 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the (In)Feasibility of Attribute Inference Attacks on Machine Learning Models
Mar 12, 2021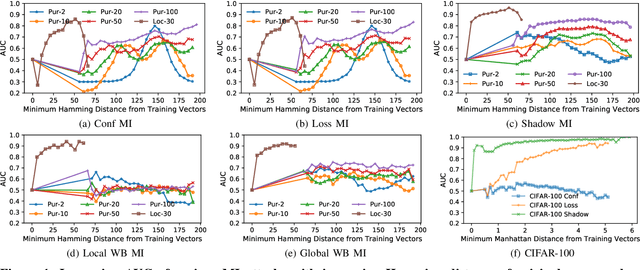
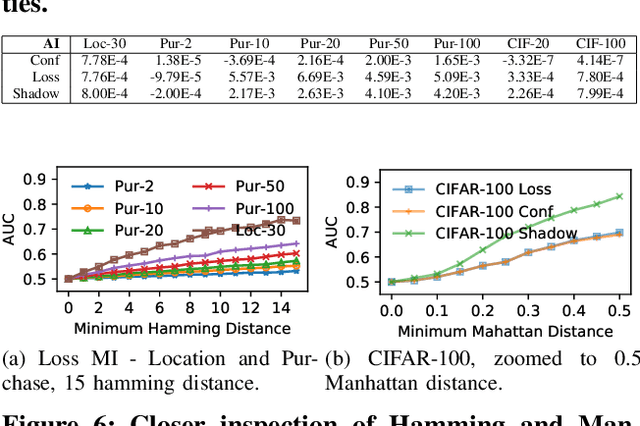
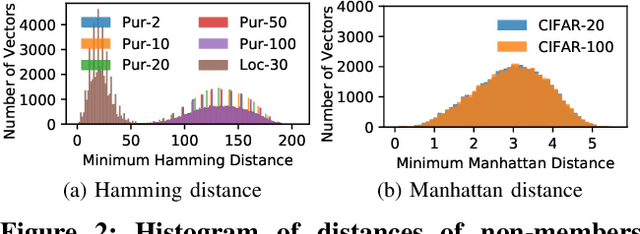
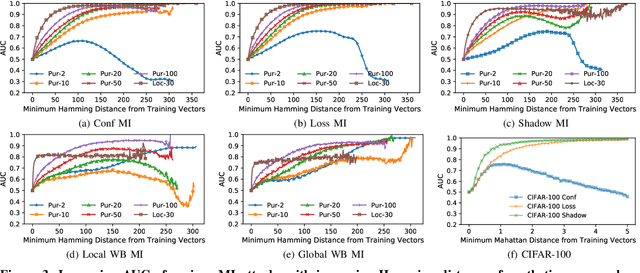
With an increase in low-cost machine learning APIs, advanced machine learning models may be trained on private datasets and monetized by providing them as a service. However, privacy researchers have demonstrated that these models may leak information about records in the training dataset via membership inference attacks. In this paper, we take a closer look at another inference attack reported in literature, called attribute inference, whereby an attacker tries to infer missing attributes of a partially known record used in the training dataset by accessing the machine learning model as an API. We show that even if a classification model succumbs to membership inference attacks, it is unlikely to be susceptible to attribute inference attacks. We demonstrate that this is because membership inference attacks fail to distinguish a member from a nearby non-member. We call the ability of an attacker to distinguish the two (similar) vectors as strong membership inference. We show that membership inference attacks cannot infer membership in this strong setting, and hence inferring attributes is infeasible. However, under a relaxed notion of attribute inference, called approximate attribute inference, we show that it is possible to infer attributes close to the true attributes. We verify our results on three publicly available datasets, five membership, and three attribute inference attacks reported in literature.
On Inferring Training Data Attributes in Machine Learning Models
Aug 28, 2019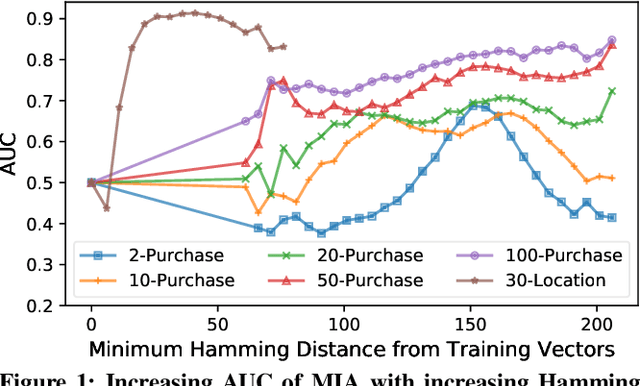


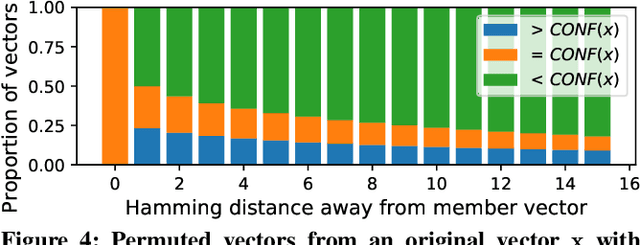
A number of recent works have demonstrated that API access to machine learning models leaks information about the dataset records used to train the models. Further, the work of \cite{somesh-overfit} shows that such membership inference attacks (MIAs) may be sufficient to construct a stronger breed of attribute inference attacks (AIAs), which given a partial view of a record can guess the missing attributes. In this work, we show (to the contrary) that MIA may not be sufficient to build a successful AIA. This is because the latter requires the ability to distinguish between similar records (differing only in a few attributes), and, as we demonstrate, the current breed of MIA are unsuccessful in distinguishing member records from similar non-member records. We thus propose a relaxed notion of AIA, whose goal is to only approximately guess the missing attributes and argue that such an attack is more likely to be successful, if MIA is to be used as a subroutine for inferring training record attributes.