 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHierarchical Policy Learning via Spectral Decomposition
Jun 28, 2026In this paper, we identify a semantic decomposition in robot action sequences, separating task-level motion intent from execution-level refinements. By analyzing actions in the spectral domain using the discrete cosine transform (DCT), we observe that low-frequency components capture global motion trajectories, while high-frequency components encode precise timing, alignment, and contact behaviors. Motivated by this structure, we propose Causal Spectral Policy (CSP), which models action generation as a causal coarse-to-fine process: coarse motion is predicted from observation and language, and fine corrections are generated conditionally on the realized trajectory. Across simulation and real-world evaluations, CSP consistently outperforms strong baselines on precision-sensitive manipulation tasks. Additionally, we propose human-inspired teleoperation noise injection as a data augmentation method, under which our approach demonstrates strong robustness to noisy demonstrations.
VISTA: Enhancing Visual Conditioning via Track-Following Preference Optimization in Vision-Language-Action Models
Feb 04, 2026Vision-Language-Action (VLA) models have demonstrated strong performance across a wide range of robotic manipulation tasks. Despite the success, extending large pretrained Vision-Language Models (VLMs) to the action space can induce vision-action misalignment, where action predictions exhibit weak dependence on the current visual state, leading to unreliable action outputs. In this work, we study VLA models through the lens of visual conditioning and empirically show that successful rollouts consistently exhibit stronger visual dependence than failed ones. Motivated by this observation, we propose a training framework that explicitly strengthens visual conditioning in VLA models. Our approach first aligns action prediction with visual input via preference optimization on a track-following surrogate task, and then transfers the enhanced alignment to instruction-following task through latent-space distillation during supervised finetuning. Without introducing architectural modifications or additional data collection, our method improves both visual conditioning and task performance for discrete OpenVLA, and further yields consistent gains when extended to the continuous OpenVLA-OFT setting. Project website: https://vista-vla.github.io/ .
OS-Marathon: Benchmarking Computer-Use Agents on Long-Horizon Repetitive Tasks
Jan 28, 2026Long-horizon, repetitive workflows are common in professional settings, such as processing expense reports from receipts and entering student grades from exam papers. These tasks are often tedious for humans since they can extend to extreme lengths proportional to the size of the data to process. However, they are ideal for Computer-Use Agents (CUAs) due to their structured, recurring sub-workflows with logic that can be systematically learned. Identifying the absence of an evaluation benchmark as a primary bottleneck, we establish OS-Marathon, comprising 242 long-horizon, repetitive tasks across 2 domains to evaluate state-of-the-art (SOTA) agents. We then introduce a cost-effective method to construct a condensed demonstration using only few-shot examples to teach agents the underlying workflow logic, enabling them to execute similar workflows effectively on larger, unseen data collections. Extensive experiments demonstrate both the inherent challenges of these tasks and the effectiveness of our proposed method. Project website: https://os-marathon.github.io/.
A Schema-Guided Reason-while-Retrieve framework for Reasoning on Scene Graphs with Large-Language-Models (LLMs)
Feb 05, 2025



Scene graphs have emerged as a structured and serializable environment representation for grounded spatial reasoning with Large Language Models (LLMs). In this work, we propose SG-RwR, a Schema-Guided Retrieve-while-Reason framework for reasoning and planning with scene graphs. Our approach employs two cooperative, code-writing LLM agents: a (1) Reasoner for task planning and information queries generation, and a (2) Retriever for extracting corresponding graph information following the queries. Two agents collaborate iteratively, enabling sequential reasoning and adaptive attention to graph information. Unlike prior works, both agents are prompted only with the scene graph schema rather than the full graph data, which reduces the hallucination by limiting input tokens, and drives the Reasoner to generate reasoning trace abstractly.Following the trace, the Retriever programmatically query the scene graph data based on the schema understanding, allowing dynamic and global attention on the graph that enhances alignment between reasoning and retrieval. Through experiments in multiple simulation environments, we show that our framework surpasses existing LLM-based approaches in numerical Q\&A and planning tasks, and can benefit from task-level few-shot examples, even in the absence of agent-level demonstrations. Project code will be released.
GASP: Gaussian Avatars with Synthetic Priors
Dec 10, 2024



Gaussian Splatting has changed the game for real-time photo-realistic rendering. One of the most popular applications of Gaussian Splatting is to create animatable avatars, known as Gaussian Avatars. Recent works have pushed the boundaries of quality and rendering efficiency but suffer from two main limitations. Either they require expensive multi-camera rigs to produce avatars with free-view rendering, or they can be trained with a single camera but only rendered at high quality from this fixed viewpoint. An ideal model would be trained using a short monocular video or image from available hardware, such as a webcam, and rendered from any view. To this end, we propose GASP: Gaussian Avatars with Synthetic Priors. To overcome the limitations of existing datasets, we exploit the pixel-perfect nature of synthetic data to train a Gaussian Avatar prior. By fitting this prior model to a single photo or video and fine-tuning it, we get a high-quality Gaussian Avatar, which supports 360$^\circ$ rendering. Our prior is only required for fitting, not inference, enabling real-time application. Through our method, we obtain high-quality, animatable Avatars from limited data which can be animated and rendered at 70fps on commercial hardware. See our project page (https://microsoft.github.io/GASP/) for results.
Planning with Sequence Models through Iterative Energy Minimization
Mar 28, 2023Recent works have shown that sequence modeling can be effectively used to train reinforcement learning (RL) policies. However, the success of applying existing sequence models to planning, in which we wish to obtain a trajectory of actions to reach some goal, is less straightforward. The typical autoregressive generation procedures of sequence models preclude sequential refinement of earlier steps, which limits the effectiveness of a predicted plan. In this paper, we suggest an approach towards integrating planning with sequence models based on the idea of iterative energy minimization, and illustrate how such a procedure leads to improved RL performance across different tasks. We train a masked language model to capture an implicit energy function over trajectories of actions, and formulate planning as finding a trajectory of actions with minimum energy. We illustrate how this procedure enables improved performance over recent approaches across BabyAI and Atari environments. We further demonstrate unique benefits of our iterative optimization procedure, involving new task generalization, test-time constraints adaptation, and the ability to compose plans together. Project website: https://hychen-naza.github.io/projects/LEAP
WDiscOOD: Out-of-Distribution Detection via Whitened Linear Discriminant Analysis
Mar 22, 2023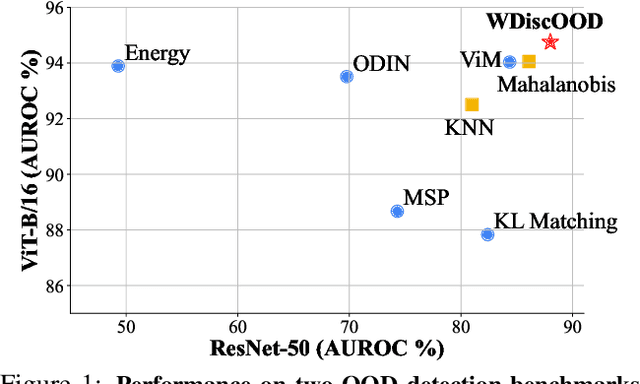
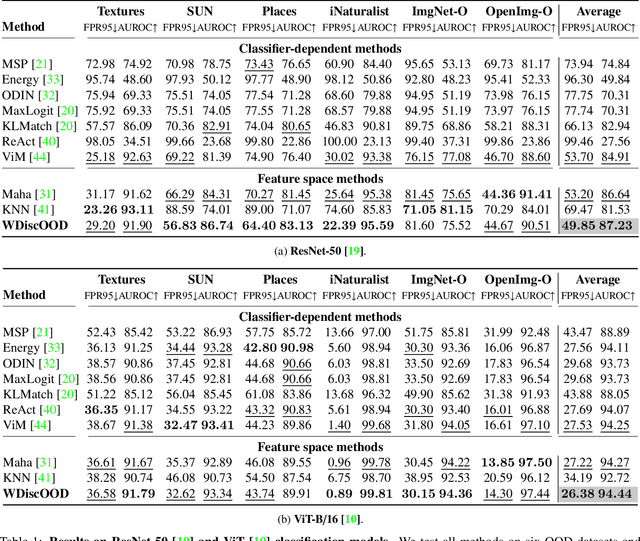
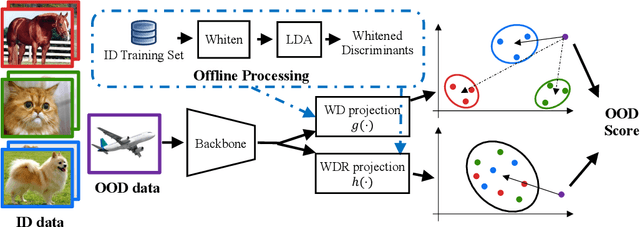

Deep neural networks are susceptible to generating overconfident yet erroneous predictions when presented with data beyond known concepts. This challenge underscores the importance of detecting out-of-distribution (OOD) samples in the open world. In this work, we propose a novel feature-space OOD detection score that jointly reasons with both class-specific and class-agnostic information. Specifically, our approach utilizes Whitened Linear Discriminant Analysis to project features into two subspaces - the discriminative and residual subspaces - in which the ID classes are maximally separated and closely clustered, respectively. The OOD score is then determined by combining the deviation from the input data to the ID distribution in both subspaces. The efficacy of our method, named WDiscOOD, is verified on the large-scale ImageNet-1k benchmark, with six OOD datasets that covers a variety of distribution shifts. WDiscOOD demonstrates superior performance on deep classifiers with diverse backbone architectures, including CNN and vision transformer. Furthermore, we also show that our method can more effectively detect novel concepts in representation space trained with contrastive objectives, including supervised contrastive loss and multi-modality contrastive loss.
KGNv2: Separating Scale and Pose Prediction for Keypoint-based 6-DoF Grasp Synthesis on RGB-D input
Mar 16, 2023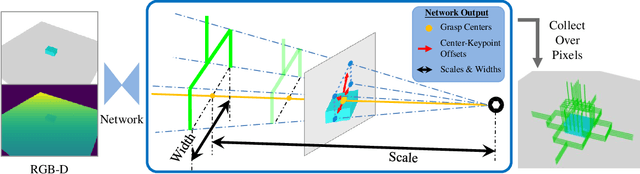
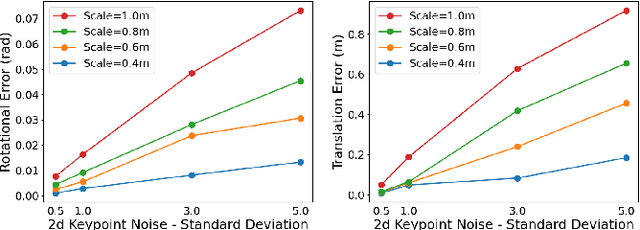
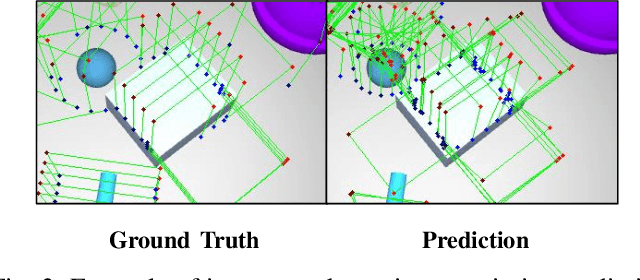

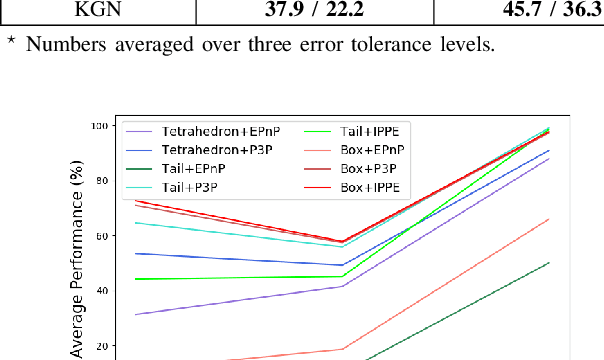
We propose a new 6-DoF grasp pose synthesis approach from 2D/2.5D input based on keypoints. Keypoint-based grasp detector from image input has demonstrated promising results in the previous study, where the additional visual information provided by color images compensates for the noisy depth perception. However, it relies heavily on accurately predicting the location of keypoints in the image space. In this paper, we devise a new grasp generation network that reduces the dependency on precise keypoint estimation. Given an RGB-D input, our network estimates both the grasp pose from keypoint detection as well as scale towards the camera. We further re-design the keypoint output space in order to mitigate the negative impact of keypoint prediction noise to Perspective-n-Point (PnP) algorithm. Experiments show that the proposed method outperforms the baseline by a large margin, validating the efficacy of our approach. Finally, despite trained on simple synthetic objects, our method demonstrate sim-to-real capacity by showing competitive results in real-world robot experiments.
Keypoint-GraspNet: Keypoint-based 6-DoF Grasp Generation from the Monocular RGB-D input
Sep 19, 2022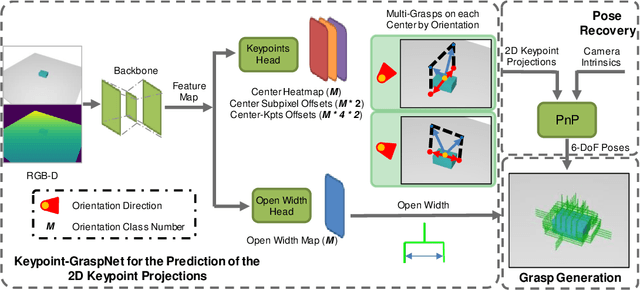
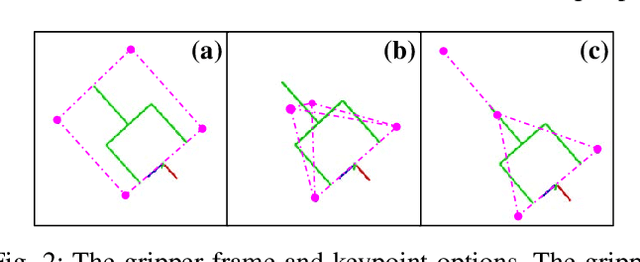
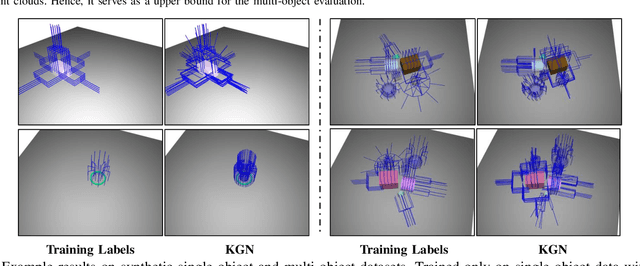
Great success has been achieved in the 6-DoF grasp learning from the point cloud input, yet the computational cost due to the point set orderlessness remains a concern. Alternatively, we explore the grasp generation from the RGB-D input in this paper. The proposed solution, Keypoint-GraspNet, detects the projection of the gripper keypoints in the image space and then recover the SE(3) poses with a PnP algorithm. A synthetic dataset based on the primitive shape and the grasp family is constructed to examine our idea. Metric-based evaluation reveals that our method outperforms the baselines in terms of the grasp proposal accuracy, diversity, and the time cost. Finally, robot experiments show high success rate, demonstrating the potential of the idea in the real-world applications.
A Joint Network for Grasp Detection Conditioned on Natural Language Commands
Apr 01, 2021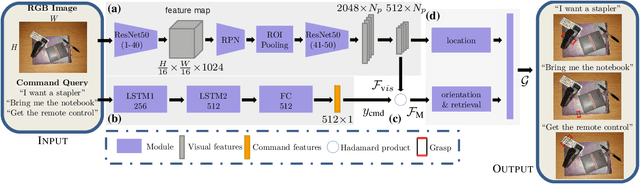

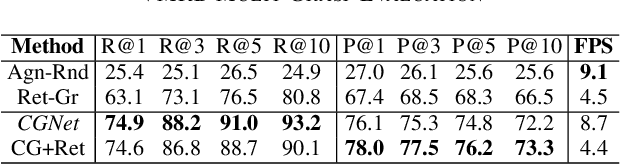
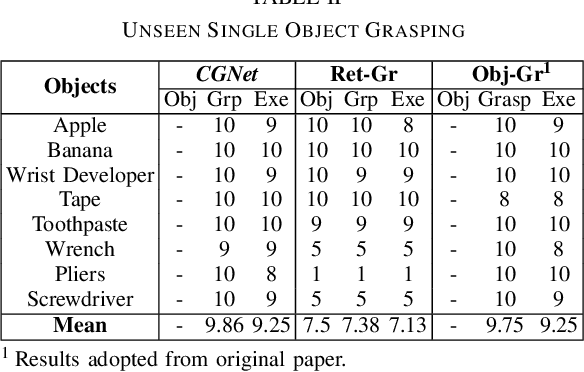
We consider the task of grasping a target object based on a natural language command query. Previous work primarily focused on localizing the object given the query, which requires a separate grasp detection module to grasp it. The cascaded application of two pipelines incurs errors in overlapping multi-object cases due to ambiguity in the individual outputs. This work proposes a model named Command Grasping Network(CGNet) to directly output command satisficing grasps from RGB image and textual command inputs. A dataset with ground truth (image, command, grasps) tuple is generated based on the VMRD dataset to train the proposed network. Experimental results on the generated test set show that CGNet outperforms a cascaded object-retrieval and grasp detection baseline by a large margin. Three physical experiments demonstrate the functionality and performance of CGNet.