 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePaging Dr. GPT: Extracting Information from Clinical Notes to Enhance Patient Predictions
Apr 14, 2025There is a long history of building predictive models in healthcare using tabular data from electronic medical records. However, these models fail to extract the information found in unstructured clinical notes, which document diagnosis, treatment, progress, medications, and care plans. In this study, we investigate how answers generated by GPT-4o-mini (ChatGPT) to simple clinical questions about patients, when given access to the patient's discharge summary, can support patient-level mortality prediction. Using data from 14,011 first-time admissions to the Coronary Care or Cardiovascular Intensive Care Units in the MIMIC-IV Note dataset, we implement a transparent framework that uses GPT responses as input features in logistic regression models. Our findings demonstrate that GPT-based models alone can outperform models trained on standard tabular data, and that combining both sources of information yields even greater predictive power, increasing AUC by an average of 5.1 percentage points and increasing positive predictive value by 29.9 percent for the highest-risk decile. These results highlight the value of integrating large language models (LLMs) into clinical prediction tasks and underscore the broader potential for using LLMs in any domain where unstructured text data remains an underutilized resource.
Stone Soup Multi-Target Tracking Feature Extraction For Autonomous Search And Track In Deep Reinforcement Learning Environment
Mar 03, 2025Management of sensing resources is a non-trivial problem for future military air assets with future systems deploying heterogeneous sensors to generate information of the battlespace. Machine learning techniques including deep reinforcement learning (DRL) have been identified as promising approaches, but require high-fidelity training environments and feature extractors to generate information for the agent. This paper presents a deep reinforcement learning training approach, utilising the Stone Soup tracking framework as a feature extractor to train an agent for a sensor management task. A general framework for embedding Stone Soup tracker components within a Gymnasium environment is presented, enabling fast and configurable tracker deployments for RL training using Stable Baselines3. The approach is demonstrated in a sensor management task where an agent is trained to search and track a region of airspace utilising track lists generated from Stone Soup trackers. A sample implementation using three neural network architectures in a search-and-track scenario demonstrates the approach and shows that RL agents can outperform simple sensor search and track policies when trained within the Gymnasium and Stone Soup environment.
Recurrent Auto-Encoders for Enhanced Deep Reinforcement Learning in Wilderness Search and Rescue Planning
Feb 26, 2025Wilderness search and rescue operations are often carried out over vast landscapes. The search efforts, however, must be undertaken in minimum time to maximize the chance of survival of the victim. Whilst the advent of cheap multicopters in recent years has changed the way search operations are handled, it has not solved the challenges of the massive areas at hand. The problem therefore is not one of complete coverage, but one of maximizing the information gathered in the limited time available. In this work we propose that a combination of a recurrent autoencoder and deep reinforcement learning is a more efficient solution to the search problem than previous pure deep reinforcement learning or optimisation approaches. The autoencoder training paradigm efficiently maximizes the information throughput of the encoder into its latent space representation which deep reinforcement learning is primed to leverage. Without the overhead of independently solving the problem that the recurrent autoencoder is designed for, it is more efficient in learning the control task. We further implement three additional architectures for a comprehensive comparison of the main proposed architecture. Similarly, we apply both soft actor-critic and proximal policy optimisation to provide an insight into the performance of both in a highly non-linear and complex application with a large observation Results show that the proposed architecture is vastly superior to the benchmarks, with soft actor-critic achieving the best performance. This model further outperformed work from the literature whilst having below a fifth of the total learnable parameters and training in a quarter of the time.
Multi-Target Radar Search and Track Using Sequence-Capable Deep Reinforcement Learning
Feb 19, 2025The research addresses sensor task management for radar systems, focusing on efficiently searching and tracking multiple targets using reinforcement learning. The approach develops a 3D simulation environment with an active electronically scanned array radar, using a multi-target tracking algorithm to improve observation data quality. Three neural network architectures were compared including an approach using fated recurrent units with multi-headed self-attention. Two pre-training techniques were applied: behavior cloning to approximate a random search strategy and an auto-encoder to pre-train the feature extractor. Experimental results revealed that search performance was relatively consistent across most methods. The real challenge emerged in simultaneously searching and tracking targets. The multi-headed self-attention architecture demonstrated the most promising results, highlighting the potential of sequence-capable architectures in handling dynamic tracking scenarios. The key contribution lies in demonstrating how reinforcement learning can optimize sensor management, potentially improving radar systems' ability to identify and track multiple targets in complex environments.
Predictive Probability Density Mapping for Search and Rescue Using An Agent-Based Approach with Sparse Data
Dec 17, 2024Predicting the location where a lost person could be found is crucial for search and rescue operations with limited resources. To improve the precision and efficiency of these predictions, simulated agents can be created to emulate the behavior of the lost person. Within this study, we introduce an innovative agent-based model designed to replicate diverse psychological profiles of lost persons, allowing these agents to navigate real-world landscapes while making decisions autonomously without the need for location-specific training. The probability distribution map depicting the potential location of the lost person emerges through a combination of Monte Carlo simulations and mobility-time-based sampling. Validation of the model is achieved using real-world Search and Rescue data to train a Gaussian Process model. This allows generalization of the data to sample initial starting points for the agents during validation. Comparative analysis with historical data showcases promising outcomes relative to alternative methods. This work introduces a flexible agent that can be employed in search and rescue operations, offering adaptability across various geographical locations.
Modeling Latent Neural Dynamics with Gaussian Process Switching Linear Dynamical Systems
Jul 19, 2024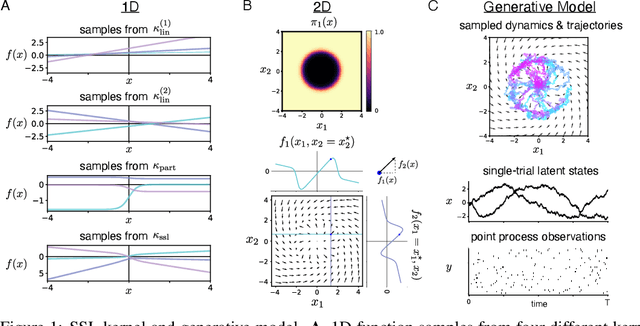
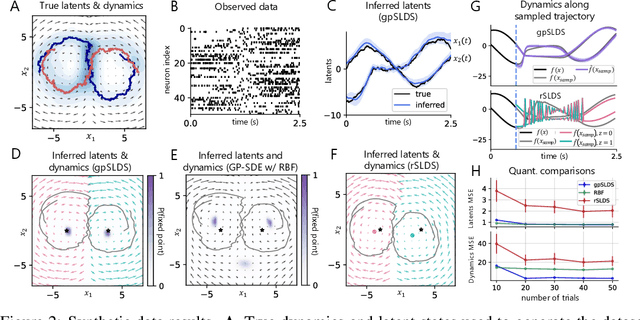
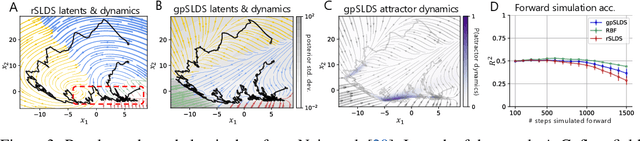
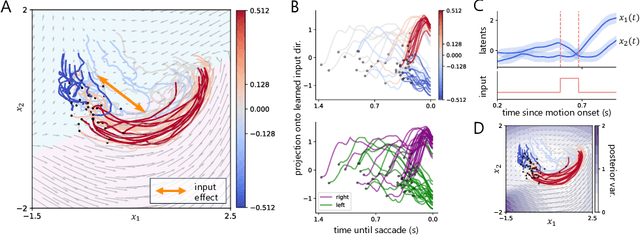
Understanding how the collective activity of neural populations relates to computation and ultimately behavior is a key goal in neuroscience. To this end, statistical methods which describe high-dimensional neural time series in terms of low-dimensional latent dynamics have played a fundamental role in characterizing neural systems. Yet, what constitutes a successful method involves two opposing criteria: (1) methods should be expressive enough to capture complex nonlinear dynamics, and (2) they should maintain a notion of interpretability often only warranted by simpler linear models. In this paper, we develop an approach that balances these two objectives: the Gaussian Process Switching Linear Dynamical System (gpSLDS). Our method builds on previous work modeling the latent state evolution via a stochastic differential equation whose nonlinear dynamics are described by a Gaussian process (GP-SDEs). We propose a novel kernel function which enforces smoothly interpolated locally linear dynamics, and therefore expresses flexible -- yet interpretable -- dynamics akin to those of recurrent switching linear dynamical systems (rSLDS). Our approach resolves key limitations of the rSLDS such as artifactual oscillations in dynamics near discrete state boundaries, while also providing posterior uncertainty estimates of the dynamics. To fit our models, we leverage a modified learning objective which improves the estimation accuracy of kernel hyperparameters compared to previous GP-SDE fitting approaches. We apply our method to synthetic data and data recorded in two neuroscience experiments and demonstrate favorable performance in comparison to the rSLDS.
In-Situ Infrared Camera Monitoring for Defect and Anomaly Detection in Laser Powder Bed Fusion: Calibration, Data Mapping, and Feature Extraction
Jul 17, 2024Laser powder bed fusion (LPBF) process can incur defects due to melt pool instabilities, spattering, temperature increase, and powder spread anomalies. Identifying defects through in-situ monitoring typically requires collecting, storing, and analyzing large amounts of data generated. The first goal of this work is to propose a new approach to accurately map in-situ data to a three-dimensional (3D) geometry, aiming to reduce the amount of storage. The second goal of this work is to introduce several new IR features for defect detection or process model calibration, which include laser scan order, local preheat temperature, maximum pre-laser scanning temperature, and number of spatters generated locally and their landing locations. For completeness, processing of other common IR features, such as interpass temperature, heat intensity, cooling rates, and melt pool area, are also presented with the underlying algorithm and Python implementation. A number of different parts are printed, monitored, and characterized to provide evidence of process defects and anomalies that different IR features are capable of detecting.
Deep Reinforcement Learning for Time-Critical Wilderness Search And Rescue Using Drones
May 22, 2024Traditional search and rescue methods in wilderness areas can be time-consuming and have limited coverage. Drones offer a faster and more flexible solution, but optimizing their search paths is crucial. This paper explores the use of deep reinforcement learning to create efficient search missions for drones in wilderness environments. Our approach leverages a priori data about the search area and the missing person in the form of a probability distribution map. This allows the deep reinforcement learning agent to learn optimal flight paths that maximize the probability of finding the missing person quickly. Experimental results show that our method achieves a significant improvement in search times compared to traditional coverage planning and search planning algorithms. In one comparison, deep reinforcement learning is found to outperform other algorithms by over $160\%$, a difference that can mean life or death in real-world search operations. Additionally, unlike previous work, our approach incorporates a continuous action space enabled by cubature, allowing for more nuanced flight patterns.
A Novel Methodology for Autonomous Planetary Exploration Using Multi-Robot Teams
May 21, 2024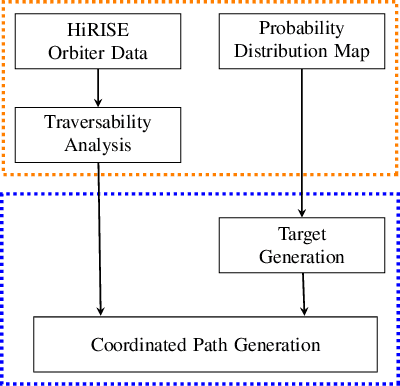



One of the fundamental limiting factors in planetary exploration is the autonomous capabilities of planetary exploration rovers. This study proposes a novel methodology for trustworthy autonomous multi-robot teams which incorporates data from multiple sources (HiRISE orbiter imaging, probability distribution maps, and on-board rover sensors) to find efficient exploration routes in Jezero crater. A map is generated, consisting of a 3D terrain model, traversability analysis, and probability distribution map of points of scientific interest. A three-stage mission planner generates an efficient route, which maximises the accumulated probability of identifying points of interest. A 4D RRT* algorithm is used to determine smooth, flat paths, and prioritised planning is used to coordinate a safe set of paths. The above methodology is shown to coordinate safe and efficient rover paths, which ensure the rovers remain within their nominal pitch and roll limits throughout operation.
Enhancing Reinforcement Learning in Sensor Fusion: A Comparative Analysis of Cubature and Sampling-based Integration Methods for Rover Search Planning
May 15, 2024
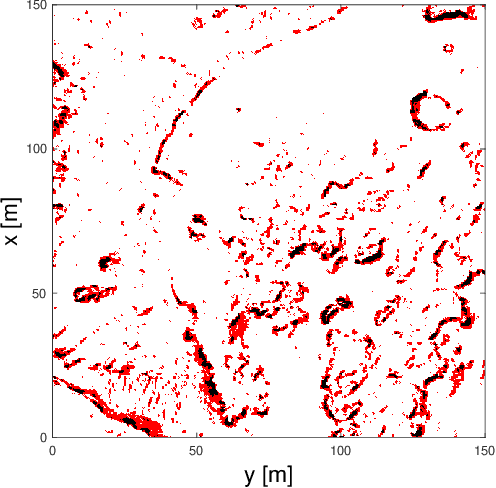
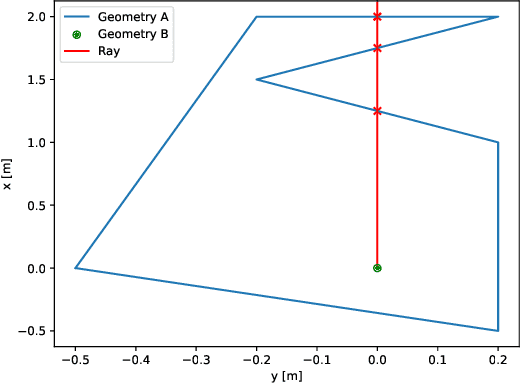
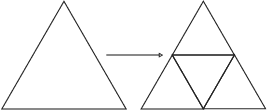
This study investigates the computational speed and accuracy of two numerical integration methods, cubature and sampling-based, for integrating an integrand over a 2D polygon. Using a group of rovers searching the Martian surface with a limited sensor footprint as a test bed, the relative error and computational time are compared as the area was subdivided to improve accuracy in the sampling-based approach. The results show that the sampling-based approach exhibits a $14.75\%$ deviation in relative error compared to cubature when it matches the computational performance at $100\%$. Furthermore, achieving a relative error below $1\%$ necessitates a $10000\%$ increase in relative time to calculate due to the $\mathcal{O}(N^2)$ complexity of the sampling-based method. It is concluded that for enhancing reinforcement learning capabilities and other high iteration algorithms, the cubature method is preferred over the sampling-based method.