 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCEMG: Collaborative-Enhanced Multimodal Generative Recommendation
Dec 25, 2025Generative recommendation models often struggle with two key challenges: (1) the superficial integration of collaborative signals, and (2) the decoupled fusion of multimodal features. These limitations hinder the creation of a truly holistic item representation. To overcome this, we propose CEMG, a novel Collaborative-Enhaned Multimodal Generative Recommendation framework. Our approach features a Multimodal Fusion Layer that dynamically integrates visual and textual features under the guidance of collaborative signals. Subsequently, a Unified Modality Tokenization stage employs a Residual Quantization VAE (RQ-VAE) to convert this fused representation into discrete semantic codes. Finally, in the End-to-End Generative Recommendation stage, a large language model is fine-tuned to autoregressively generate these item codes. Extensive experiments demonstrate that CEMG significantly outperforms state-of-the-art baselines.
PID-controlled Langevin Dynamics for Faster Sampling of Generative Models
Nov 16, 2025Langevin dynamics sampling suffers from extremely low generation speed, fundamentally limited by numerous fine-grained iterations to converge to the target distribution. We introduce PID-controlled Langevin Dynamics (PIDLD), a novel sampling acceleration algorithm that reinterprets the sampling process using control-theoretic principles. By treating energy gradients as feedback signals, PIDLD combines historical gradients (the integral term) and gradient trends (the derivative term) to efficiently traverse energy landscapes and adaptively stabilize, thereby significantly reducing the number of iterations required to produce high-quality samples. Our approach requires no additional training, datasets, or prior information, making it immediately integrable with any Langevin-based method. Extensive experiments across image generation and reasoning tasks demonstrate that PIDLD achieves higher quality with fewer steps, making Langevin-based generative models more practical for efficiency-critical applications. The implementation can be found at \href{https://github.com/tsinghua-fib-lab/PIDLD}{https://github.com/tsinghua-fib-lab/PIDLD}.
Research on Multi-hop Inference Optimization of LLM Based on MQUAKE Framework
Sep 05, 2025Accurately answering complex questions has consistently been a significant challenge for Large Language Models (LLMs). To address this, this paper proposes a multi-hop question decomposition method for complex questions, building upon research within the MQUAKE framework. Utilizing the LLAMA3 model, we systematically investigate the impact of multi-hop question decomposition within knowledge graphs on model comprehension and reasoning accuracy, both before and after model training. In our experiments, we systematically partitioned and converted the MQUAKE-T dataset into two distinct formats: a single-hop dataset designed for directly answering complex questions, and a multi-hop dataset constructed using the multi-hop question decomposition method. We then fine-tuned the LLAMA3 model on these datasets and conducted inference tests. Our results demonstrate that, without fine-tuning the LLM, the prediction performance based on the multi-hop question decomposition method significantly outperforms the method of directly answering complex questions. After fine-tuning using the LoRA (Low-Rank Adaptation) method, the performance of both approaches improved compared to the untrained baseline. Crucially, the method utilizing multi-hop decomposition consistently maintained its superiority. These findings validate the effectiveness of the multi-hop decomposition method both before and after training, demonstrating its capability to effectively enhance the LLM's ability to answer complex questions.
RPD-Diff: Region-Adaptive Physics-Guided Diffusion Model for Visibility Enhancement under Dense and Non-Uniform Haze
Aug 23, 2025Single-image dehazing under dense and non-uniform haze conditions remains challenging due to severe information degradation and spatial heterogeneity. Traditional diffusion-based dehazing methods struggle with insufficient generation conditioning and lack of adaptability to spatially varying haze distributions, which leads to suboptimal restoration. To address these limitations, we propose RPD-Diff, a Region-adaptive Physics-guided Dehazing Diffusion Model for robust visibility enhancement in complex haze scenarios. RPD-Diff introduces a Physics-guided Intermediate State Targeting (PIST) strategy, which leverages physical priors to reformulate the diffusion Markov chain by generation target transitions, mitigating the issue of insufficient conditioning in dense haze scenarios. Additionally, the Haze-Aware Denoising Timestep Predictor (HADTP) dynamically adjusts patch-specific denoising timesteps employing a transmission map cross-attention mechanism, adeptly managing non-uniform haze distributions. Extensive experiments across four real-world datasets demonstrate that RPD-Diff achieves state-of-the-art performance in challenging dense and non-uniform haze scenarios, delivering high-quality, haze-free images with superior detail clarity and color fidelity.
Web2Grasp: Learning Functional Grasps from Web Images of Hand-Object Interactions
May 07, 2025Functional grasp is essential for enabling dexterous multi-finger robot hands to manipulate objects effectively. However, most prior work either focuses on power grasping, which simply involves holding an object still, or relies on costly teleoperated robot demonstrations to teach robots how to grasp each object functionally. Instead, we propose extracting human grasp information from web images since they depict natural and functional object interactions, thereby bypassing the need for curated demonstrations. We reconstruct human hand-object interaction (HOI) 3D meshes from RGB images, retarget the human hand to multi-finger robot hands, and align the noisy object mesh with its accurate 3D shape. We show that these relatively low-quality HOI data from inexpensive web sources can effectively train a functional grasping model. To further expand the grasp dataset for seen and unseen objects, we use the initially-trained grasping policy with web data in the IsaacGym simulator to generate physically feasible grasps while preserving functionality. We train the grasping model on 10 object categories and evaluate it on 9 unseen objects, including challenging items such as syringes, pens, spray bottles, and tongs, which are underrepresented in existing datasets. The model trained on the web HOI dataset, achieving a 75.8% success rate on seen objects and 61.8% across all objects in simulation, with a 6.7% improvement in success rate and a 1.8x increase in functionality ratings over baselines. Simulator-augmented data further boosts performance from 61.8% to 83.4%. The sim-to-real transfer to the LEAP Hand achieves a 85% success rate. Project website is at: https://webgrasp.github.io/.
A Survey of Large Language Model-Powered Spatial Intelligence Across Scales: Advances in Embodied Agents, Smart Cities, and Earth Science
Apr 14, 2025Over the past year, the development of large language models (LLMs) has brought spatial intelligence into focus, with much attention on vision-based embodied intelligence. However, spatial intelligence spans a broader range of disciplines and scales, from navigation and urban planning to remote sensing and earth science. What are the differences and connections between spatial intelligence across these fields? In this paper, we first review human spatial cognition and its implications for spatial intelligence in LLMs. We then examine spatial memory, knowledge representations, and abstract reasoning in LLMs, highlighting their roles and connections. Finally, we analyze spatial intelligence across scales -- from embodied to urban and global levels -- following a framework that progresses from spatial memory and understanding to spatial reasoning and intelligence. Through this survey, we aim to provide insights into interdisciplinary spatial intelligence research and inspire future studies.
Structure-prior Informed Diffusion Model for Graph Source Localization with Limited Data
Feb 25, 2025The source localization problem in graph information propagation is crucial for managing various network disruptions, from misinformation spread to infrastructure failures. While recent deep generative approaches have shown promise in this domain, their effectiveness is limited by the scarcity of real-world propagation data. This paper introduces SIDSL (\textbf{S}tructure-prior \textbf{I}nformed \textbf{D}iffusion model for \textbf{S}ource \textbf{L}ocalization), a novel framework that addresses three key challenges in limited-data scenarios: unknown propagation patterns, complex topology-propagation relationships, and class imbalance between source and non-source nodes. SIDSL incorporates topology-aware priors through graph label propagation and employs a propagation-enhanced conditional denoiser with a GNN-parameterized label propagation module (GNN-LP). Additionally, we propose a structure-prior biased denoising scheme that initializes from structure-based source estimations rather than random noise, effectively countering class imbalance issues. Experimental results across four real-world datasets demonstrate SIDSL's superior performance, achieving 7.5-13.3% improvements in F1 scores compared to state-of-the-art methods. Notably, when pretrained with simulation data of synthetic patterns, SIDSL maintains robust performance with only 10% of training data, surpassing baselines by more than 18.8%. These results highlight SIDSL's effectiveness in real-world applications where labeled data is scarce.
Sample-efficient diffusion-based control of complex nonlinear systems
Feb 25, 2025Complex nonlinear system control faces challenges in achieving sample-efficient, reliable performance. While diffusion-based methods have demonstrated advantages over classical and reinforcement learning approaches in long-term control performance, they are limited by sample efficiency. This paper presents SEDC (Sample-Efficient Diffusion-based Control), a novel diffusion-based control framework addressing three core challenges: high-dimensional state-action spaces, nonlinear system dynamics, and the gap between non-optimal training data and near-optimal control solutions. Through three innovations - Decoupled State Diffusion, Dual-Mode Decomposition, and Guided Self-finetuning - SEDC achieves 39.5\%-49.4\% better control accuracy than baselines while using only 10\% of the training samples, as validated across three complex nonlinear dynamic systems. Our approach represents a significant advancement in sample-efficient control of complex nonlinear systems. The implementation of the code can be found at https://anonymous.4open.science/r/DIFOCON-C019.
MCSFF: Multi-modal Consistency and Specificity Fusion Framework for Entity Alignment
Oct 18, 2024



Multi-modal entity alignment (MMEA) is essential for enhancing knowledge graphs and improving information retrieval and question-answering systems. Existing methods often focus on integrating modalities through their complementarity but overlook the specificity of each modality, which can obscure crucial features and reduce alignment accuracy. To solve this, we propose the Multi-modal Consistency and Specificity Fusion Framework (MCSFF), which innovatively integrates both complementary and specific aspects of modalities. We utilize Scale Computing's hyper-converged infrastructure to optimize IT management and resource allocation in large-scale data processing. Our framework first computes similarity matrices for each modality using modality embeddings to preserve their unique characteristics. Then, an iterative update method denoises and enhances modality features to fully express critical information. Finally, we integrate the updated information from all modalities to create enriched and precise entity representations. Experiments show our method outperforms current state-of-the-art MMEA baselines on the MMKG dataset, demonstrating its effectiveness and practical potential.
Automating Robot Failure Recovery Using Vision-Language Models With Optimized Prompts
Sep 06, 2024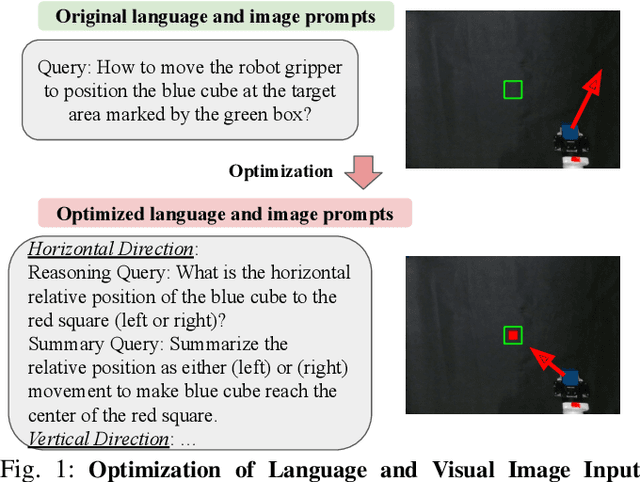
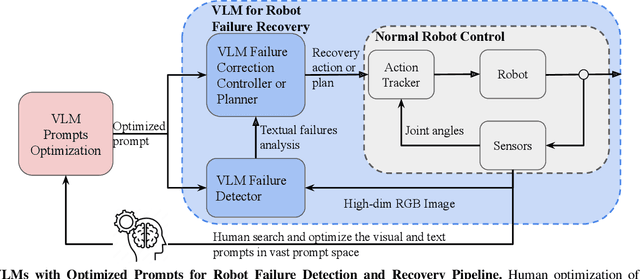
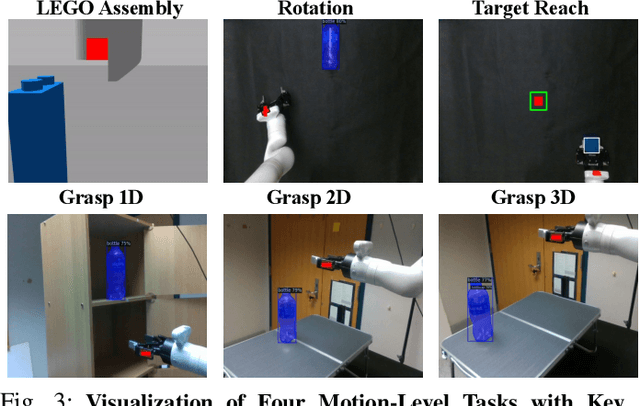

Current robot autonomy struggles to operate beyond the assumed Operational Design Domain (ODD), the specific set of conditions and environments in which the system is designed to function, while the real-world is rife with uncertainties that may lead to failures. Automating recovery remains a significant challenge. Traditional methods often rely on human intervention to manually address failures or require exhaustive enumeration of failure cases and the design of specific recovery policies for each scenario, both of which are labor-intensive. Foundational Vision-Language Models (VLMs), which demonstrate remarkable common-sense generalization and reasoning capabilities, have broader, potentially unbounded ODDs. However, limitations in spatial reasoning continue to be a common challenge for many VLMs when applied to robot control and motion-level error recovery. In this paper, we investigate how optimizing visual and text prompts can enhance the spatial reasoning of VLMs, enabling them to function effectively as black-box controllers for both motion-level position correction and task-level recovery from unknown failures. Specifically, the optimizations include identifying key visual elements in visual prompts, highlighting these elements in text prompts for querying, and decomposing the reasoning process for failure detection and control generation. In experiments, prompt optimizations significantly outperform pre-trained Vision-Language-Action Models in correcting motion-level position errors and improve accuracy by 65.78% compared to VLMs with unoptimized prompts. Additionally, for task-level failures, optimized prompts enhanced the success rate by 5.8%, 5.8%, and 7.5% in VLMs' abilities to detect failures, analyze issues, and generate recovery plans, respectively, across a wide range of unknown errors in Lego assembly.