 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomating Robot Failure Recovery Using Vision-Language Models With Optimized Prompts
Paper and Code
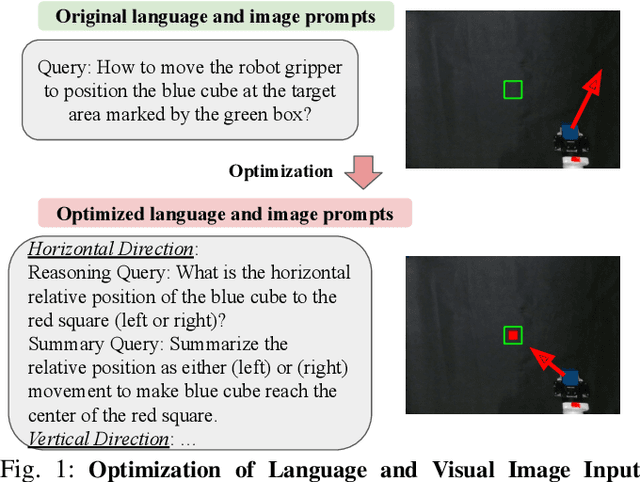
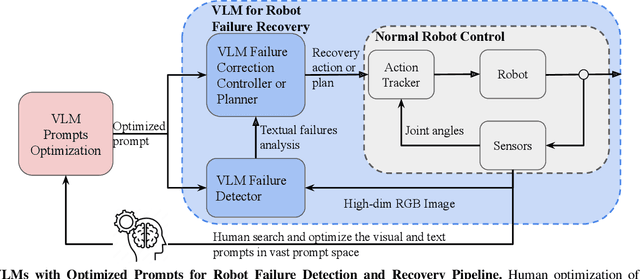
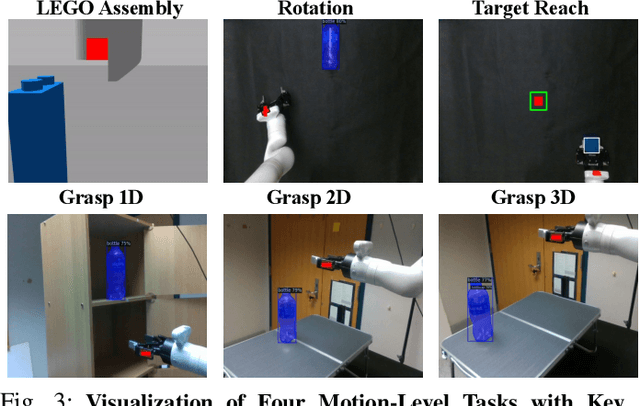

Current robot autonomy struggles to operate beyond the assumed Operational Design Domain (ODD), the specific set of conditions and environments in which the system is designed to function, while the real-world is rife with uncertainties that may lead to failures. Automating recovery remains a significant challenge. Traditional methods often rely on human intervention to manually address failures or require exhaustive enumeration of failure cases and the design of specific recovery policies for each scenario, both of which are labor-intensive. Foundational Vision-Language Models (VLMs), which demonstrate remarkable common-sense generalization and reasoning capabilities, have broader, potentially unbounded ODDs. However, limitations in spatial reasoning continue to be a common challenge for many VLMs when applied to robot control and motion-level error recovery. In this paper, we investigate how optimizing visual and text prompts can enhance the spatial reasoning of VLMs, enabling them to function effectively as black-box controllers for both motion-level position correction and task-level recovery from unknown failures. Specifically, the optimizations include identifying key visual elements in visual prompts, highlighting these elements in text prompts for querying, and decomposing the reasoning process for failure detection and control generation. In experiments, prompt optimizations significantly outperform pre-trained Vision-Language-Action Models in correcting motion-level position errors and improve accuracy by 65.78% compared to VLMs with unoptimized prompts. Additionally, for task-level failures, optimized prompts enhanced the success rate by 5.8%, 5.8%, and 7.5% in VLMs' abilities to detect failures, analyze issues, and generate recovery plans, respectively, across a wide range of unknown errors in Lego assembly.