 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeometric Context from Videos
Paper and Code
Oct 25, 2015
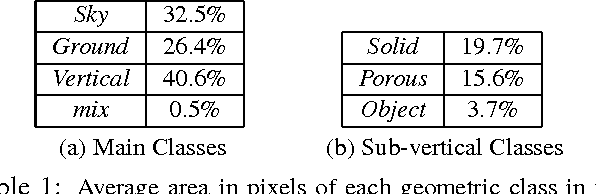
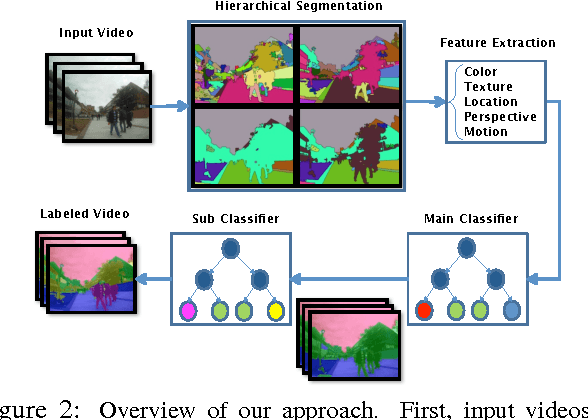

We present a novel algorithm for estimating the broad 3D geometric structure of outdoor video scenes. Leveraging spatio-temporal video segmentation, we decompose a dynamic scene captured by a video into geometric classes, based on predictions made by region-classifiers that are trained on appearance and motion features. By examining the homogeneity of the prediction, we combine predictions across multiple segmentation hierarchy levels alleviating the need to determine the granularity a priori. We built a novel, extensive dataset on geometric context of video to evaluate our method, consisting of over 100 ground-truth annotated outdoor videos with over 20,000 frames. To further scale beyond this dataset, we propose a semi-supervised learning framework to expand the pool of labeled data with high confidence predictions obtained from unlabeled data. Our system produces an accurate prediction of geometric context of video achieving 96% accuracy across main geometric classes.