and testing. A key factor in these tasks' success is the model's deep understanding of code. However, the extent to which LLMs truly understand code remains largely unevaluated. Quantifying code comprehension is challenging due to its abstract nature and the lack of a standardized metric. Previously, this was assessed through developer surveys, which are not feasible for evaluating LLMs. Existing LLM benchmarks focus primarily on code generation, fundamentally different from code comprehension. Additionally, fixed benchmarks quickly become obsolete as they become part of the training data. This paper presents the first large-scale empirical investigation into LLMs' ability to understand code. Inspired by mutation testing, we use an LLM's fault-finding ability as a proxy for its deep code understanding. This approach is based on the insight that a model capable of identifying subtle functional discrepancies must understand the code well. We inject faults in real-world programs and ask the LLM to localize them, ensuring the specifications suffice for fault localization. Next, we apply semantic-preserving code mutations (SPMs) to the faulty programs and test whether the LLMs still locate the faults, verifying their confidence in code understanding. We evaluate nine popular LLMs on 600,010 debugging tasks from 670 Java and 637 Python programs. We find that LLMs lose the ability to debug the same bug in 78% of faulty programs when SPMs are applied, indicating a shallow understanding of code and reliance on features irrelevant to semantics. We also find that LLMs understand code earlier in the program better than later. This suggests that LLMs' code comprehension remains tied to lexical and syntactic features due to tokenization designed for natural languages, which overlooks code semantics.
DMC-VB: A Benchmark for Representation Learning for Control with Visual Distractors
Sep 26, 2024



Learning from previously collected data via behavioral cloning or offline reinforcement learning (RL) is a powerful recipe for scaling generalist agents by avoiding the need for expensive online learning. Despite strong generalization in some respects, agents are often remarkably brittle to minor visual variations in control-irrelevant factors such as the background or camera viewpoint. In this paper, we present theDeepMind Control Visual Benchmark (DMC-VB), a dataset collected in the DeepMind Control Suite to evaluate the robustness of offline RL agents for solving continuous control tasks from visual input in the presence of visual distractors. In contrast to prior works, our dataset (a) combines locomotion and navigation tasks of varying difficulties, (b) includes static and dynamic visual variations, (c) considers data generated by policies with different skill levels, (d) systematically returns pairs of state and pixel observation, (e) is an order of magnitude larger, and (f) includes tasks with hidden goals. Accompanying our dataset, we propose three benchmarks to evaluate representation learning methods for pretraining, and carry out experiments on several recently proposed methods. First, we find that pretrained representations do not help policy learning on DMC-VB, and we highlight a large representation gap between policies learned on pixel observations and on states. Second, we demonstrate when expert data is limited, policy learning can benefit from representations pretrained on (a) suboptimal data, and (b) tasks with stochastic hidden goals. Our dataset and benchmark code to train and evaluate agents are available at: https://github.com/google-deepmind/dmc_vision_benchmark.
Low-shot Object Learning with Mutual Exclusivity Bias
Dec 06, 2023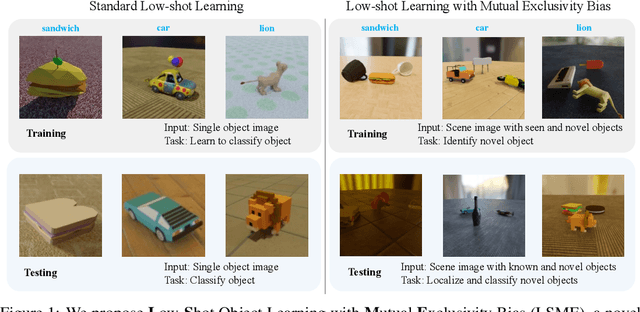

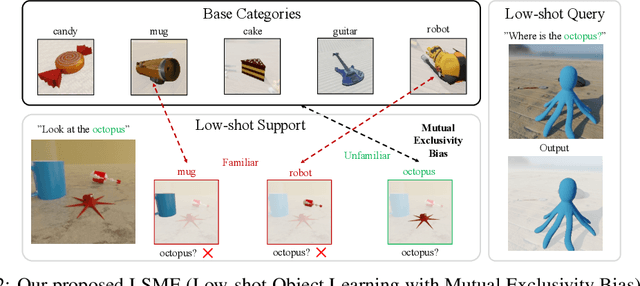
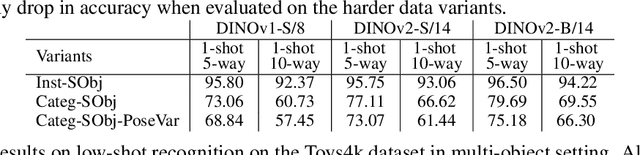
This paper introduces Low-shot Object Learning with Mutual Exclusivity Bias (LSME), the first computational framing of mutual exclusivity bias, a phenomenon commonly observed in infants during word learning. We provide a novel dataset, comprehensive baselines, and a state-of-the-art method to enable the ML community to tackle this challenging learning task. The goal of LSME is to analyze an RGB image of a scene containing multiple objects and correctly associate a previously-unknown object instance with a provided category label. This association is then used to perform low-shot learning to test category generalization. We provide a data generation pipeline for the LSME problem and conduct a thorough analysis of the factors that contribute to its difficulty. Additionally, we evaluate the performance of multiple baselines, including state-of-the-art foundation models. Finally, we present a baseline approach that outperforms state-of-the-art models in terms of low-shot accuracy.
Iterative Machine Teaching
Nov 17, 2017



In this paper, we consider the problem of machine teaching, the inverse problem of machine learning. Different from traditional machine teaching which views the learners as batch algorithms, we study a new paradigm where the learner uses an iterative algorithm and a teacher can feed examples sequentially and intelligently based on the current performance of the learner. We show that the teaching complexity in the iterative case is very different from that in the batch case. Instead of constructing a minimal training set for learners, our iterative machine teaching focuses on achieving fast convergence in the learner model. Depending on the level of information the teacher has from the learner model, we design teaching algorithms which can provably reduce the number of teaching examples and achieve faster convergence than learning without teachers. We also validate our theoretical findings with extensive experiments on different data distribution and real image datasets.
Finding Temporally Consistent Occlusion Boundaries in Videos using Geometric Context
Oct 25, 2015
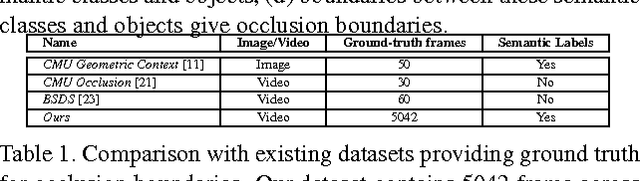
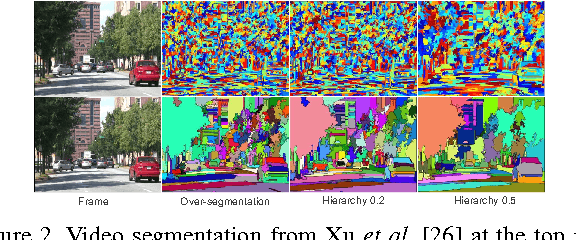

We present an algorithm for finding temporally consistent occlusion boundaries in videos to support segmentation of dynamic scenes. We learn occlusion boundaries in a pairwise Markov random field (MRF) framework. We first estimate the probability of an spatio-temporal edge being an occlusion boundary by using appearance, flow, and geometric features. Next, we enforce occlusion boundary continuity in a MRF model by learning pairwise occlusion probabilities using a random forest. Then, we temporally smooth boundaries to remove temporal inconsistencies in occlusion boundary estimation. Our proposed framework provides an efficient approach for finding temporally consistent occlusion boundaries in video by utilizing causality, redundancy in videos, and semantic layout of the scene. We have developed a dataset with fully annotated ground-truth occlusion boundaries of over 30 videos ($5000 frames). This dataset is used to evaluate temporal occlusion boundaries and provides a much needed baseline for future studies. We perform experiments to demonstrate the role of scene layout, and temporal information for occlusion reasoning in dynamic scenes.