 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFinding Temporally Consistent Occlusion Boundaries in Videos using Geometric Context
Oct 25, 2015
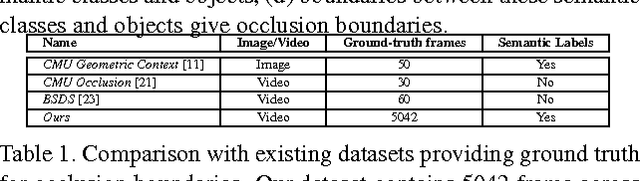

We present an algorithm for finding temporally consistent occlusion boundaries in videos to support segmentation of dynamic scenes. We learn occlusion boundaries in a pairwise Markov random field (MRF) framework. We first estimate the probability of an spatio-temporal edge being an occlusion boundary by using appearance, flow, and geometric features. Next, we enforce occlusion boundary continuity in a MRF model by learning pairwise occlusion probabilities using a random forest. Then, we temporally smooth boundaries to remove temporal inconsistencies in occlusion boundary estimation. Our proposed framework provides an efficient approach for finding temporally consistent occlusion boundaries in video by utilizing causality, redundancy in videos, and semantic layout of the scene. We have developed a dataset with fully annotated ground-truth occlusion boundaries of over 30 videos ($5000 frames). This dataset is used to evaluate temporal occlusion boundaries and provides a much needed baseline for future studies. We perform experiments to demonstrate the role of scene layout, and temporal information for occlusion reasoning in dynamic scenes.
Geometric Context from Videos
Oct 25, 2015
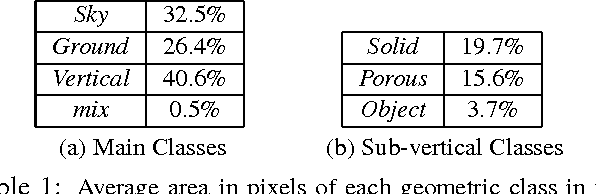
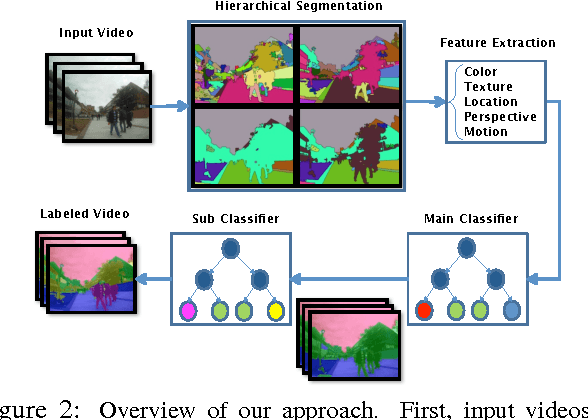

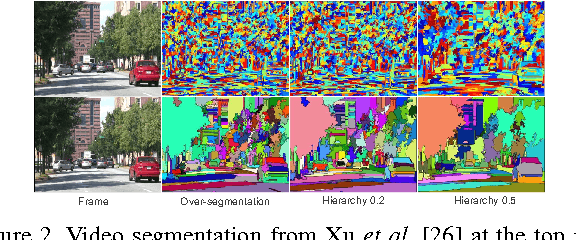
We present a novel algorithm for estimating the broad 3D geometric structure of outdoor video scenes. Leveraging spatio-temporal video segmentation, we decompose a dynamic scene captured by a video into geometric classes, based on predictions made by region-classifiers that are trained on appearance and motion features. By examining the homogeneity of the prediction, we combine predictions across multiple segmentation hierarchy levels alleviating the need to determine the granularity a priori. We built a novel, extensive dataset on geometric context of video to evaluate our method, consisting of over 100 ground-truth annotated outdoor videos with over 20,000 frames. To further scale beyond this dataset, we propose a semi-supervised learning framework to expand the pool of labeled data with high confidence predictions obtained from unlabeled data. Our system produces an accurate prediction of geometric context of video achieving 96% accuracy across main geometric classes.
Depth Extraction from Videos Using Geometric Context and Occlusion Boundaries
Oct 25, 2015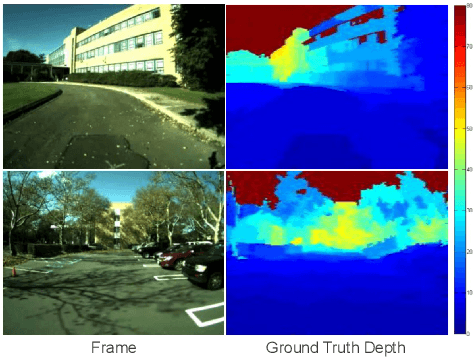
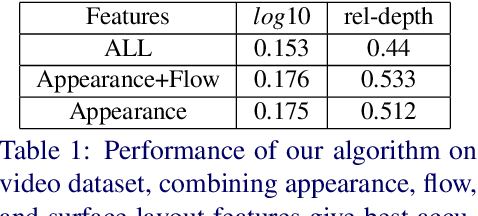

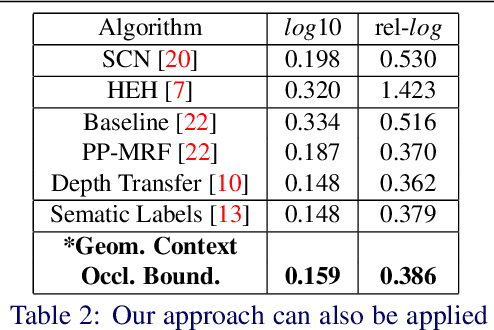
We present an algorithm to estimate depth in dynamic video scenes. We propose to learn and infer depth in videos from appearance, motion, occlusion boundaries, and geometric context of the scene. Using our method, depth can be estimated from unconstrained videos with no requirement of camera pose estimation, and with significant background/foreground motions. We start by decomposing a video into spatio-temporal regions. For each spatio-temporal region, we learn the relationship of depth to visual appearance, motion, and geometric classes. Then we infer the depth information of new scenes using piecewise planar parametrization estimated within a Markov random field (MRF) framework by combining appearance to depth learned mappings and occlusion boundary guided smoothness constraints. Subsequently, we perform temporal smoothing to obtain temporally consistent depth maps. To evaluate our depth estimation algorithm, we provide a novel dataset with ground truth depth for outdoor video scenes. We present a thorough evaluation of our algorithm on our new dataset and the publicly available Make3d static image dataset.