 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Do I Do That? Synthesizing 3D Hand Motion and Contacts for Everyday Interactions
Apr 16, 2025



We tackle the novel problem of predicting 3D hand motion and contact maps (or Interaction Trajectories) given a single RGB view, action text, and a 3D contact point on the object as input. Our approach consists of (1) Interaction Codebook: a VQVAE model to learn a latent codebook of hand poses and contact points, effectively tokenizing interaction trajectories, (2) Interaction Predictor: a transformer-decoder module to predict the interaction trajectory from test time inputs by using an indexer module to retrieve a latent affordance from the learned codebook. To train our model, we develop a data engine that extracts 3D hand poses and contact trajectories from the diverse HoloAssist dataset. We evaluate our model on a benchmark that is 2.5-10X larger than existing works, in terms of diversity of objects and interactions observed, and test for generalization of the model across object categories, action categories, tasks, and scenes. Experimental results show the effectiveness of our approach over transformer & diffusion baselines across all settings.
A Schema-Guided Reason-while-Retrieve framework for Reasoning on Scene Graphs with Large-Language-Models (LLMs)
Feb 05, 2025



Scene graphs have emerged as a structured and serializable environment representation for grounded spatial reasoning with Large Language Models (LLMs). In this work, we propose SG-RwR, a Schema-Guided Retrieve-while-Reason framework for reasoning and planning with scene graphs. Our approach employs two cooperative, code-writing LLM agents: a (1) Reasoner for task planning and information queries generation, and a (2) Retriever for extracting corresponding graph information following the queries. Two agents collaborate iteratively, enabling sequential reasoning and adaptive attention to graph information. Unlike prior works, both agents are prompted only with the scene graph schema rather than the full graph data, which reduces the hallucination by limiting input tokens, and drives the Reasoner to generate reasoning trace abstractly.Following the trace, the Retriever programmatically query the scene graph data based on the schema understanding, allowing dynamic and global attention on the graph that enhances alignment between reasoning and retrieval. Through experiments in multiple simulation environments, we show that our framework surpasses existing LLM-based approaches in numerical Q\&A and planning tasks, and can benefit from task-level few-shot examples, even in the absence of agent-level demonstrations. Project code will be released.
STEPs: Self-Supervised Key Step Extraction from Unlabeled Procedural Videos
Jan 02, 2023



We address the problem of extracting key steps from unlabeled procedural videos, motivated by the potential of Augmented Reality (AR) headsets to revolutionize job training and performance. We decompose the problem into two steps: representation learning and key steps extraction. We employ self-supervised representation learning via a training strategy that adapts off-the-shelf video features using a temporal module. Training implements self-supervised learning losses involving multiple cues such as appearance, motion and pose trajectories extracted from videos to learn generalizable representations. Our method extracts key steps via a tunable algorithm that clusters the representations extracted from procedural videos. We quantitatively evaluate our approach with key step localization and also demonstrate the effectiveness of the extracted representations on related downstream tasks like phase classification. Qualitative results demonstrate that the extracted key steps are meaningful to succinctly represent the procedural tasks.
Self-supervised Learning with Local Contrastive Loss for Detection and Semantic Segmentation
Jul 10, 2022
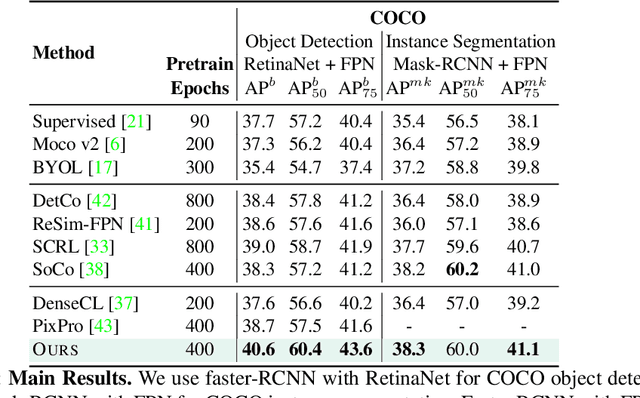
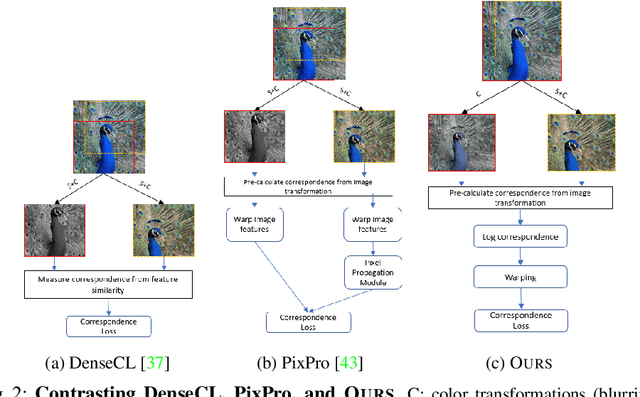
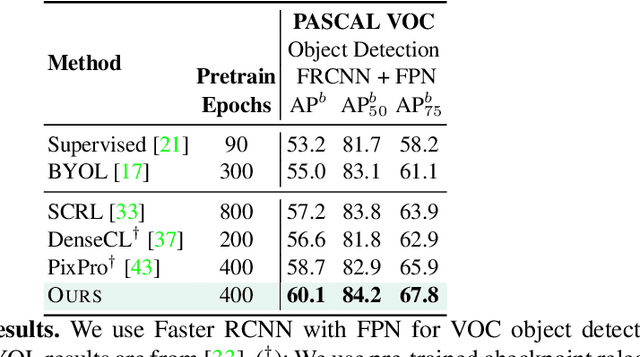
We present a self-supervised learning (SSL) method suitable for semi-global tasks such as object detection and semantic segmentation. We enforce local consistency between self-learned features, representing corresponding image locations of transformed versions of the same image, by minimizing a pixel-level local contrastive (LC) loss during training. LC-loss can be added to existing self-supervised learning methods with minimal overhead. We evaluate our SSL approach on two downstream tasks -- object detection and semantic segmentation, using COCO, PASCAL VOC, and CityScapes datasets. Our method outperforms the existing state-of-the-art SSL approaches by 1.9% on COCO object detection, 1.4% on PASCAL VOC detection, and 0.6% on CityScapes segmentation.
Domain-Specific Priors and Meta Learning for Low-shot First-Person Action Recognition
Jul 22, 2019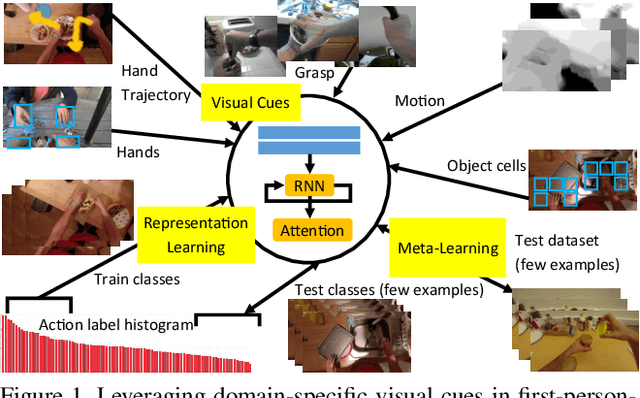

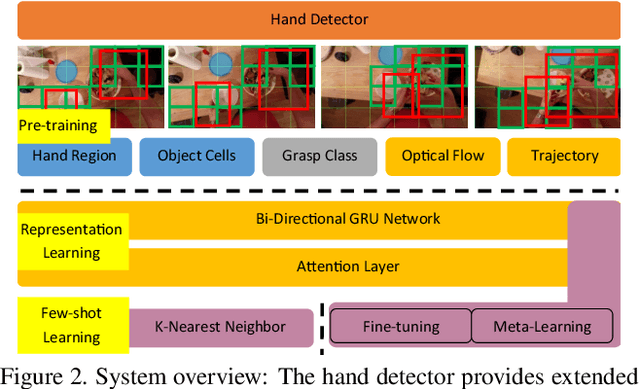
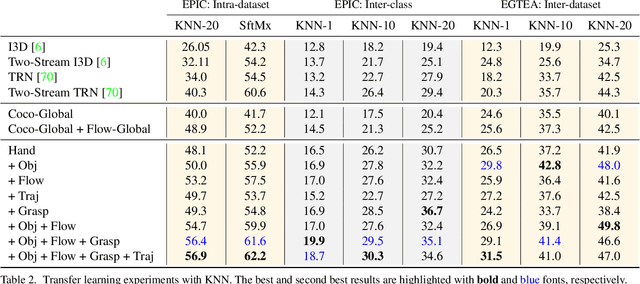
The lack of large-scale real datasets with annotationsmakes transfer learning a necessity for video activity under-standing. Within this scope, we aim at developing an effec-tive method for low-shot transfer learning for first-personaction classification. We leverage independently trained lo-cal visual cues to learn representations that can be trans-ferred from a source domain providing primitive action la-bels to a target domain with only a handful of examples.Such visual cues include object-object interactions, handgrasps and motion within regions that are a function of handlocations. We suggest a framework based on meta-learningto appropriately extract the distinctive and domain invari-ant components of the deployed visual cues, so to be able totransfer action classification models across public datasetscaptured with different scene configurations. We thoroughlyevaluate our methodology and report promising results overstate-of-the-art action classification approaches for bothinter-class and inter-dataset transfer.
Zero-Shot Event Detection by Multimodal Distributional Semantic Embedding of Videos
Dec 16, 2015



We propose a new zero-shot Event Detection method by Multi-modal Distributional Semantic embedding of videos. Our model embeds object and action concepts as well as other available modalities from videos into a distributional semantic space. To our knowledge, this is the first Zero-Shot event detection model that is built on top of distributional semantics and extends it in the following directions: (a) semantic embedding of multimodal information in videos (with focus on the visual modalities), (b) automatically determining relevance of concepts/attributes to a free text query, which could be useful for other applications, and (c) retrieving videos by free text event query (e.g., "changing a vehicle tire") based on their content. We embed videos into a distributional semantic space and then measure the similarity between videos and the event query in a free text form. We validated our method on the large TRECVID MED (Multimedia Event Detection) challenge. Using only the event title as a query, our method outperformed the state-of-the-art that uses big descriptions from 12.6% to 13.5% with MAP metric and 0.73 to 0.83 with ROC-AUC metric. It is also an order of magnitude faster.
Depth Extraction from Videos Using Geometric Context and Occlusion Boundaries
Oct 25, 2015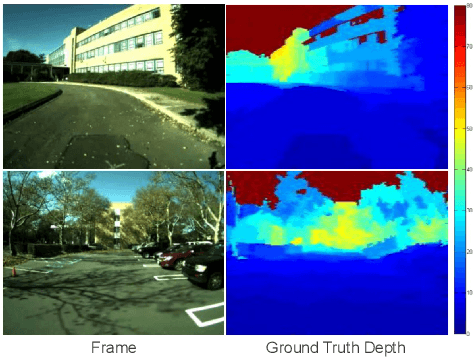
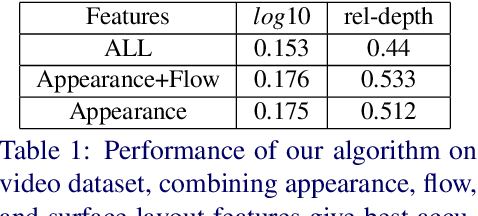

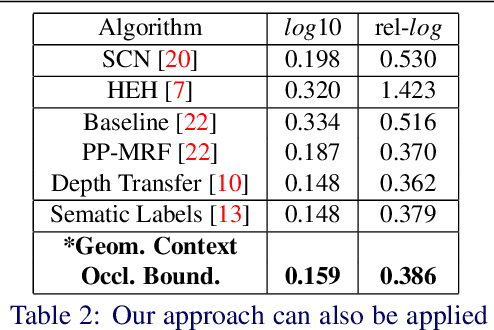
We present an algorithm to estimate depth in dynamic video scenes. We propose to learn and infer depth in videos from appearance, motion, occlusion boundaries, and geometric context of the scene. Using our method, depth can be estimated from unconstrained videos with no requirement of camera pose estimation, and with significant background/foreground motions. We start by decomposing a video into spatio-temporal regions. For each spatio-temporal region, we learn the relationship of depth to visual appearance, motion, and geometric classes. Then we infer the depth information of new scenes using piecewise planar parametrization estimated within a Markov random field (MRF) framework by combining appearance to depth learned mappings and occlusion boundary guided smoothness constraints. Subsequently, we perform temporal smoothing to obtain temporally consistent depth maps. To evaluate our depth estimation algorithm, we provide a novel dataset with ground truth depth for outdoor video scenes. We present a thorough evaluation of our algorithm on our new dataset and the publicly available Make3d static image dataset.