 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePropose, Assess, Search: Harnessing LLMs for Goal-Oriented Planning in Instructional Videos
Paper and Code
Sep 30, 2024
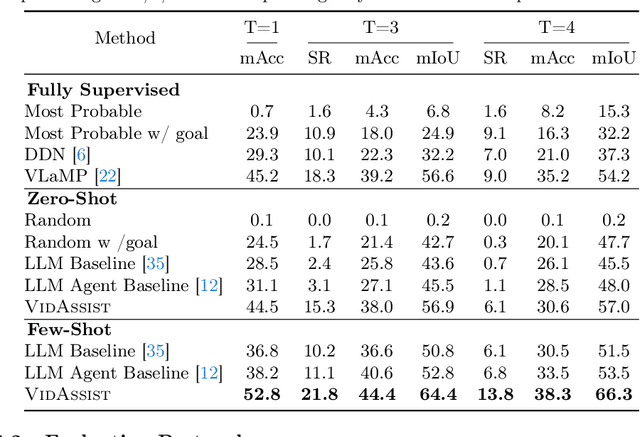
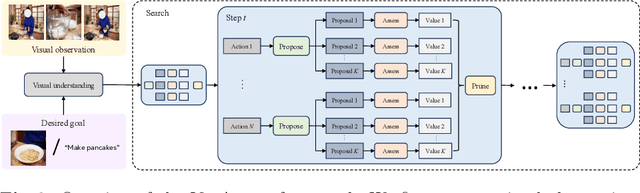
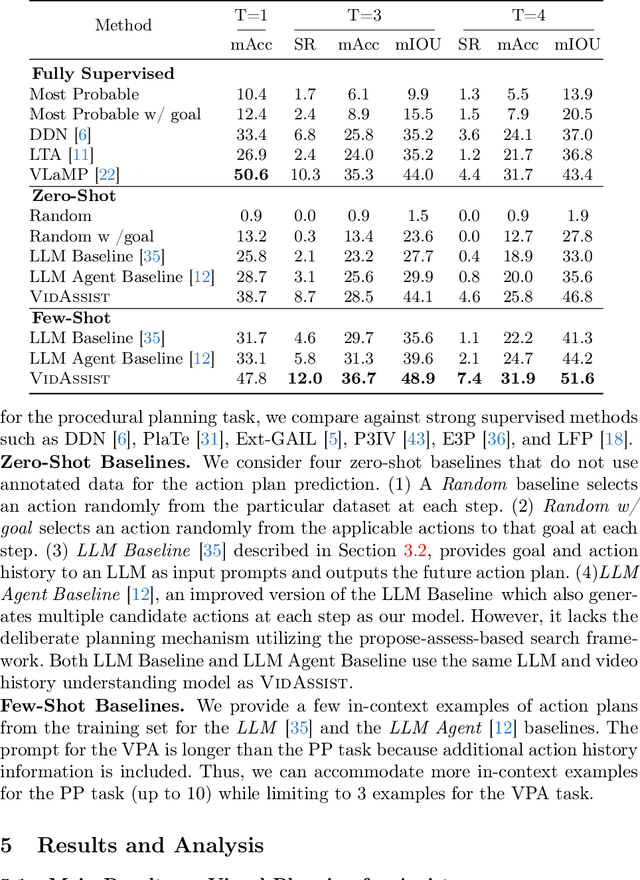
Goal-oriented planning, or anticipating a series of actions that transition an agent from its current state to a predefined objective, is crucial for developing intelligent assistants aiding users in daily procedural tasks. The problem presents significant challenges due to the need for comprehensive knowledge of temporal and hierarchical task structures, as well as strong capabilities in reasoning and planning. To achieve this, prior work typically relies on extensive training on the target dataset, which often results in significant dataset bias and a lack of generalization to unseen tasks. In this work, we introduce VidAssist, an integrated framework designed for zero/few-shot goal-oriented planning in instructional videos. VidAssist leverages large language models (LLMs) as both the knowledge base and the assessment tool for generating and evaluating action plans, thus overcoming the challenges of acquiring procedural knowledge from small-scale, low-diversity datasets. Moreover, VidAssist employs a breadth-first search algorithm for optimal plan generation, in which a composite of value functions designed for goal-oriented planning is utilized to assess the predicted actions at each step. Extensive experiments demonstrate that VidAssist offers a unified framework for different goal-oriented planning setups, e.g., visual planning for assistance (VPA) and procedural planning (PP), and achieves remarkable performance in zero-shot and few-shot setups. Specifically, our few-shot model outperforms the prior fully supervised state-of-the-art method by +7.7% in VPA and +4.81% PP task on the COIN dataset while predicting 4 future actions. Code, and models are publicly available at https://sites.google.com/view/vidassist.