 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOmniPose6D: Towards Short-Term Object Pose Tracking in Dynamic Scenes from Monocular RGB
Oct 09, 2024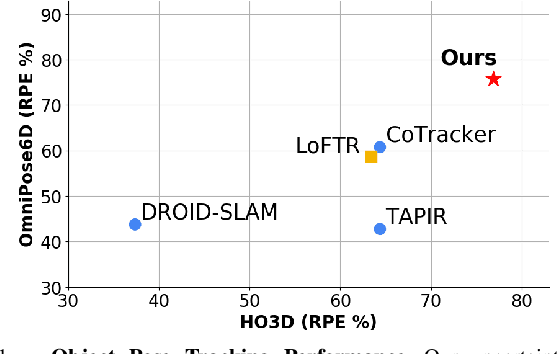

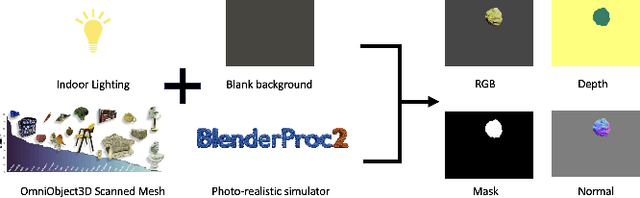
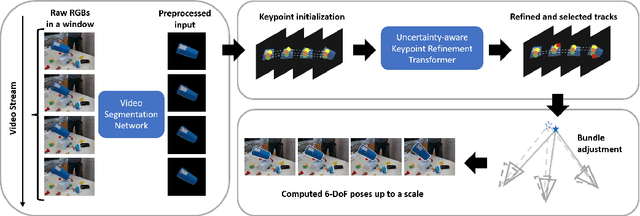
To address the challenge of short-term object pose tracking in dynamic environments with monocular RGB input, we introduce a large-scale synthetic dataset OmniPose6D, crafted to mirror the diversity of real-world conditions. We additionally present a benchmarking framework for a comprehensive comparison of pose tracking algorithms. We propose a pipeline featuring an uncertainty-aware keypoint refinement network, employing probabilistic modeling to refine pose estimation. Comparative evaluations demonstrate that our approach achieves performance superior to existing baselines on real datasets, underscoring the effectiveness of our synthetic dataset and refinement technique in enhancing tracking precision in dynamic contexts. Our contributions set a new precedent for the development and assessment of object pose tracking methodologies in complex scenes.
WDiscOOD: Out-of-Distribution Detection via Whitened Linear Discriminant Analysis
Mar 22, 2023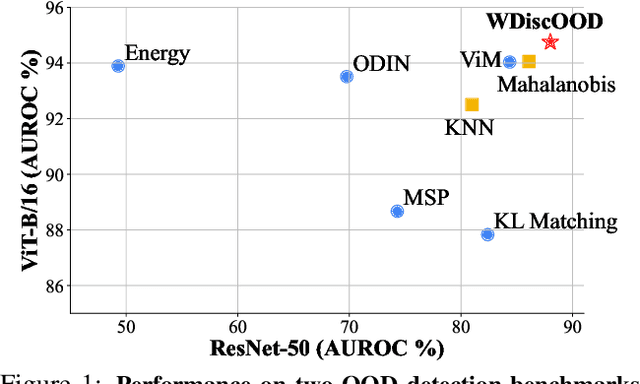
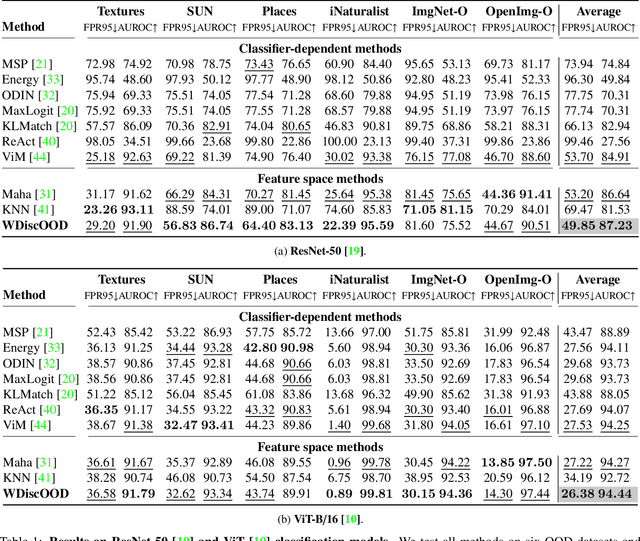
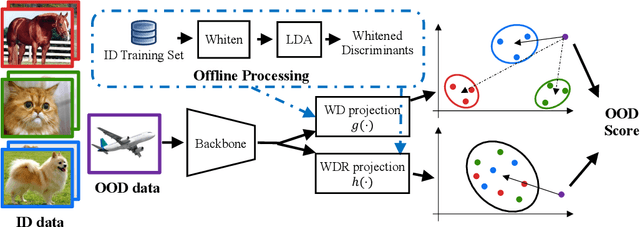

Deep neural networks are susceptible to generating overconfident yet erroneous predictions when presented with data beyond known concepts. This challenge underscores the importance of detecting out-of-distribution (OOD) samples in the open world. In this work, we propose a novel feature-space OOD detection score that jointly reasons with both class-specific and class-agnostic information. Specifically, our approach utilizes Whitened Linear Discriminant Analysis to project features into two subspaces - the discriminative and residual subspaces - in which the ID classes are maximally separated and closely clustered, respectively. The OOD score is then determined by combining the deviation from the input data to the ID distribution in both subspaces. The efficacy of our method, named WDiscOOD, is verified on the large-scale ImageNet-1k benchmark, with six OOD datasets that covers a variety of distribution shifts. WDiscOOD demonstrates superior performance on deep classifiers with diverse backbone architectures, including CNN and vision transformer. Furthermore, we also show that our method can more effectively detect novel concepts in representation space trained with contrastive objectives, including supervised contrastive loss and multi-modality contrastive loss.
KGNv2: Separating Scale and Pose Prediction for Keypoint-based 6-DoF Grasp Synthesis on RGB-D input
Mar 16, 2023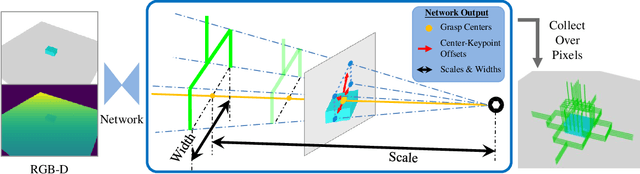
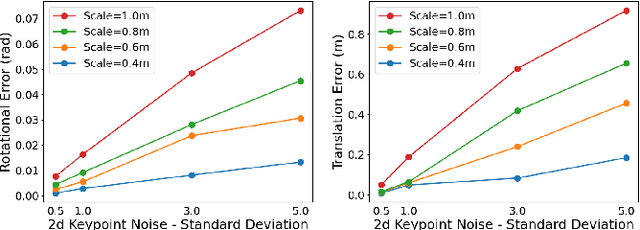
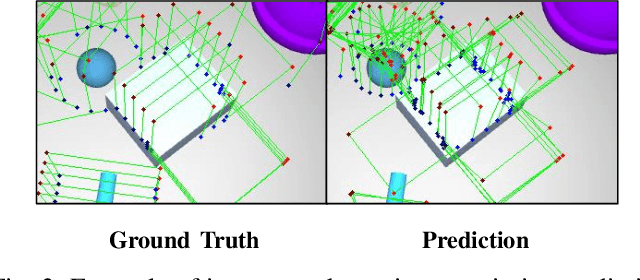

We propose a new 6-DoF grasp pose synthesis approach from 2D/2.5D input based on keypoints. Keypoint-based grasp detector from image input has demonstrated promising results in the previous study, where the additional visual information provided by color images compensates for the noisy depth perception. However, it relies heavily on accurately predicting the location of keypoints in the image space. In this paper, we devise a new grasp generation network that reduces the dependency on precise keypoint estimation. Given an RGB-D input, our network estimates both the grasp pose from keypoint detection as well as scale towards the camera. We further re-design the keypoint output space in order to mitigate the negative impact of keypoint prediction noise to Perspective-n-Point (PnP) algorithm. Experiments show that the proposed method outperforms the baseline by a large margin, validating the efficacy of our approach. Finally, despite trained on simple synthetic objects, our method demonstrate sim-to-real capacity by showing competitive results in real-world robot experiments.
Parallel Inversion of Neural Radiance Fields for Robust Pose Estimation
Oct 18, 2022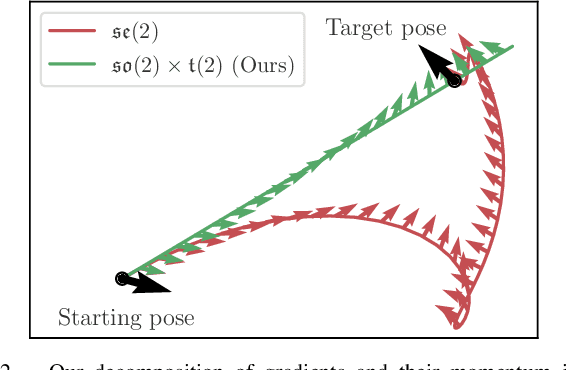
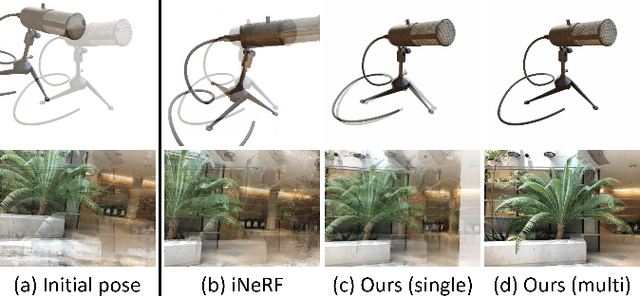
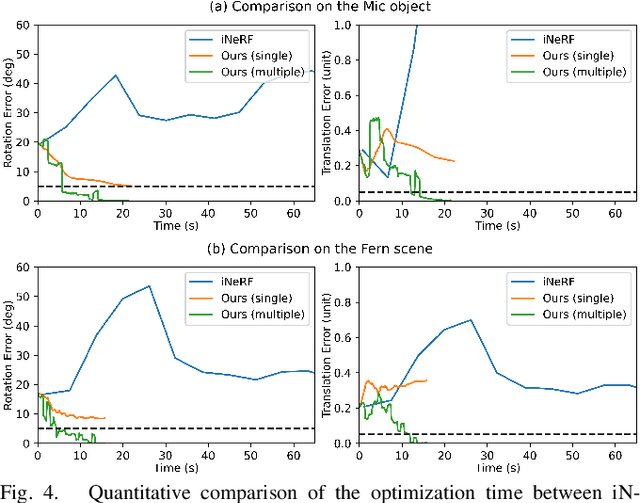

We present a parallelized optimization method based on fast Neural Radiance Fields (NeRF) for estimating 6-DoF target poses. Given a single observed RGB image of the target, we can predict the translation and rotation of the camera by minimizing the residual between pixels rendered from a fast NeRF model and pixels in the observed image. We integrate a momentum-based camera extrinsic optimization procedure into Instant Neural Graphics Primitives, a recent exceptionally fast NeRF implementation. By introducing parallel Monte Carlo sampling into the pose estimation task, our method overcomes local minima and improves efficiency in a more extensive search space. We also show the importance of adopting a more robust pixel-based loss function to reduce error. Experiments demonstrate that our method can achieve improved generalization and robustness on both synthetic and real-world benchmarks.
Keypoint-GraspNet: Keypoint-based 6-DoF Grasp Generation from the Monocular RGB-D input
Sep 19, 2022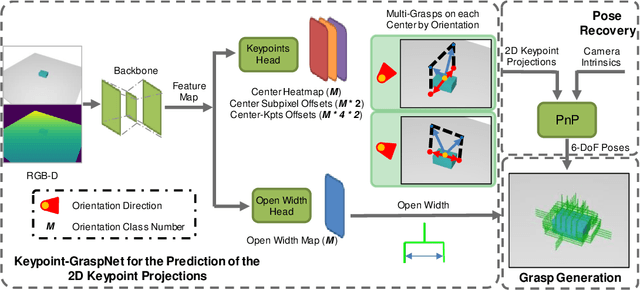
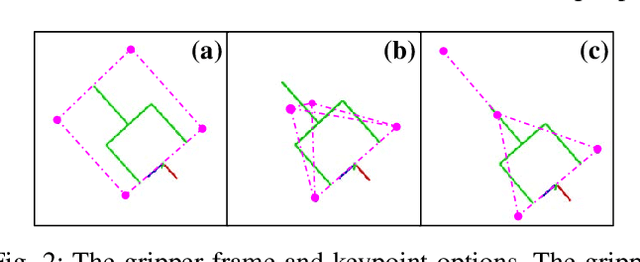
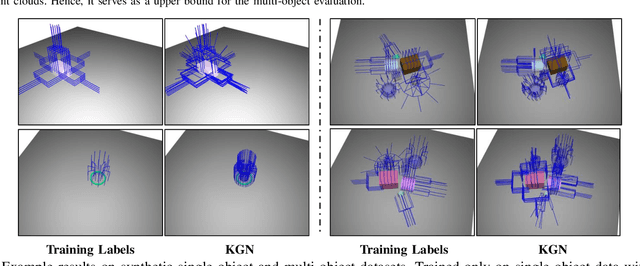
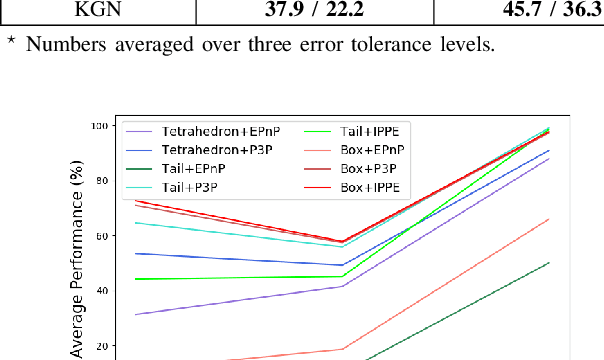
Great success has been achieved in the 6-DoF grasp learning from the point cloud input, yet the computational cost due to the point set orderlessness remains a concern. Alternatively, we explore the grasp generation from the RGB-D input in this paper. The proposed solution, Keypoint-GraspNet, detects the projection of the gripper keypoints in the image space and then recover the SE(3) poses with a PnP algorithm. A synthetic dataset based on the primitive shape and the grasp family is constructed to examine our idea. Metric-based evaluation reveals that our method outperforms the baselines in terms of the grasp proposal accuracy, diversity, and the time cost. Finally, robot experiments show high success rate, demonstrating the potential of the idea in the real-world applications.
Keypoint-Based Category-Level Object Pose Tracking from an RGB Sequence with Uncertainty Estimation
May 23, 2022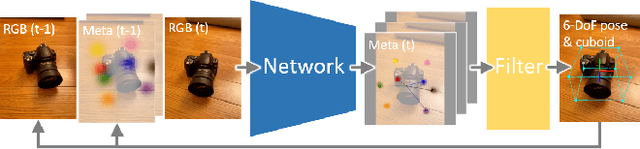
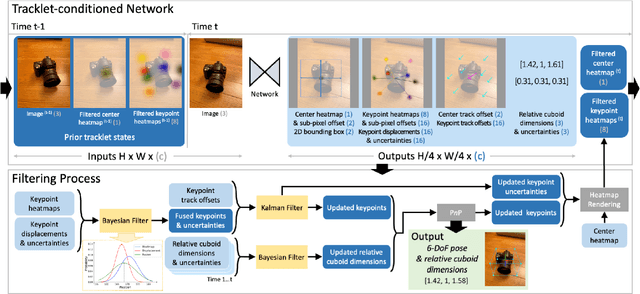
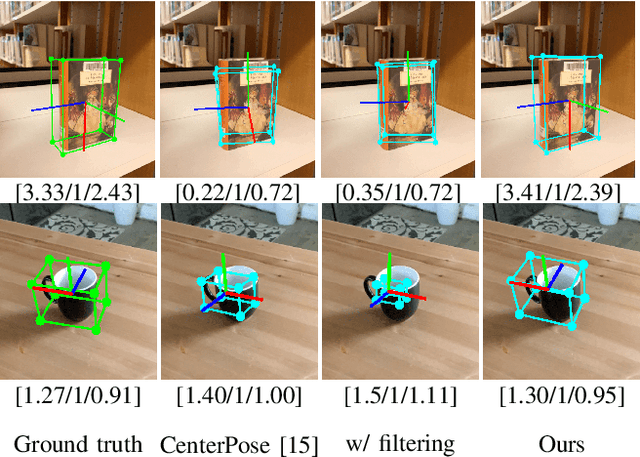
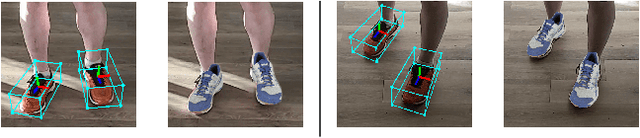
We propose a single-stage, category-level 6-DoF pose estimation algorithm that simultaneously detects and tracks instances of objects within a known category. Our method takes as input the previous and current frame from a monocular RGB video, as well as predictions from the previous frame, to predict the bounding cuboid and 6-DoF pose (up to scale). Internally, a deep network predicts distributions over object keypoints (vertices of the bounding cuboid) in image coordinates, after which a novel probabilistic filtering process integrates across estimates before computing the final pose using PnP. Our framework allows the system to take previous uncertainties into consideration when predicting the current frame, resulting in predictions that are more accurate and stable than single frame methods. Extensive experiments show that our method outperforms existing approaches on the challenging Objectron benchmark of annotated object videos. We also demonstrate the usability of our work in an augmented reality setting.
SGL: Symbolic Goal Learning in a Hybrid, Modular Framework for Human Instruction Following
Feb 25, 2022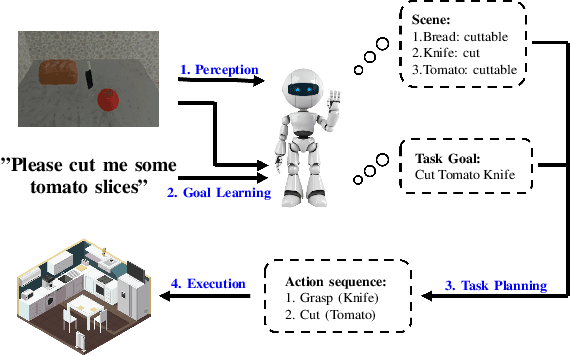
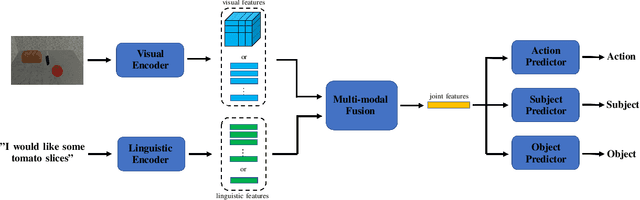
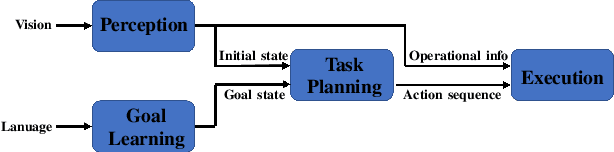
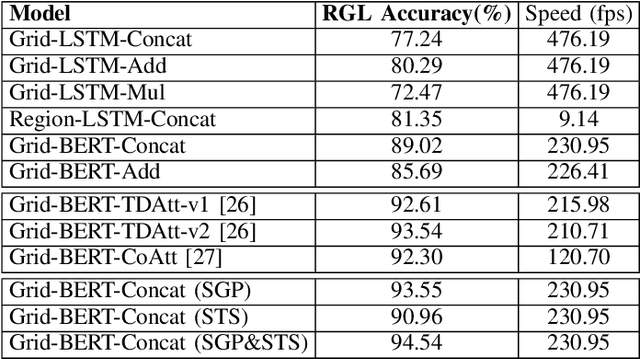
This paper investigates robot manipulation based on human instruction with ambiguous requests. The intent is to compensate for imperfect natural language via visual observations. Early symbolic methods, based on manually defined symbols, built modular framework consist of semantic parsing and task planning for producing sequences of actions from natural language requests. Modern connectionist methods employ deep neural networks to automatically learn visual and linguistic features and map to a sequence of low-level actions, in an endto-end fashion. These two approaches are blended to create a hybrid, modular framework: it formulates instruction following as symbolic goal learning via deep neural networks followed by task planning via symbolic planners. Connectionist and symbolic modules are bridged with Planning Domain Definition Language. The vision-and-language learning network predicts its goal representation, which is sent to a planner for producing a task-completing action sequence. For improving the flexibility of natural language, we further incorporate implicit human intents with explicit human instructions. To learn generic features for vision and language, we propose to separately pretrain vision and language encoders on scene graph parsing and semantic textual similarity tasks. Benchmarking evaluates the impacts of different components of, or options for, the vision-and-language learning model and shows the effectiveness of pretraining strategies. Manipulation experiments conducted in the simulator AI2THOR show the robustness of the framework to novel scenarios.
Primitive Shape Recognition for Object Grasping
Jan 04, 2022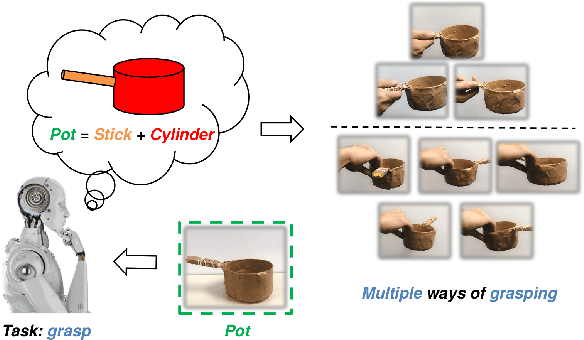

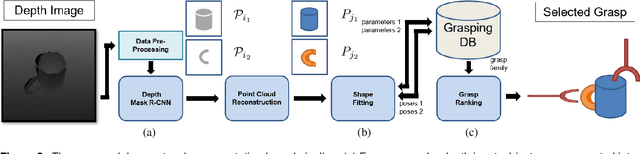

Shape informs how an object should be grasped, both in terms of where and how. As such, this paper describes a segmentation-based architecture for decomposing objects sensed with a depth camera into multiple primitive shapes, along with a post-processing pipeline for robotic grasping. Segmentation employs a deep network, called PS-CNN, trained on synthetic data with 6 classes of primitive shapes and generated using a simulation engine. Each primitive shape is designed with parametrized grasp families, permitting the pipeline to identify multiple grasp candidates per shape region. The grasps are rank ordered, with the first feasible one chosen for execution. For task-free grasping of individual objects, the method achieves a 94.2% success rate placing it amongst the top performing grasp methods when compared to top-down and SE(3)-based approaches. Additional tests involving variable viewpoints and clutter demonstrate robustness to setup. For task-oriented grasping, PS-CNN achieves a 93.0% success rate. Overall, the outcomes support the hypothesis that explicitly encoding shape primitives within a grasping pipeline should boost grasping performance, including task-free and task-relevant grasp prediction.
Single-stage Keypoint-based Category-level Object Pose Estimation from an RGB Image
Sep 13, 2021
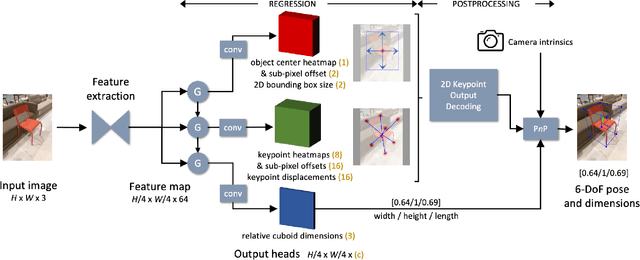

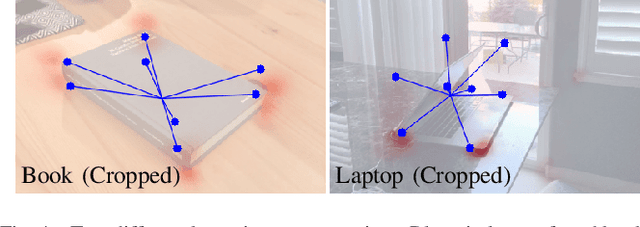
Prior work on 6-DoF object pose estimation has largely focused on instance-level processing, in which a textured CAD model is available for each object being detected. Category-level 6-DoF pose estimation represents an important step toward developing robotic vision systems that operate in unstructured, real-world scenarios. In this work, we propose a single-stage, keypoint-based approach for category-level object pose estimation that operates on unknown object instances within a known category using a single RGB image as input. The proposed network performs 2D object detection, detects 2D keypoints, estimates 6-DoF pose, and regresses relative bounding cuboid dimensions. These quantities are estimated in a sequential fashion, leveraging the recent idea of convGRU for propagating information from easier tasks to those that are more difficult. We favor simplicity in our design choices: generic cuboid vertex coordinates, single-stage network, and monocular RGB input. We conduct extensive experiments on the challenging Objectron benchmark, outperforming state-of-the-art methods on the 3D IoU metric (27.6% higher than the MobilePose single-stage approach and 7.1% higher than the related two-stage approach).
NViSII: A Scriptable Tool for Photorealistic Image Generation
May 28, 2021



We present a Python-based renderer built on NVIDIA's OptiX ray tracing engine and the OptiX AI denoiser, designed to generate high-quality synthetic images for research in computer vision and deep learning. Our tool enables the description and manipulation of complex dynamic 3D scenes containing object meshes, materials, textures, lighting, volumetric data (e.g., smoke), and backgrounds. Metadata, such as 2D/3D bounding boxes, segmentation masks, depth maps, normal maps, material properties, and optical flow vectors, can also be generated. In this work, we discuss design goals, architecture, and performance. We demonstrate the use of data generated by path tracing for training an object detector and pose estimator, showing improved performance in sim-to-real transfer in situations that are difficult for traditional raster-based renderers. We offer this tool as an easy-to-use, performant, high-quality renderer for advancing research in synthetic data generation and deep learning.