 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge$C^3$: Confidence Calibration Model Cascade for Inference-Efficient Cross-Lingual Natural Language Understanding
Feb 25, 2024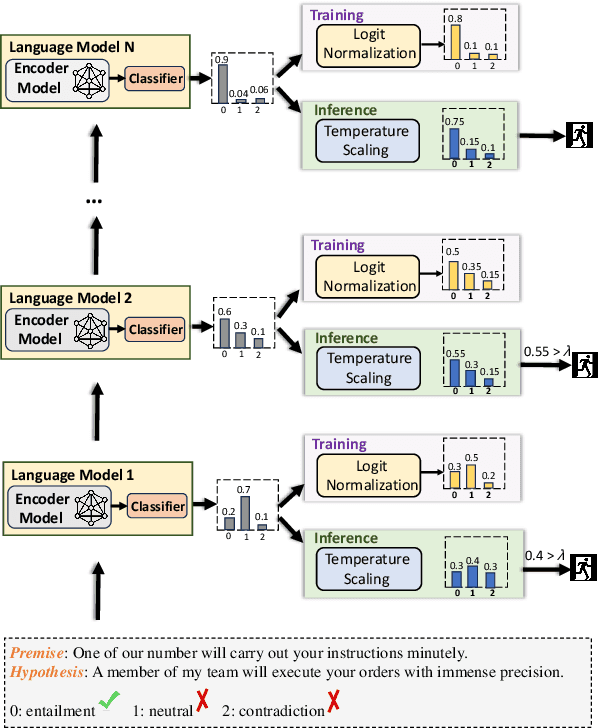
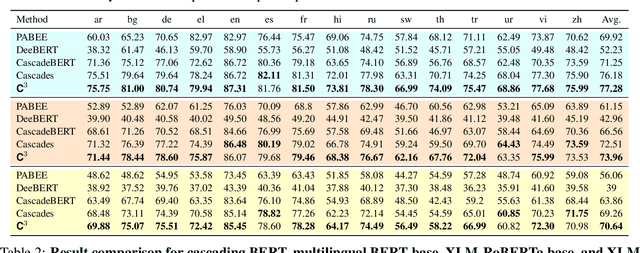

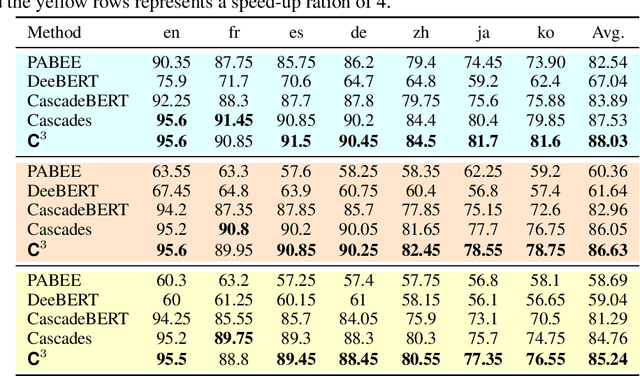
Cross-lingual natural language understanding (NLU) is a critical task in natural language processing (NLP). Recent advancements have seen multilingual pre-trained language models (mPLMs) significantly enhance the performance of these tasks. However, mPLMs necessitate substantial resources and incur high computational costs during inference, posing challenges for deployment in real-world and real-time systems. Existing model cascade methods seek to enhance inference efficiency by greedily selecting the lightest model capable of processing the current input from a variety of models, based on model confidence scores. Nonetheless, deep models tend to exhibit overconfidence, and confidence distributions vary across languages. This leads to the emission of confident but incorrect predictions by smaller models, hindering their ability to generalize effectively across test languages. In this study, we introduce a confidence calibration model cascade ($C^3$) method. This approach, simple yet effective, involves calibration prior to cascade inference, thereby enhancing cascade accuracy through more reliable predictions. Extensive experiments conducted on three cross-lingual benchmarks demonstrate that $C^3$ significantly outperforms all state-of-the-art baselines.
Mementos: A Comprehensive Benchmark for Multimodal Large Language Model Reasoning over Image Sequences
Jan 25, 2024



Multimodal Large Language Models (MLLMs) have demonstrated proficiency in handling a variety of visual-language tasks. However, current MLLM benchmarks are predominantly designed to evaluate reasoning based on static information about a single image, and the ability of modern MLLMs to extrapolate from image sequences, which is essential for understanding our ever-changing world, has been less investigated. To address this challenge, this paper introduces Mementos, a new benchmark designed to assess MLLMs' sequential image reasoning abilities. Mementos features 4,761 diverse image sequences with varying lengths. We also employ a GPT-4 assisted method to evaluate MLLM reasoning performance. Through a careful evaluation of nine recent MLLMs on Mementos, including GPT-4V and Gemini, we find that they struggle to accurately describe dynamic information about given image sequences, often leading to hallucinations/misrepresentations of objects and their corresponding behaviors. Our quantitative analysis and case studies identify three key factors impacting MLLMs' sequential image reasoning: the correlation between object and behavioral hallucinations, the influence of cooccurring behaviors, and the compounding impact of behavioral hallucinations. Our dataset is available at https://github.com/umd-huang-lab/Mementos.
A Simple LLM Framework for Long-Range Video Question-Answering
Dec 28, 2023
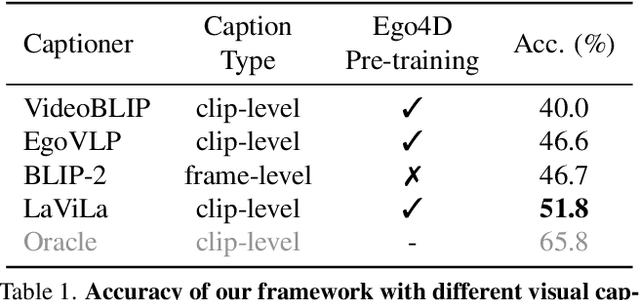
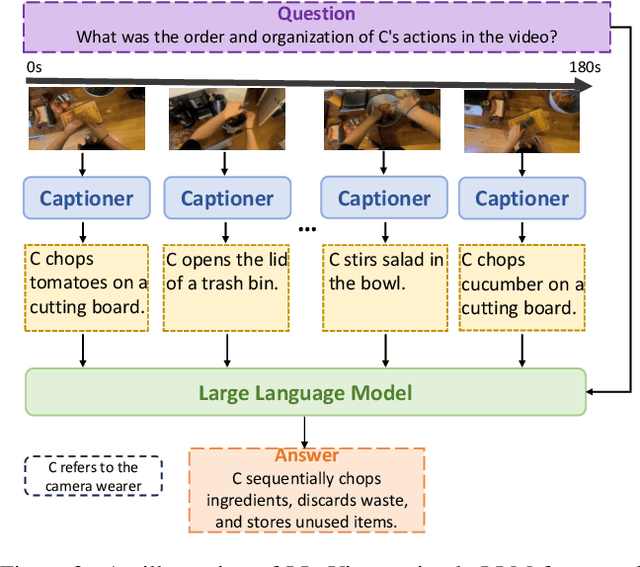

We present LLoVi, a language-based framework for long-range video question-answering (LVQA). Unlike prior long-range video understanding methods, which are often costly and require specialized long-range video modeling design (e.g., memory queues, state-space layers, etc.), our approach uses a frame/clip-level visual captioner (e.g., BLIP2, LaViLa, LLaVA) coupled with a Large Language Model (GPT-3.5, GPT-4) leading to a simple yet surprisingly effective LVQA framework. Specifically, we decompose short and long-range modeling aspects of LVQA into two stages. First, we use a short-term visual captioner to generate textual descriptions of short video clips (0.5-8s in length) densely sampled from a long input video. Afterward, an LLM aggregates the densely extracted short-term captions to perform long-range temporal reasoning needed to understand the whole video and answer a question. To analyze what makes our simple framework so effective, we thoroughly evaluate various components of our system. Our empirical analysis reveals that the choice of the visual captioner and LLM is critical for good LVQA performance. Furthermore, we show that a specialized prompt that asks the LLM first to summarize the noisy short-term visual captions and then answer a given input question leads to a significant LVQA performance boost. On EgoSchema, which is best known as a very long-form video question-answering benchmark, our method achieves 50.3% accuracy, outperforming the previous best-performing approach by 18.1% (absolute gain). In addition, our approach outperforms the previous state-of-the-art by 4.1% and 3.1% on NeXT-QA and IntentQA. We also extend LLoVi to grounded LVQA and show that it outperforms all prior methods on the NeXT-GQA dataset. We will release our code at https://github.com/CeeZh/LLoVi.