 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSVI-Bench: A Dynamic Microworld for Strategic Video Intelligence
May 29, 2026True video intelligence demands more than recognizing what is visible: it requires reasoning about why events unfold, predicting what would change under different conditions, and deciding what to do next. We refer to this progression, from perception through causal reasoning and simulation to strategic planning, as Strategic Video Intelligence (SVI). No existing benchmark evaluates this capability stack: in-the-wild videos lack verifiable ground truth for causal and strategic questions, while synthetic environments sacrifice the complexity of real multi-agent systems. To bridge this gap, we introduce SVI-Bench, a large-scale benchmark that leverages team sports as a dynamic microworld, combining the complexity of real-world multi-agent interaction (10-22 agents making coordinated decisions under adversarial pressure) with the verifiability of explicit rules and definitive outcomes. SVI-Bench comprises approximately 35K hours of broadcast video, 15M annotated actions, 15K hours of expert commentary, 23K game reports, and 103K structured statistical records across basketball, soccer, and hockey, all constructed via a data engine that transforms raw game data into a dense, cross-referenced corpus. We organize evaluation into 9 tasks spanning a progressive four-pillar hierarchy: Dynamic Scene Understanding, Causal Reasoning, Strategic Simulation, and Agentic Synthesis. Evaluating strong multimodal and agentic baselines, we find a capability cliff: models perform competently on perceptual tasks, achieving approximately 73% on fine-grained action QA, but degrade sharply at each successive cognitive level. Agentic tasks prove hardest: the strongest model achieves only 5% accuracy when required to autonomously gather and integrate evidence across a corpus of 1.8M clips.
Video-RTS: Rethinking Reinforcement Learning and Test-Time Scaling for Efficient and Enhanced Video Reasoning
Jul 09, 2025Despite advances in reinforcement learning (RL)-based video reasoning with large language models (LLMs), data collection and finetuning remain significant challenges. These methods often rely on large-scale supervised fine-tuning (SFT) with extensive video data and long Chain-of-Thought (CoT) annotations, making them costly and hard to scale. To address this, we present Video-RTS, a new approach to improve video reasoning capability with drastically improved data efficiency by combining data-efficient RL with a video-adaptive test-time scaling (TTS) strategy. Based on observations about the data scaling of RL samples, we skip the resource-intensive SFT step and employ efficient pure-RL training with output-based rewards, requiring no additional annotations or extensive fine-tuning. Furthermore, to utilize computational resources more efficiently, we introduce a sparse-to-dense video TTS strategy that improves inference by iteratively adding frames based on output consistency. We validate our approach on multiple video reasoning benchmarks, showing that Video-RTS surpasses existing video reasoning models by an average of 2.4% in accuracy using only 3.6% training samples. For example, Video-RTS achieves a 4.2% improvement on Video-Holmes, a recent and challenging video reasoning benchmark, and a 2.6% improvement on MMVU. Notably, our pure RL training and adaptive video TTS offer complementary strengths, enabling Video-RTS's strong reasoning performance.
BIMBA: Selective-Scan Compression for Long-Range Video Question Answering
Mar 13, 2025Video Question Answering (VQA) in long videos poses the key challenge of extracting relevant information and modeling long-range dependencies from many redundant frames. The self-attention mechanism provides a general solution for sequence modeling, but it has a prohibitive cost when applied to a massive number of spatiotemporal tokens in long videos. Most prior methods rely on compression strategies to lower the computational cost, such as reducing the input length via sparse frame sampling or compressing the output sequence passed to the large language model (LLM) via space-time pooling. However, these naive approaches over-represent redundant information and often miss salient events or fast-occurring space-time patterns. In this work, we introduce BIMBA, an efficient state-space model to handle long-form videos. Our model leverages the selective scan algorithm to learn to effectively select critical information from high-dimensional video and transform it into a reduced token sequence for efficient LLM processing. Extensive experiments demonstrate that BIMBA achieves state-of-the-art accuracy on multiple long-form VQA benchmarks, including PerceptionTest, NExT-QA, EgoSchema, VNBench, LongVideoBench, and Video-MME. Code, and models are publicly available at https://sites.google.com/view/bimba-mllm.
TimeRefine: Temporal Grounding with Time Refining Video LLM
Dec 12, 2024



Video temporal grounding aims to localize relevant temporal boundaries in a video given a textual prompt. Recent work has focused on enabling Video LLMs to perform video temporal grounding via next-token prediction of temporal timestamps. However, accurately localizing timestamps in videos remains challenging for Video LLMs when relying solely on temporal token prediction. Our proposed TimeRefine addresses this challenge in two ways. First, instead of directly predicting the start and end timestamps, we reformulate the temporal grounding task as a temporal refining task: the model first makes rough predictions and then refines them by predicting offsets to the target segment. This refining process is repeated multiple times, through which the model progressively self-improves its temporal localization accuracy. Second, to enhance the model's temporal perception capabilities, we incorporate an auxiliary prediction head that penalizes the model more if a predicted segment deviates further from the ground truth, thus encouraging the model to make closer and more accurate predictions. Our plug-and-play method can be integrated into most LLM-based temporal grounding approaches. The experimental results demonstrate that TimeRefine achieves 3.6% and 5.0% mIoU improvements on the ActivityNet and Charades-STA datasets, respectively. Code and pretrained models will be released.
An Extensive Study on D2C: Overfitting Remediation in Deep Learning Using a Decentralized Approach
Nov 24, 2024Overfitting remains a significant challenge in deep learning, often arising from data outliers, noise, and limited training data. To address this, we propose Divide2Conquer (D2C), a novel technique to mitigate overfitting. D2C partitions the training data into multiple subsets and trains identical models independently on each subset. To balance model generalization and subset-specific learning, the model parameters are periodically aggregated and averaged during training. This process enables the learning of robust patterns while minimizing the influence of outliers and noise. Empirical evaluations on benchmark datasets across diverse deep-learning tasks demonstrate that D2C significantly enhances generalization performance, particularly with larger datasets. Our analysis includes evaluations of decision boundaries, loss curves, and other performance metrics, highlighting D2C's effectiveness both as a standalone technique and in combination with other overfitting reduction methods. We further provide a rigorous mathematical justification for D2C's underlying principles and examine its applicability across multiple domains. Finally, we explore the trade-offs associated with D2C and propose strategies to address them, offering a holistic view of its strengths and limitations. This study establishes D2C as a versatile and effective approach to combating overfitting in deep learning. Our codes are publicly available at: https://github.com/Saiful185/Divide2Conquer.
ReVisionLLM: Recursive Vision-Language Model for Temporal Grounding in Hour-Long Videos
Nov 22, 2024



Large language models (LLMs) excel at retrieving information from lengthy text, but their vision-language counterparts (VLMs) face difficulties with hour-long videos, especially for temporal grounding. Specifically, these VLMs are constrained by frame limitations, often losing essential temporal details needed for accurate event localization in extended video content. We propose ReVisionLLM, a recursive vision-language model designed to locate events in hour-long videos. Inspired by human search strategies, our model initially targets broad segments of interest, progressively revising its focus to pinpoint exact temporal boundaries. Our model can seamlessly handle videos of vastly different lengths, from minutes to hours. We also introduce a hierarchical training strategy that starts with short clips to capture distinct events and progressively extends to longer videos. To our knowledge, ReVisionLLM is the first VLM capable of temporal grounding in hour-long videos, outperforming previous state-of-the-art methods across multiple datasets by a significant margin (+2.6% R1@0.1 on MAD). The code is available at https://github.com/Tanveer81/ReVisionLLM.
Propose, Assess, Search: Harnessing LLMs for Goal-Oriented Planning in Instructional Videos
Sep 30, 2024
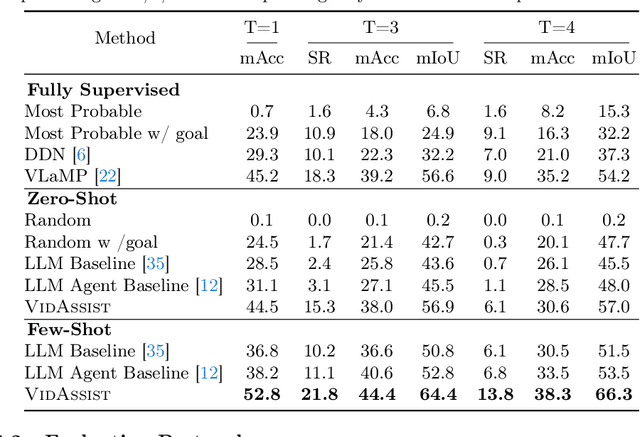
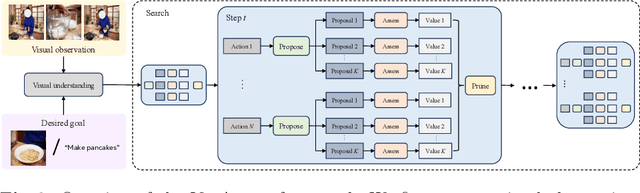
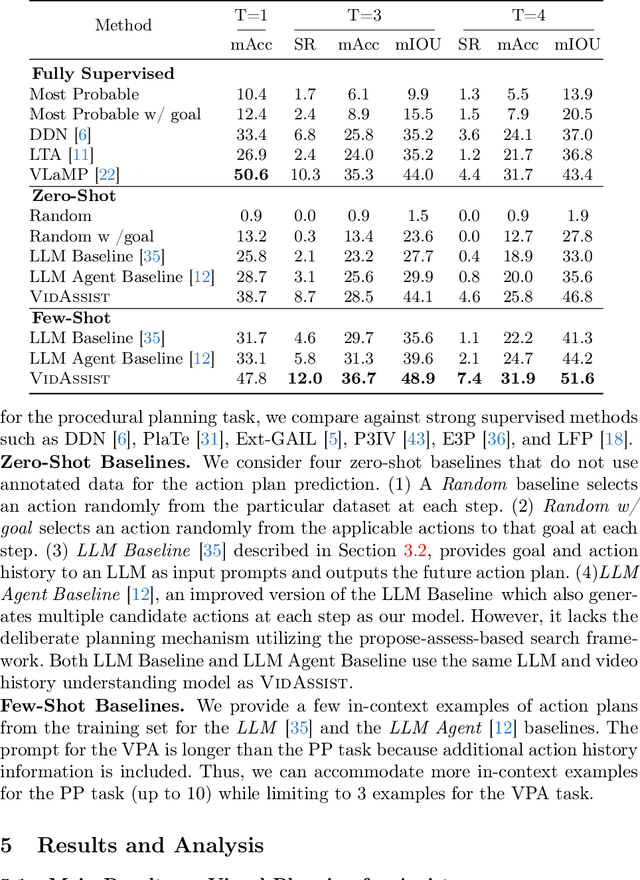
Goal-oriented planning, or anticipating a series of actions that transition an agent from its current state to a predefined objective, is crucial for developing intelligent assistants aiding users in daily procedural tasks. The problem presents significant challenges due to the need for comprehensive knowledge of temporal and hierarchical task structures, as well as strong capabilities in reasoning and planning. To achieve this, prior work typically relies on extensive training on the target dataset, which often results in significant dataset bias and a lack of generalization to unseen tasks. In this work, we introduce VidAssist, an integrated framework designed for zero/few-shot goal-oriented planning in instructional videos. VidAssist leverages large language models (LLMs) as both the knowledge base and the assessment tool for generating and evaluating action plans, thus overcoming the challenges of acquiring procedural knowledge from small-scale, low-diversity datasets. Moreover, VidAssist employs a breadth-first search algorithm for optimal plan generation, in which a composite of value functions designed for goal-oriented planning is utilized to assess the predicted actions at each step. Extensive experiments demonstrate that VidAssist offers a unified framework for different goal-oriented planning setups, e.g., visual planning for assistance (VPA) and procedural planning (PP), and achieves remarkable performance in zero-shot and few-shot setups. Specifically, our few-shot model outperforms the prior fully supervised state-of-the-art method by +7.7% in VPA and +4.81% PP task on the COIN dataset while predicting 4 future actions. Code, and models are publicly available at https://sites.google.com/view/vidassist.
Video ReCap: Recursive Captioning of Hour-Long Videos
Feb 28, 2024



Most video captioning models are designed to process short video clips of few seconds and output text describing low-level visual concepts (e.g., objects, scenes, atomic actions). However, most real-world videos last for minutes or hours and have a complex hierarchical structure spanning different temporal granularities. We propose Video ReCap, a recursive video captioning model that can process video inputs of dramatically different lengths (from 1 second to 2 hours) and output video captions at multiple hierarchy levels. The recursive video-language architecture exploits the synergy between different video hierarchies and can process hour-long videos efficiently. We utilize a curriculum learning training scheme to learn the hierarchical structure of videos, starting from clip-level captions describing atomic actions, then focusing on segment-level descriptions, and concluding with generating summaries for hour-long videos. Furthermore, we introduce Ego4D-HCap dataset by augmenting Ego4D with 8,267 manually collected long-range video summaries. Our recursive model can flexibly generate captions at different hierarchy levels while also being useful for other complex video understanding tasks, such as VideoQA on EgoSchema. Data, code, and models are available at: https://sites.google.com/view/vidrecap
A Simple LLM Framework for Long-Range Video Question-Answering
Dec 28, 2023
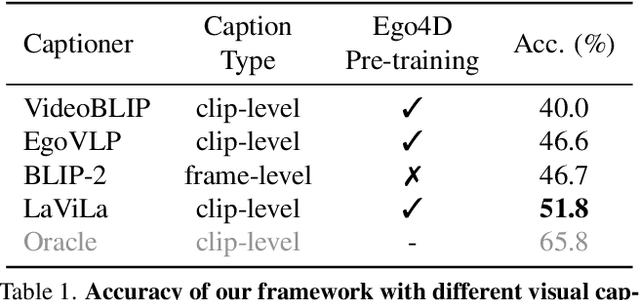
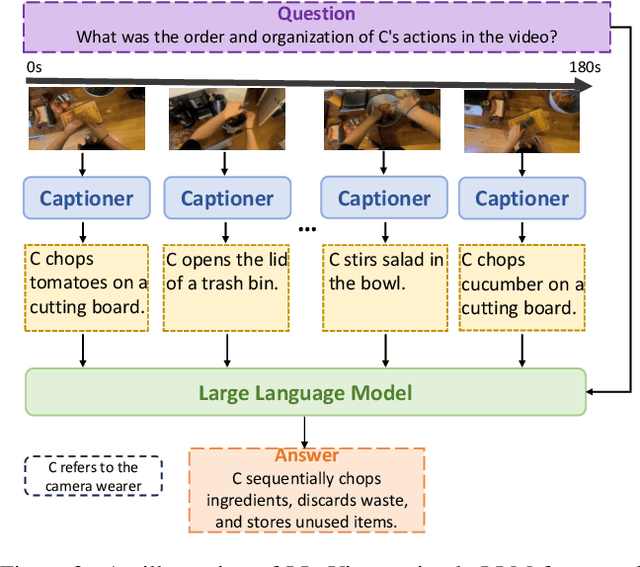

We present LLoVi, a language-based framework for long-range video question-answering (LVQA). Unlike prior long-range video understanding methods, which are often costly and require specialized long-range video modeling design (e.g., memory queues, state-space layers, etc.), our approach uses a frame/clip-level visual captioner (e.g., BLIP2, LaViLa, LLaVA) coupled with a Large Language Model (GPT-3.5, GPT-4) leading to a simple yet surprisingly effective LVQA framework. Specifically, we decompose short and long-range modeling aspects of LVQA into two stages. First, we use a short-term visual captioner to generate textual descriptions of short video clips (0.5-8s in length) densely sampled from a long input video. Afterward, an LLM aggregates the densely extracted short-term captions to perform long-range temporal reasoning needed to understand the whole video and answer a question. To analyze what makes our simple framework so effective, we thoroughly evaluate various components of our system. Our empirical analysis reveals that the choice of the visual captioner and LLM is critical for good LVQA performance. Furthermore, we show that a specialized prompt that asks the LLM first to summarize the noisy short-term visual captions and then answer a given input question leads to a significant LVQA performance boost. On EgoSchema, which is best known as a very long-form video question-answering benchmark, our method achieves 50.3% accuracy, outperforming the previous best-performing approach by 18.1% (absolute gain). In addition, our approach outperforms the previous state-of-the-art by 4.1% and 3.1% on NeXT-QA and IntentQA. We also extend LLoVi to grounded LVQA and show that it outperforms all prior methods on the NeXT-GQA dataset. We will release our code at https://github.com/CeeZh/LLoVi.
RGNet: A Unified Retrieval and Grounding Network for Long Videos
Dec 11, 2023We present a novel end-to-end method for long-form video temporal grounding to locate specific moments described by natural language queries. Prior long-video methods for this task typically contain two stages: proposal selection and grounding regression. However, the proposal selection of these methods is disjoint from the grounding network and is not trained end-to-end, which limits the effectiveness of these methods. Moreover, these methods operate uniformly over the entire temporal window, which is suboptimal given redundant and irrelevant features in long videos. In contrast to these prior approaches, we introduce RGNet, a unified network designed for jointly selecting proposals from hour-long videos and locating moments specified by natural language queries within them. To achieve this, we redefine proposal selection as a video-text retrieval task, i.e., retrieving the correct candidate videos given a text query. The core component of RGNet is a unified cross-modal RG-Encoder that bridges the two stages with shared features and mutual optimization. The encoder strategically focuses on relevant time frames using a sparse sampling technique. RGNet outperforms previous methods, demonstrating state-of-the-art performance on long video temporal grounding datasets MAD and Ego4D. The code is released at https://github.com/Tanveer81/RGNet