 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-SpatialMLLM: Multi-Frame Spatial Understanding with Multi-Modal Large Language Models
May 22, 2025

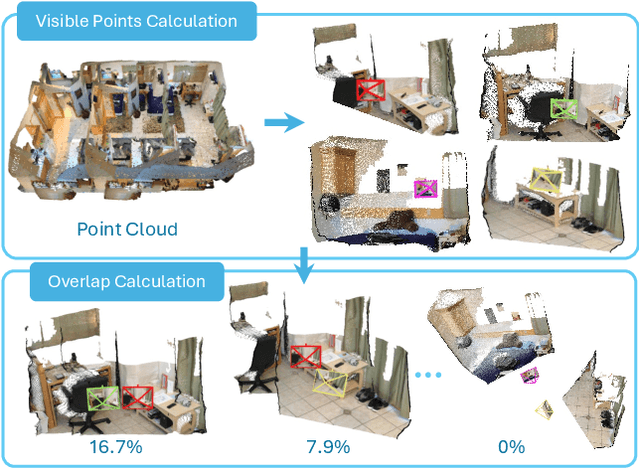

Multi-modal large language models (MLLMs) have rapidly advanced in visual tasks, yet their spatial understanding remains limited to single images, leaving them ill-suited for robotics and other real-world applications that require multi-frame reasoning. In this paper, we propose a framework to equip MLLMs with robust multi-frame spatial understanding by integrating depth perception, visual correspondence, and dynamic perception. Central to our approach is the MultiSPA dataset, a novel, large-scale collection of more than 27 million samples spanning diverse 3D and 4D scenes. Alongside MultiSPA, we introduce a comprehensive benchmark that tests a wide spectrum of spatial tasks under uniform metrics. Our resulting model, Multi-SpatialMLLM, achieves significant gains over baselines and proprietary systems, demonstrating scalable, generalizable multi-frame reasoning. We further observe multi-task benefits and early indications of emergent capabilities in challenging scenarios, and showcase how our model can serve as a multi-frame reward annotator for robotics.
HOIGPT: Learning Long Sequence Hand-Object Interaction with Language Models
Mar 24, 2025



We introduce HOIGPT, a token-based generative method that unifies 3D hand-object interactions (HOI) perception and generation, offering the first comprehensive solution for captioning and generating high-quality 3D HOI sequences from a diverse range of conditional signals (\eg text, objects, partial sequences). At its core, HOIGPT utilizes a large language model to predict the bidrectional transformation between HOI sequences and natural language descriptions. Given text inputs, HOIGPT generates a sequence of hand and object meshes; given (partial) HOI sequences, HOIGPT generates text descriptions and completes the sequences. To facilitate HOI understanding with a large language model, this paper introduces two key innovations: (1) a novel physically grounded HOI tokenizer, the hand-object decomposed VQ-VAE, for discretizing HOI sequences, and (2) a motion-aware language model trained to process and generate both text and HOI tokens. Extensive experiments demonstrate that HOIGPT sets new state-of-the-art performance on both text generation (+2.01% R Precision) and HOI generation (-2.56 FID) across multiple tasks and benchmarks.
OmniPose6D: Towards Short-Term Object Pose Tracking in Dynamic Scenes from Monocular RGB
Oct 09, 2024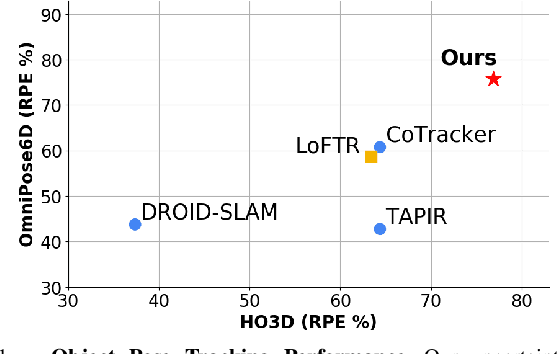

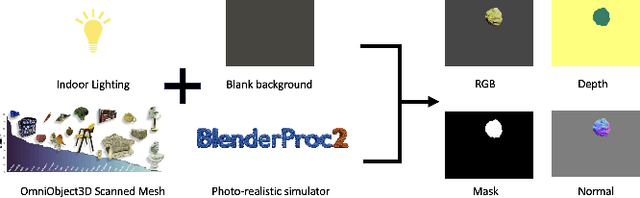
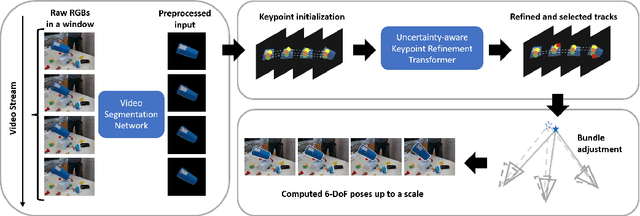
To address the challenge of short-term object pose tracking in dynamic environments with monocular RGB input, we introduce a large-scale synthetic dataset OmniPose6D, crafted to mirror the diversity of real-world conditions. We additionally present a benchmarking framework for a comprehensive comparison of pose tracking algorithms. We propose a pipeline featuring an uncertainty-aware keypoint refinement network, employing probabilistic modeling to refine pose estimation. Comparative evaluations demonstrate that our approach achieves performance superior to existing baselines on real datasets, underscoring the effectiveness of our synthetic dataset and refinement technique in enhancing tracking precision in dynamic contexts. Our contributions set a new precedent for the development and assessment of object pose tracking methodologies in complex scenes.
Propose, Assess, Search: Harnessing LLMs for Goal-Oriented Planning in Instructional Videos
Sep 30, 2024
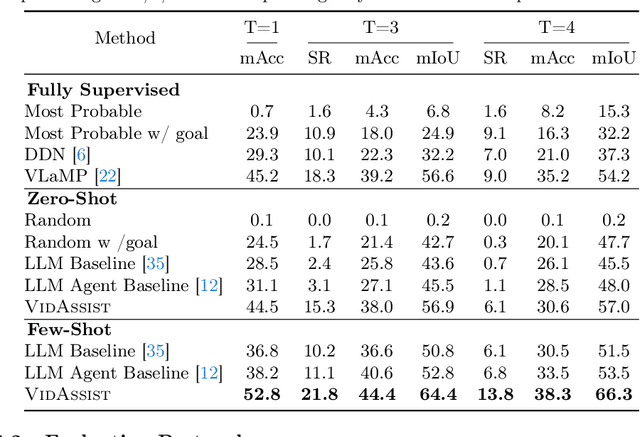
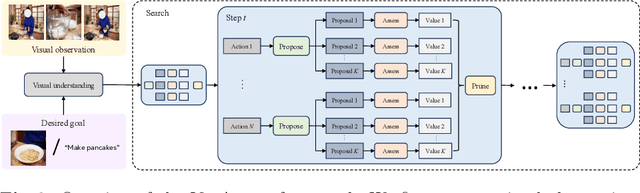
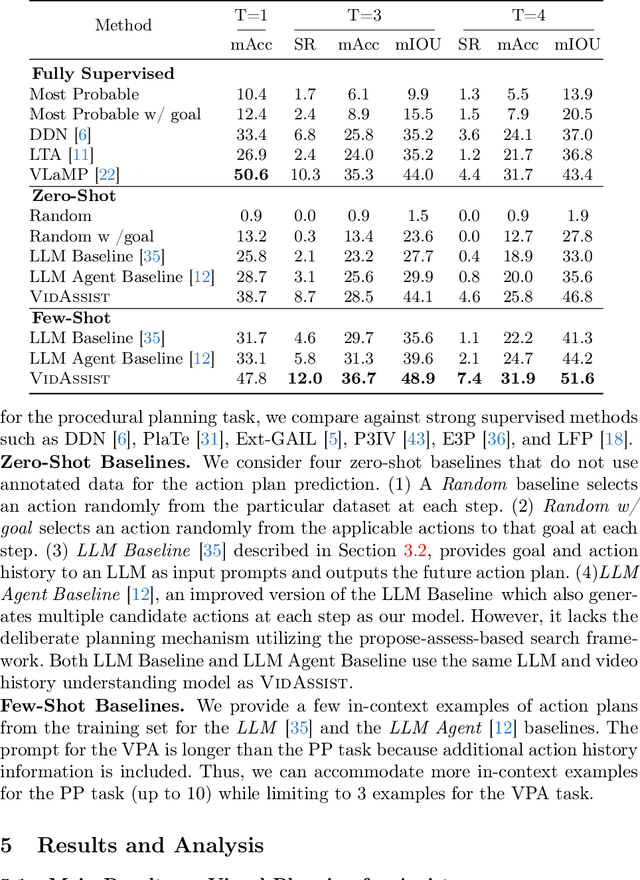
Goal-oriented planning, or anticipating a series of actions that transition an agent from its current state to a predefined objective, is crucial for developing intelligent assistants aiding users in daily procedural tasks. The problem presents significant challenges due to the need for comprehensive knowledge of temporal and hierarchical task structures, as well as strong capabilities in reasoning and planning. To achieve this, prior work typically relies on extensive training on the target dataset, which often results in significant dataset bias and a lack of generalization to unseen tasks. In this work, we introduce VidAssist, an integrated framework designed for zero/few-shot goal-oriented planning in instructional videos. VidAssist leverages large language models (LLMs) as both the knowledge base and the assessment tool for generating and evaluating action plans, thus overcoming the challenges of acquiring procedural knowledge from small-scale, low-diversity datasets. Moreover, VidAssist employs a breadth-first search algorithm for optimal plan generation, in which a composite of value functions designed for goal-oriented planning is utilized to assess the predicted actions at each step. Extensive experiments demonstrate that VidAssist offers a unified framework for different goal-oriented planning setups, e.g., visual planning for assistance (VPA) and procedural planning (PP), and achieves remarkable performance in zero-shot and few-shot setups. Specifically, our few-shot model outperforms the prior fully supervised state-of-the-art method by +7.7% in VPA and +4.81% PP task on the COIN dataset while predicting 4 future actions. Code, and models are publicly available at https://sites.google.com/view/vidassist.
Unlocking Exocentric Video-Language Data for Egocentric Video Representation Learning
Aug 07, 2024We present EMBED (Egocentric Models Built with Exocentric Data), a method designed to transform exocentric video-language data for egocentric video representation learning. Large-scale exocentric data covers diverse activities with significant potential for egocentric learning, but inherent disparities between egocentric and exocentric data pose challenges in utilizing one view for the other seamlessly. Egocentric videos predominantly feature close-up hand-object interactions, whereas exocentric videos offer a broader perspective on human activities. Additionally, narratives in egocentric datasets are typically more action-centric and closely linked with the visual content, in contrast to the narrative styles found in exocentric datasets. To address these challenges, we employ a data transformation framework to adapt exocentric data for egocentric training, focusing on identifying specific video clips that emphasize hand-object interactions and transforming narration styles to align with egocentric perspectives. By applying both vision and language style transfer, our framework creates a new egocentric dataset derived from exocentric video-language data. Through extensive evaluations, we demonstrate the effectiveness of EMBED, achieving state-of-the-art results across various egocentric downstream tasks, including an absolute improvement of 4.7% on the Epic-Kitchens-100 multi-instance retrieval and 6.2% on the EGTEA classification benchmarks in zero-shot settings. Furthermore, EMBED enables egocentric video-language models to perform competitively in exocentric tasks. Finally, we showcase EMBED's application across various exocentric datasets, exhibiting strong generalization capabilities when applied to different exocentric datasets.
HyperMix: Out-of-Distribution Detection and Classification in Few-Shot Settings
Dec 22, 2023
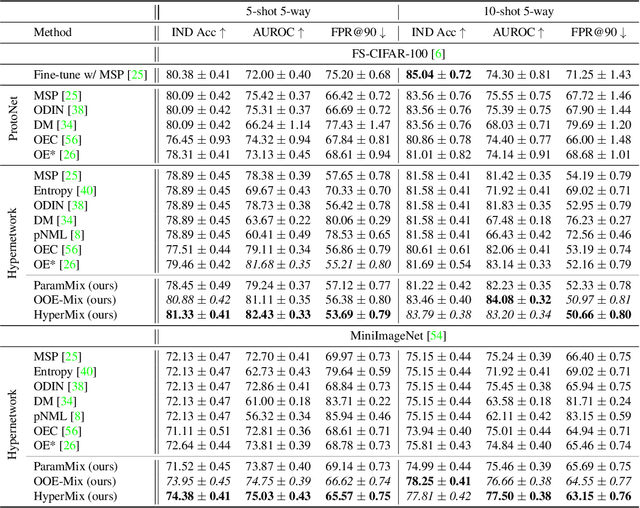
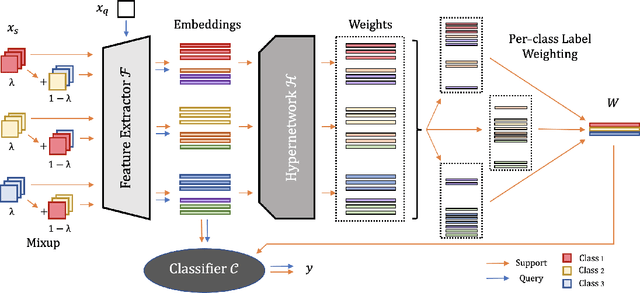
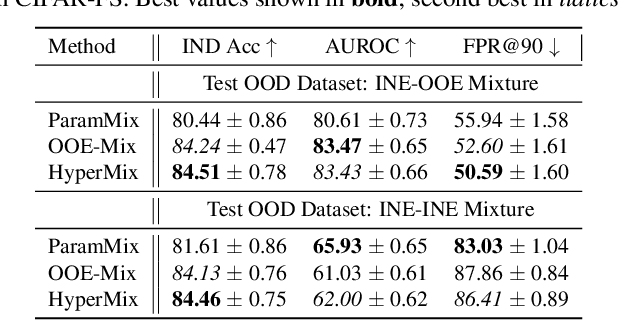
Out-of-distribution (OOD) detection is an important topic for real-world machine learning systems, but settings with limited in-distribution samples have been underexplored. Such few-shot OOD settings are challenging, as models have scarce opportunities to learn the data distribution before being tasked with identifying OOD samples. Indeed, we demonstrate that recent state-of-the-art OOD methods fail to outperform simple baselines in the few-shot setting. We thus propose a hypernetwork framework called HyperMix, using Mixup on the generated classifier parameters, as well as a natural out-of-episode outlier exposure technique that does not require an additional outlier dataset. We conduct experiments on CIFAR-FS and MiniImageNet, significantly outperforming other OOD methods in the few-shot regime.
Ego-Exo4D: Understanding Skilled Human Activity from First- and Third-Person Perspectives
Nov 30, 2023



We present Ego-Exo4D, a diverse, large-scale multimodal multiview video dataset and benchmark challenge. Ego-Exo4D centers around simultaneously-captured egocentric and exocentric video of skilled human activities (e.g., sports, music, dance, bike repair). More than 800 participants from 13 cities worldwide performed these activities in 131 different natural scene contexts, yielding long-form captures from 1 to 42 minutes each and 1,422 hours of video combined. The multimodal nature of the dataset is unprecedented: the video is accompanied by multichannel audio, eye gaze, 3D point clouds, camera poses, IMU, and multiple paired language descriptions -- including a novel "expert commentary" done by coaches and teachers and tailored to the skilled-activity domain. To push the frontier of first-person video understanding of skilled human activity, we also present a suite of benchmark tasks and their annotations, including fine-grained activity understanding, proficiency estimation, cross-view translation, and 3D hand/body pose. All resources will be open sourced to fuel new research in the community.
Primitive Shape Recognition for Object Grasping
Jan 04, 2022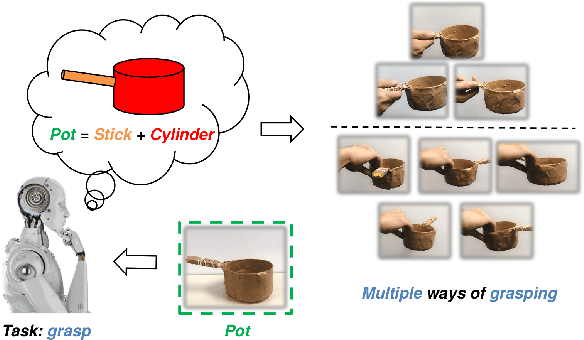

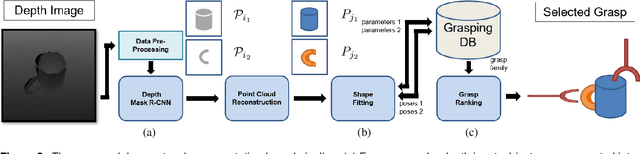

Shape informs how an object should be grasped, both in terms of where and how. As such, this paper describes a segmentation-based architecture for decomposing objects sensed with a depth camera into multiple primitive shapes, along with a post-processing pipeline for robotic grasping. Segmentation employs a deep network, called PS-CNN, trained on synthetic data with 6 classes of primitive shapes and generated using a simulation engine. Each primitive shape is designed with parametrized grasp families, permitting the pipeline to identify multiple grasp candidates per shape region. The grasps are rank ordered, with the first feasible one chosen for execution. For task-free grasping of individual objects, the method achieves a 94.2% success rate placing it amongst the top performing grasp methods when compared to top-down and SE(3)-based approaches. Additional tests involving variable viewpoints and clutter demonstrate robustness to setup. For task-oriented grasping, PS-CNN achieves a 93.0% success rate. Overall, the outcomes support the hypothesis that explicitly encoding shape primitives within a grasping pipeline should boost grasping performance, including task-free and task-relevant grasp prediction.
GKNet: grasp keypoint network for grasp candidates detection
Jun 16, 2021
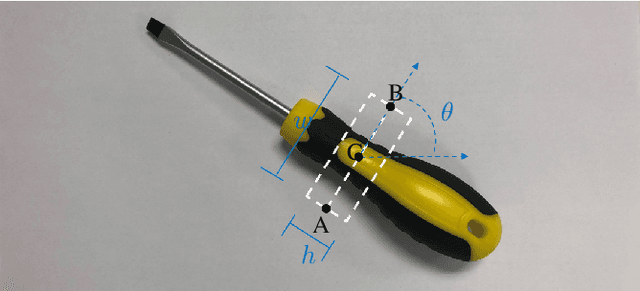
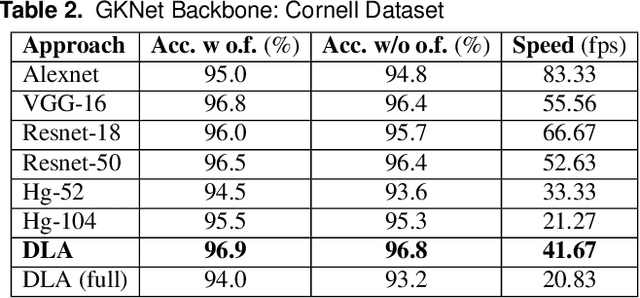
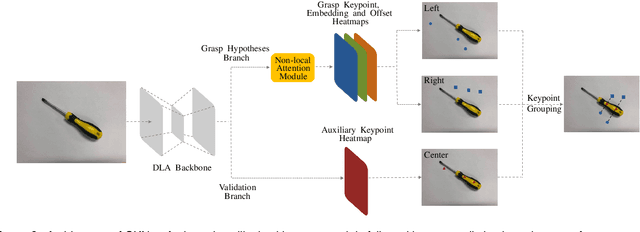
Contemporary grasp detection approaches employ deep learning to achieve robustness to sensor and object model uncertainty. The two dominant approaches design either grasp-quality scoring or anchor-based grasp recognition networks. This paper presents a different approach to grasp detection by treating it as keypoint detection. The deep network detects each grasp candidate as a pair of keypoints, convertible to the grasp representation g = {x, y, w, {\theta}}^T, rather than a triplet or quartet of corner points. Decreasing the detection difficulty by grouping keypoints into pairs boosts performance. To further promote dependencies between keypoints, the general non-local module is incorporated into the proposed learning framework. A final filtering strategy based on discrete and continuous orientation prediction removes false correspondences and further improves grasp detection performance. GKNet, the approach presented here, achieves the best balance of accuracy and speed on the Cornell and the abridged Jacquard dataset (96.9% and 98.39% at 41.67 and 23.26 fps). Follow-up experiments on a manipulator evaluate GKNet using 4 types of grasping experiments reflecting different nuisance sources: static grasping, dynamic grasping, grasping at varied camera angles, and bin picking. GKNet outperforms reference baselines in static and dynamic grasping experiments while showing robustness to varied camera viewpoints and bin picking experiments. The results confirm the hypothesis that grasp keypoints are an effective output representation for deep grasp networks that provide robustness to expected nuisance factors.
Using Synthetic Data and Deep Networks to Recognize Primitive Shapes for Object Grasping
Sep 12, 2019



A segmentation-based architecture is proposed to decompose objects into multiple primitive shapes from monocular depth input for robotic manipulation. The backbone deep network is trained on synthetic data with 6 classes of primitive shapes generated by a simulation engine. Each primitive shape is designed with parametrized grasp families, permitting the pipeline to identify multiple grasp candidates per shape primitive region. The grasps are priority ordered via proposed ranking algorithm, with the first feasible one chosen for execution. On task-free grasping of individual objects, the method achieves a 94% success rate. On task-oriented grasping, it achieves a 76% success rate. Overall, the method supports the hypothesis that shape primitives can support task-free and task-relevant grasp prediction.