 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKOROL: Learning Visualizable Object Feature with Koopman Operator Rollout for Manipulation
Jun 29, 2024Learning dexterous manipulation skills presents significant challenges due to complex nonlinear dynamics that underlie the interactions between objects and multi-fingered hands. Koopman operators have emerged as a robust method for modeling such nonlinear dynamics within a linear framework. However, current methods rely on runtime access to ground-truth (GT) object states, making them unsuitable for vision-based practical applications. Unlike image-to-action policies that implicitly learn visual features for control, we use a dynamics model, specifically the Koopman operator, to learn visually interpretable object features critical for robotic manipulation within a scene. We construct a Koopman operator using object features predicted by a feature extractor and utilize it to auto-regressively advance system states. We train the feature extractor to embed scene information into object features, thereby enabling the accurate propagation of robot trajectories. We evaluate our approach on simulated and real-world robot tasks, with results showing that it outperformed the model-based imitation learning NDP by 1.08$\times$ and the image-to-action Diffusion Policy by 1.16$\times$. The results suggest that our method maintains task success rates with learned features and extends applicability to real-world manipulation without GT object states.
Listen Then See: Video Alignment with Speaker Attention
Apr 21, 2024



Video-based Question Answering (Video QA) is a challenging task and becomes even more intricate when addressing Socially Intelligent Question Answering (SIQA). SIQA requires context understanding, temporal reasoning, and the integration of multimodal information, but in addition, it requires processing nuanced human behavior. Furthermore, the complexities involved are exacerbated by the dominance of the primary modality (text) over the others. Thus, there is a need to help the task's secondary modalities to work in tandem with the primary modality. In this work, we introduce a cross-modal alignment and subsequent representation fusion approach that achieves state-of-the-art results (82.06\% accuracy) on the Social IQ 2.0 dataset for SIQA. Our approach exhibits an improved ability to leverage the video modality by using the audio modality as a bridge with the language modality. This leads to enhanced performance by reducing the prevalent issue of language overfitting and resultant video modality bypassing encountered by current existing techniques. Our code and models are publicly available at https://github.com/sts-vlcc/sts-vlcc
On the (In)Feasibility of Attribute Inference Attacks on Machine Learning Models
Mar 12, 2021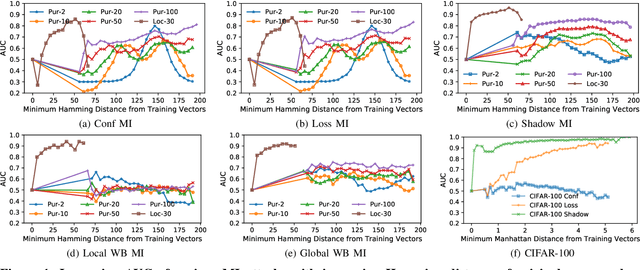
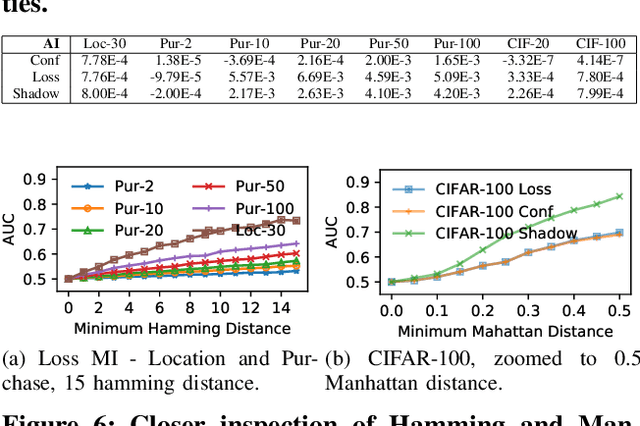
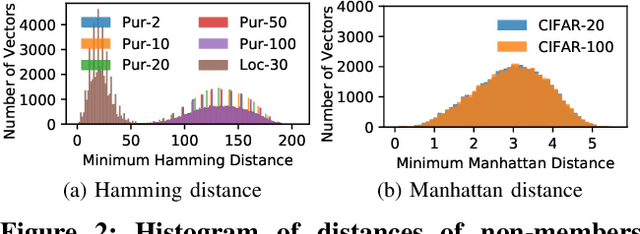
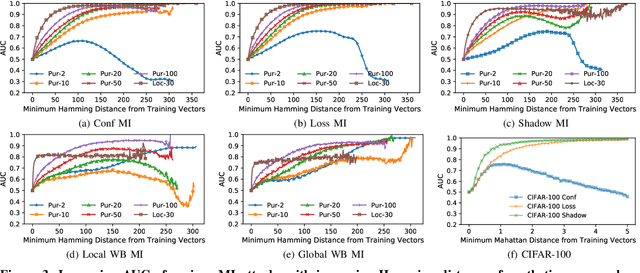
With an increase in low-cost machine learning APIs, advanced machine learning models may be trained on private datasets and monetized by providing them as a service. However, privacy researchers have demonstrated that these models may leak information about records in the training dataset via membership inference attacks. In this paper, we take a closer look at another inference attack reported in literature, called attribute inference, whereby an attacker tries to infer missing attributes of a partially known record used in the training dataset by accessing the machine learning model as an API. We show that even if a classification model succumbs to membership inference attacks, it is unlikely to be susceptible to attribute inference attacks. We demonstrate that this is because membership inference attacks fail to distinguish a member from a nearby non-member. We call the ability of an attacker to distinguish the two (similar) vectors as strong membership inference. We show that membership inference attacks cannot infer membership in this strong setting, and hence inferring attributes is infeasible. However, under a relaxed notion of attribute inference, called approximate attribute inference, we show that it is possible to infer attributes close to the true attributes. We verify our results on three publicly available datasets, five membership, and three attribute inference attacks reported in literature.