 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGKNet: grasp keypoint network for grasp candidates detection
Paper and Code
Jun 16, 2021
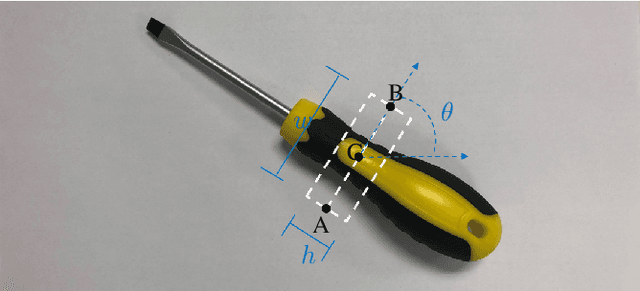
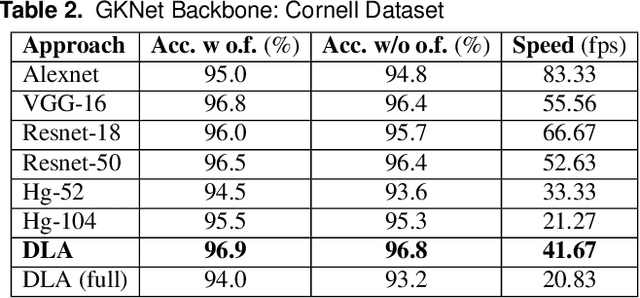
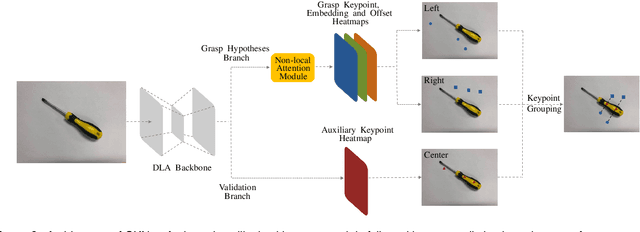
Contemporary grasp detection approaches employ deep learning to achieve robustness to sensor and object model uncertainty. The two dominant approaches design either grasp-quality scoring or anchor-based grasp recognition networks. This paper presents a different approach to grasp detection by treating it as keypoint detection. The deep network detects each grasp candidate as a pair of keypoints, convertible to the grasp representation g = {x, y, w, {\theta}}^T, rather than a triplet or quartet of corner points. Decreasing the detection difficulty by grouping keypoints into pairs boosts performance. To further promote dependencies between keypoints, the general non-local module is incorporated into the proposed learning framework. A final filtering strategy based on discrete and continuous orientation prediction removes false correspondences and further improves grasp detection performance. GKNet, the approach presented here, achieves the best balance of accuracy and speed on the Cornell and the abridged Jacquard dataset (96.9% and 98.39% at 41.67 and 23.26 fps). Follow-up experiments on a manipulator evaluate GKNet using 4 types of grasping experiments reflecting different nuisance sources: static grasping, dynamic grasping, grasping at varied camera angles, and bin picking. GKNet outperforms reference baselines in static and dynamic grasping experiments while showing robustness to varied camera viewpoints and bin picking experiments. The results confirm the hypothesis that grasp keypoints are an effective output representation for deep grasp networks that provide robustness to expected nuisance factors.