 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisual Foresight for Robotic Stow: A Diffusion-Based World Model from Sparse Snapshots
Feb 12, 2026Automated warehouses execute millions of stow operations, where robots place objects into storage bins. For these systems it is valuable to anticipate how a bin will look from the current observations and the planned stow behavior before real execution. We propose FOREST, a stow-intent-conditioned world model that represents bin states as item-aligned instance masks and uses a latent diffusion transformer to predict the post-stow configuration from the observed context. Our evaluation shows that FOREST substantially improves the geometric agreement between predicted and true post-stow layouts compared with heuristic baselines. We further evaluate the predicted post-stow layouts in two downstream tasks, in which replacing the real post-stow masks with FOREST predictions causes only modest performance loss in load-quality assessment and multi-stow reasoning, indicating that our model can provide useful foresight signals for warehouse planning.
Stow: Robotic Packing of Items into Fabric Pods
May 07, 2025



This paper presents a compliant manipulation system capable of placing items onto densely packed shelves. The wide diversity of items and strict business requirements for high producing rates and low defect generation have prohibited warehouse robotics from performing this task. Our innovations in hardware, perception, decision-making, motion planning, and control have enabled this system to perform over 500,000 stows in a large e-commerce fulfillment center. The system achieves human levels of packing density and speed while prioritizing work on overhead shelves to enhance the safety of humans working alongside the robots.
FoundationGrasp: Generalizable Task-Oriented Grasping with Foundation Models
Apr 16, 2024
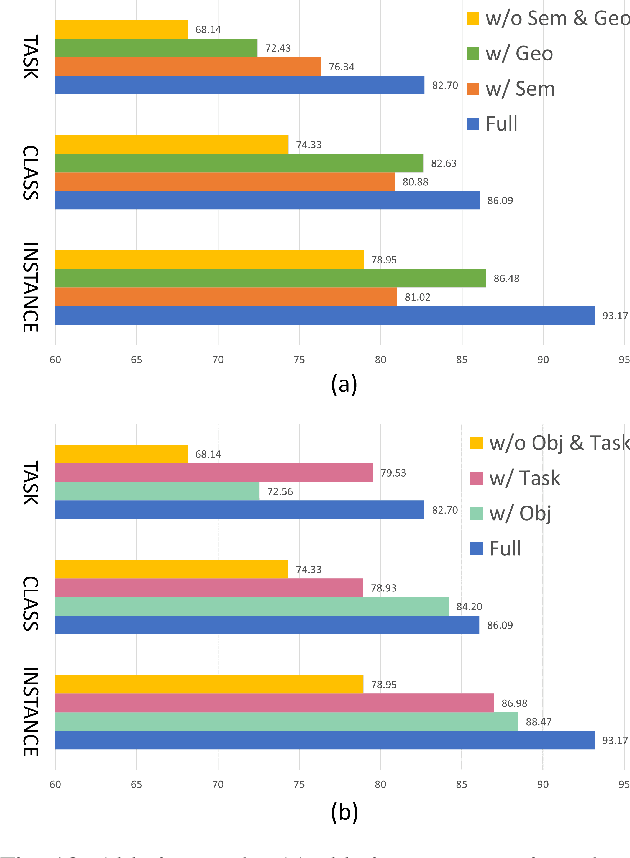


Task-oriented grasping (TOG), which refers to the problem of synthesizing grasps on an object that are configurationally compatible with the downstream manipulation task, is the first milestone towards tool manipulation. Analogous to the activation of two brain regions responsible for semantic and geometric reasoning during cognitive processes, modeling the complex relationship between objects, tasks, and grasps requires rich prior knowledge about objects and tasks. Existing methods typically limit the prior knowledge to a closed-set scope and cannot support the generalization to novel objects and tasks out of the training set. To address such a limitation, we propose FoundationGrasp, a foundation model-based TOG framework that leverages the open-ended knowledge from foundation models to learn generalizable TOG skills. Comprehensive experiments are conducted on the contributed Language and Vision Augmented TaskGrasp (LaViA-TaskGrasp) dataset, demonstrating the superiority of FoudationGrasp over existing methods when generalizing to novel object instances, object classes, and tasks out of the training set. Furthermore, the effectiveness of FoudationGrasp is validated in real-robot grasping and manipulation experiments on a 7 DoF robotic arm. Our code, data, appendix, and video are publicly available at https://sites.google.com/view/foundationgrasp.
WDiscOOD: Out-of-Distribution Detection via Whitened Linear Discriminant Analysis
Mar 22, 2023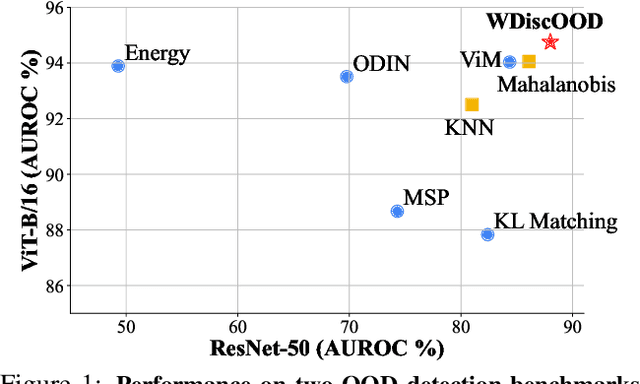
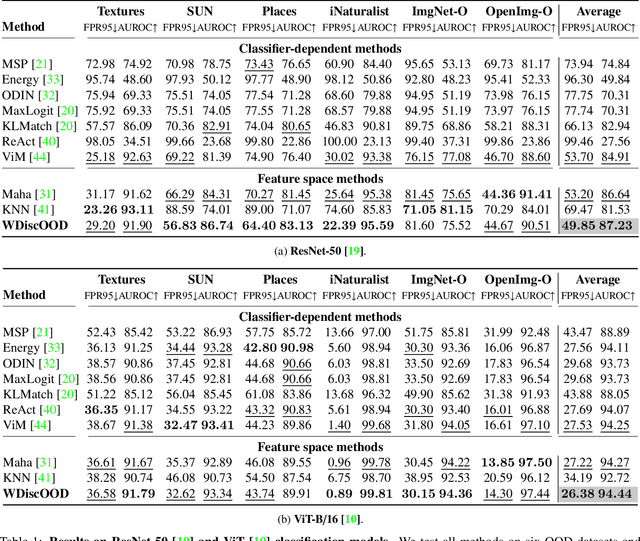
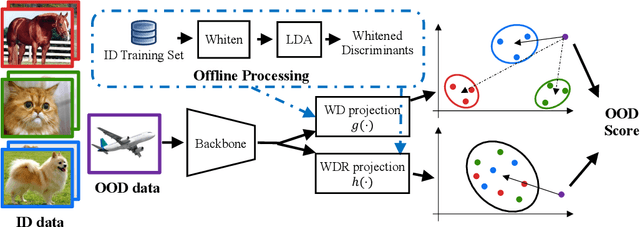

Deep neural networks are susceptible to generating overconfident yet erroneous predictions when presented with data beyond known concepts. This challenge underscores the importance of detecting out-of-distribution (OOD) samples in the open world. In this work, we propose a novel feature-space OOD detection score that jointly reasons with both class-specific and class-agnostic information. Specifically, our approach utilizes Whitened Linear Discriminant Analysis to project features into two subspaces - the discriminative and residual subspaces - in which the ID classes are maximally separated and closely clustered, respectively. The OOD score is then determined by combining the deviation from the input data to the ID distribution in both subspaces. The efficacy of our method, named WDiscOOD, is verified on the large-scale ImageNet-1k benchmark, with six OOD datasets that covers a variety of distribution shifts. WDiscOOD demonstrates superior performance on deep classifiers with diverse backbone architectures, including CNN and vision transformer. Furthermore, we also show that our method can more effectively detect novel concepts in representation space trained with contrastive objectives, including supervised contrastive loss and multi-modality contrastive loss.
KGNv2: Separating Scale and Pose Prediction for Keypoint-based 6-DoF Grasp Synthesis on RGB-D input
Mar 16, 2023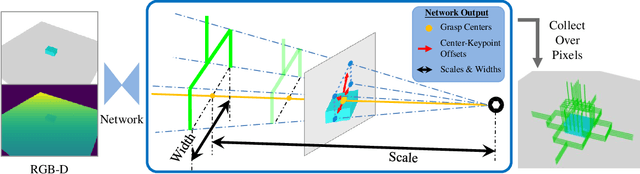
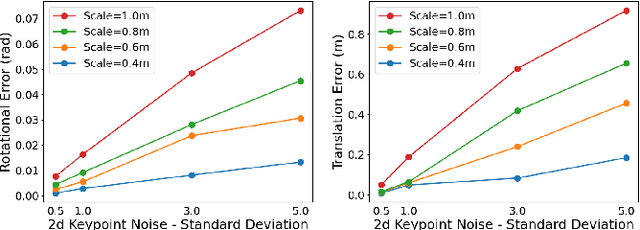
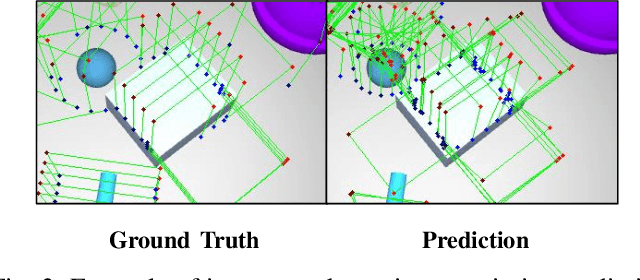

We propose a new 6-DoF grasp pose synthesis approach from 2D/2.5D input based on keypoints. Keypoint-based grasp detector from image input has demonstrated promising results in the previous study, where the additional visual information provided by color images compensates for the noisy depth perception. However, it relies heavily on accurately predicting the location of keypoints in the image space. In this paper, we devise a new grasp generation network that reduces the dependency on precise keypoint estimation. Given an RGB-D input, our network estimates both the grasp pose from keypoint detection as well as scale towards the camera. We further re-design the keypoint output space in order to mitigate the negative impact of keypoint prediction noise to Perspective-n-Point (PnP) algorithm. Experiments show that the proposed method outperforms the baseline by a large margin, validating the efficacy of our approach. Finally, despite trained on simple synthetic objects, our method demonstrate sim-to-real capacity by showing competitive results in real-world robot experiments.
Zero-Shot Object Searching Using Large-scale Object Relationship Prior
Mar 10, 2023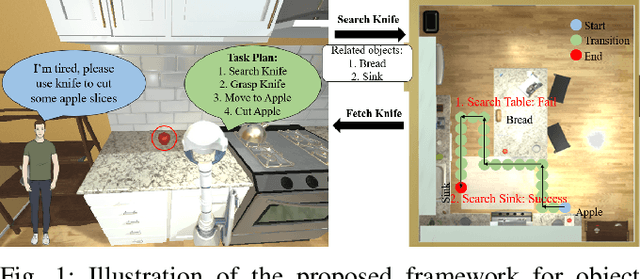
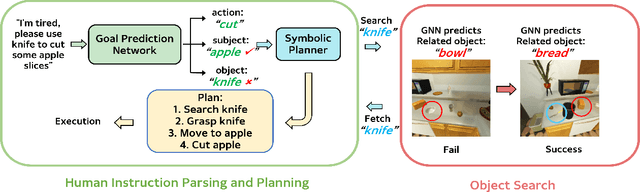
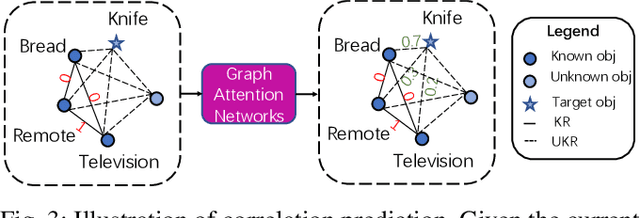

Home-assistant robots have been a long-standing research topic, and one of the biggest challenges is searching for required objects in housing environments. Previous object-goal navigation requires the robot to search for a target object category in an unexplored environment, which may not be suitable for home-assistant robots that typically have some level of semantic knowledge of the environment, such as the location of static furniture. In our approach, we leverage this knowledge and the fact that a target object may be located close to its related objects for efficient navigation. To achieve this, we train a graph neural network using the Visual Genome dataset to learn the object co-occurrence relationships and formulate the searching process as iteratively predicting the possible areas where the target object may be located. This approach is entirely zero-shot, meaning it doesn't require new accurate object correlation in the test environment. We empirically show that our method outperforms prior correlational object search algorithms. As our ultimate goal is to build fully autonomous assistant robots for everyday use, we further integrate the task planner for parsing natural language and generating task-completing plans with object navigation to execute human instructions. We demonstrate the effectiveness of our proposed pipeline in both the AI2-THOR simulator and a Stretch robot in a real-world environment.
SGL: Symbolic Goal Learning in a Hybrid, Modular Framework for Human Instruction Following
Feb 25, 2022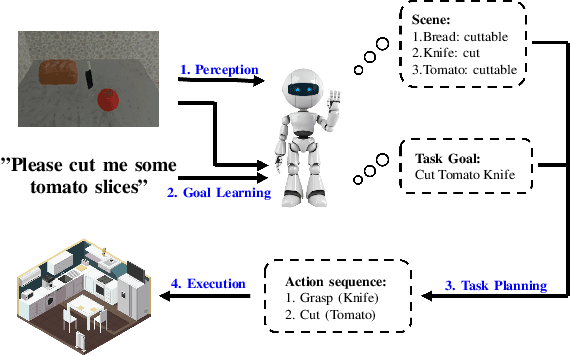
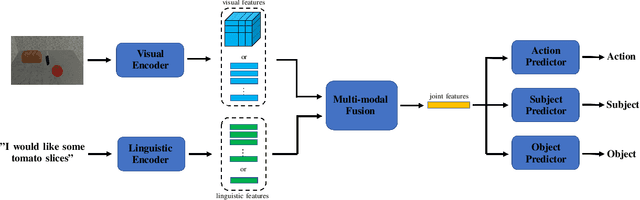
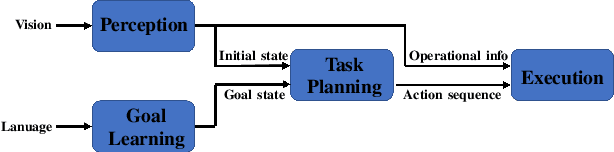
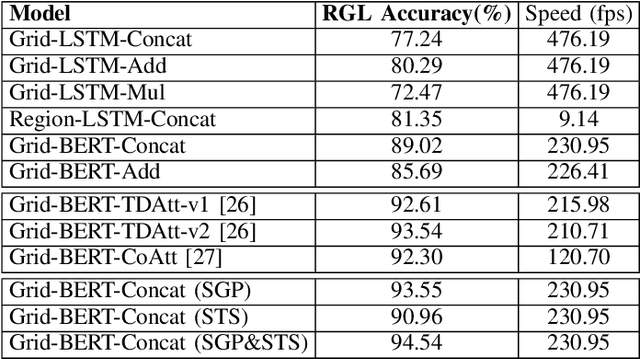
This paper investigates robot manipulation based on human instruction with ambiguous requests. The intent is to compensate for imperfect natural language via visual observations. Early symbolic methods, based on manually defined symbols, built modular framework consist of semantic parsing and task planning for producing sequences of actions from natural language requests. Modern connectionist methods employ deep neural networks to automatically learn visual and linguistic features and map to a sequence of low-level actions, in an endto-end fashion. These two approaches are blended to create a hybrid, modular framework: it formulates instruction following as symbolic goal learning via deep neural networks followed by task planning via symbolic planners. Connectionist and symbolic modules are bridged with Planning Domain Definition Language. The vision-and-language learning network predicts its goal representation, which is sent to a planner for producing a task-completing action sequence. For improving the flexibility of natural language, we further incorporate implicit human intents with explicit human instructions. To learn generic features for vision and language, we propose to separately pretrain vision and language encoders on scene graph parsing and semantic textual similarity tasks. Benchmarking evaluates the impacts of different components of, or options for, the vision-and-language learning model and shows the effectiveness of pretraining strategies. Manipulation experiments conducted in the simulator AI2THOR show the robustness of the framework to novel scenarios.
Primitive Shape Recognition for Object Grasping
Jan 04, 2022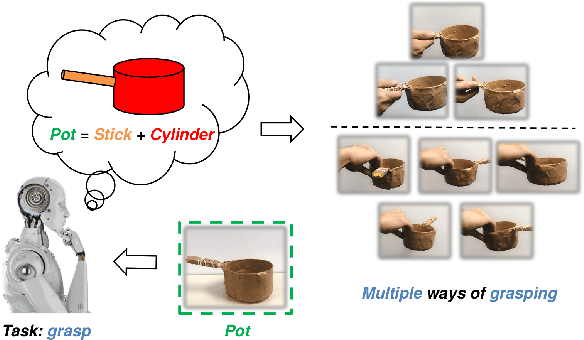

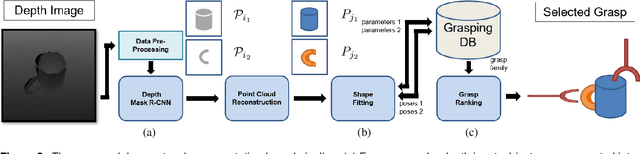

Shape informs how an object should be grasped, both in terms of where and how. As such, this paper describes a segmentation-based architecture for decomposing objects sensed with a depth camera into multiple primitive shapes, along with a post-processing pipeline for robotic grasping. Segmentation employs a deep network, called PS-CNN, trained on synthetic data with 6 classes of primitive shapes and generated using a simulation engine. Each primitive shape is designed with parametrized grasp families, permitting the pipeline to identify multiple grasp candidates per shape region. The grasps are rank ordered, with the first feasible one chosen for execution. For task-free grasping of individual objects, the method achieves a 94.2% success rate placing it amongst the top performing grasp methods when compared to top-down and SE(3)-based approaches. Additional tests involving variable viewpoints and clutter demonstrate robustness to setup. For task-oriented grasping, PS-CNN achieves a 93.0% success rate. Overall, the outcomes support the hypothesis that explicitly encoding shape primitives within a grasping pipeline should boost grasping performance, including task-free and task-relevant grasp prediction.
GKNet: grasp keypoint network for grasp candidates detection
Jun 16, 2021
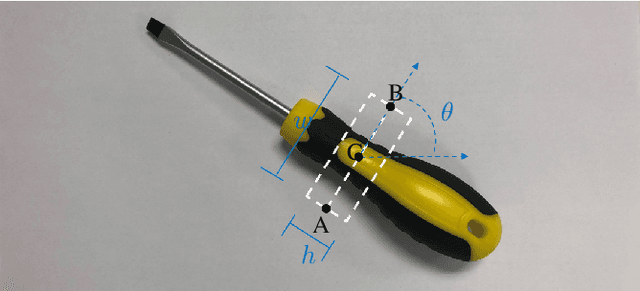
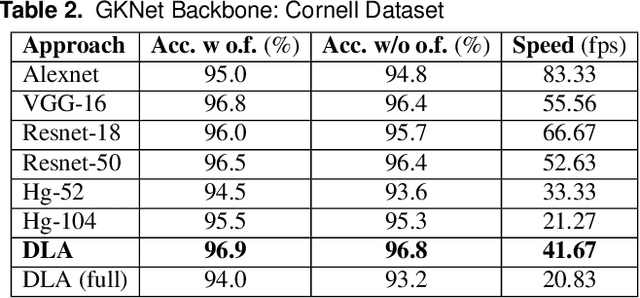
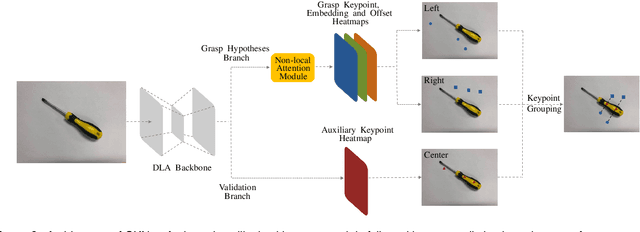
Contemporary grasp detection approaches employ deep learning to achieve robustness to sensor and object model uncertainty. The two dominant approaches design either grasp-quality scoring or anchor-based grasp recognition networks. This paper presents a different approach to grasp detection by treating it as keypoint detection. The deep network detects each grasp candidate as a pair of keypoints, convertible to the grasp representation g = {x, y, w, {\theta}}^T, rather than a triplet or quartet of corner points. Decreasing the detection difficulty by grouping keypoints into pairs boosts performance. To further promote dependencies between keypoints, the general non-local module is incorporated into the proposed learning framework. A final filtering strategy based on discrete and continuous orientation prediction removes false correspondences and further improves grasp detection performance. GKNet, the approach presented here, achieves the best balance of accuracy and speed on the Cornell and the abridged Jacquard dataset (96.9% and 98.39% at 41.67 and 23.26 fps). Follow-up experiments on a manipulator evaluate GKNet using 4 types of grasping experiments reflecting different nuisance sources: static grasping, dynamic grasping, grasping at varied camera angles, and bin picking. GKNet outperforms reference baselines in static and dynamic grasping experiments while showing robustness to varied camera viewpoints and bin picking experiments. The results confirm the hypothesis that grasp keypoints are an effective output representation for deep grasp networks that provide robustness to expected nuisance factors.
A Joint Network for Grasp Detection Conditioned on Natural Language Commands
Apr 01, 2021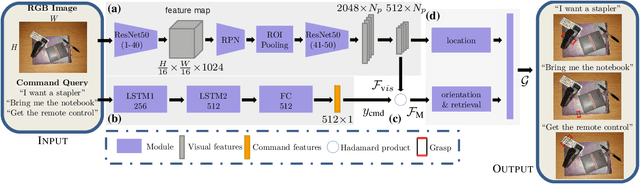

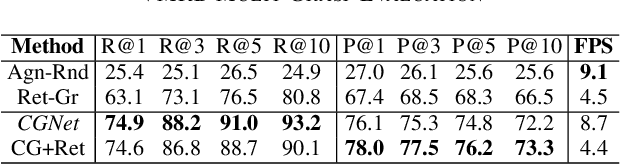
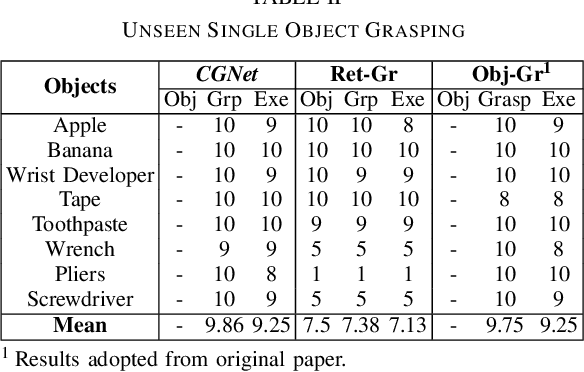
We consider the task of grasping a target object based on a natural language command query. Previous work primarily focused on localizing the object given the query, which requires a separate grasp detection module to grasp it. The cascaded application of two pipelines incurs errors in overlapping multi-object cases due to ambiguity in the individual outputs. This work proposes a model named Command Grasping Network(CGNet) to directly output command satisficing grasps from RGB image and textual command inputs. A dataset with ground truth (image, command, grasps) tuple is generated based on the VMRD dataset to train the proposed network. Experimental results on the generated test set show that CGNet outperforms a cascaded object-retrieval and grasp detection baseline by a large margin. Three physical experiments demonstrate the functionality and performance of CGNet.