 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAre Video Reasoning Models Ready to Go Outside?
Mar 11, 2026In real-world deployment, vision-language models often encounter disturbances such as weather, occlusion, and camera motion. Under such conditions, their understanding and reasoning degrade substantially, revealing a gap between clean, controlled (i.e., unperturbed) evaluation settings and real-world robustness. To address this limitation, we propose ROVA, a novel training framework that improves robustness by modeling a robustness-aware consistency reward under spatio-temporal corruptions. ROVA introduces a difficulty-aware online training strategy that prioritizes informative samples based on the model's evolving capability. Specifically, it continuously re-estimates sample difficulty via self-reflective evaluation, enabling adaptive training with a robustness-aware consistency reward. We also introduce PVRBench, a new benchmark that injects real-world perturbations into embodied video datasets to assess both accuracy and reasoning quality under realistic disturbances. We evaluate ROVA and baselines on PVRBench, UrbanVideo, and VisBench, where open-source and proprietary models suffer up to 35% and 28% drops in accuracy and reasoning under realistic perturbations. ROVA effectively mitigates performance degradation, boosting relative accuracy by at least 24% and reasoning by over 9% compared with baseline models (QWen2.5/3-VL, InternVL2.5, Embodied-R). These gains transfer to clean standard benchmarks, yielding consistent improvements.
AnchorWeave: World-Consistent Video Generation with Retrieved Local Spatial Memories
Feb 16, 2026Maintaining spatial world consistency over long horizons remains a central challenge for camera-controllable video generation. Existing memory-based approaches often condition generation on globally reconstructed 3D scenes by rendering anchor videos from the reconstructed geometry in the history. However, reconstructing a global 3D scene from multiple views inevitably introduces cross-view misalignment, as pose and depth estimation errors cause the same surfaces to be reconstructed at slightly different 3D locations across views. When fused, these inconsistencies accumulate into noisy geometry that contaminates the conditioning signals and degrades generation quality. We introduce AnchorWeave, a memory-augmented video generation framework that replaces a single misaligned global memory with multiple clean local geometric memories and learns to reconcile their cross-view inconsistencies. To this end, AnchorWeave performs coverage-driven local memory retrieval aligned with the target trajectory and integrates the selected local memories through a multi-anchor weaving controller during generation. Extensive experiments demonstrate that AnchorWeave significantly improves long-term scene consistency while maintaining strong visual quality, with ablation and analysis studies further validating the effectiveness of local geometric conditioning, multi-anchor control, and coverage-driven retrieval.
When and How Much to Imagine: Adaptive Test-Time Scaling with World Models for Visual Spatial Reasoning
Feb 09, 2026Despite rapid progress in Multimodal Large Language Models (MLLMs), visual spatial reasoning remains unreliable when correct answers depend on how a scene would appear under unseen or alternative viewpoints. Recent work addresses this by augmenting reasoning with world models for visual imagination, but questions such as when imagination is actually necessary, how much of it is beneficial, and when it becomes harmful, remain poorly understood. In practice, indiscriminate imagination can increase computation and even degrade performance by introducing misleading evidence. In this work, we present an in-depth analysis of test-time visual imagination as a controllable resource for spatial reasoning. We study when static visual evidence is sufficient, when imagination improves reasoning, and how excessive or unnecessary imagination affects accuracy and efficiency. To support this analysis, we introduce AVIC, an adaptive test-time framework with world models that explicitly reasons about the sufficiency of current visual evidence before selectively invoking and scaling visual imagination. Across spatial reasoning benchmarks (SAT, MMSI) and an embodied navigation benchmark (R2R), our results reveal clear scenarios where imagination is critical, marginal, or detrimental, and show that selective control can match or outperform fixed imagination strategies with substantially fewer world-model calls and language tokens. Overall, our findings highlight the importance of analyzing and controlling test-time imagination for efficient and reliable spatial reasoning.
Reliable and Responsible Foundation Models: A Comprehensive Survey
Feb 04, 2026Foundation models, including Large Language Models (LLMs), Multimodal Large Language Models (MLLMs), Image Generative Models (i.e, Text-to-Image Models and Image-Editing Models), and Video Generative Models, have become essential tools with broad applications across various domains such as law, medicine, education, finance, science, and beyond. As these models see increasing real-world deployment, ensuring their reliability and responsibility has become critical for academia, industry, and government. This survey addresses the reliable and responsible development of foundation models. We explore critical issues, including bias and fairness, security and privacy, uncertainty, explainability, and distribution shift. Our research also covers model limitations, such as hallucinations, as well as methods like alignment and Artificial Intelligence-Generated Content (AIGC) detection. For each area, we review the current state of the field and outline concrete future research directions. Additionally, we discuss the intersections between these areas, highlighting their connections and shared challenges. We hope our survey fosters the development of foundation models that are not only powerful but also ethical, trustworthy, reliable, and socially responsible.
Self-Refining Video Sampling
Jan 26, 2026Modern video generators still struggle with complex physical dynamics, often falling short of physical realism. Existing approaches address this using external verifiers or additional training on augmented data, which is computationally expensive and still limited in capturing fine-grained motion. In this work, we present self-refining video sampling, a simple method that uses a pre-trained video generator trained on large-scale datasets as its own self-refiner. By interpreting the generator as a denoising autoencoder, we enable iterative inner-loop refinement at inference time without any external verifier or additional training. We further introduce an uncertainty-aware refinement strategy that selectively refines regions based on self-consistency, which prevents artifacts caused by over-refinement. Experiments on state-of-the-art video generators demonstrate significant improvements in motion coherence and physics alignment, achieving over 70\% human preference compared to the default sampler and guidance-based sampler.
Avatar Forcing: Real-Time Interactive Head Avatar Generation for Natural Conversation
Jan 02, 2026Talking head generation creates lifelike avatars from static portraits for virtual communication and content creation. However, current models do not yet convey the feeling of truly interactive communication, often generating one-way responses that lack emotional engagement. We identify two key challenges toward truly interactive avatars: generating motion in real-time under causal constraints and learning expressive, vibrant reactions without additional labeled data. To address these challenges, we propose Avatar Forcing, a new framework for interactive head avatar generation that models real-time user-avatar interactions through diffusion forcing. This design allows the avatar to process real-time multimodal inputs, including the user's audio and motion, with low latency for instant reactions to both verbal and non-verbal cues such as speech, nods, and laughter. Furthermore, we introduce a direct preference optimization method that leverages synthetic losing samples constructed by dropping user conditions, enabling label-free learning of expressive interaction. Experimental results demonstrate that our framework enables real-time interaction with low latency (approximately 500ms), achieving 6.8X speedup compared to the baseline, and produces reactive and expressive avatar motion, which is preferred over 80% against the baseline.
MedForget: Hierarchy-Aware Multimodal Unlearning Testbed for Medical AI
Dec 10, 2025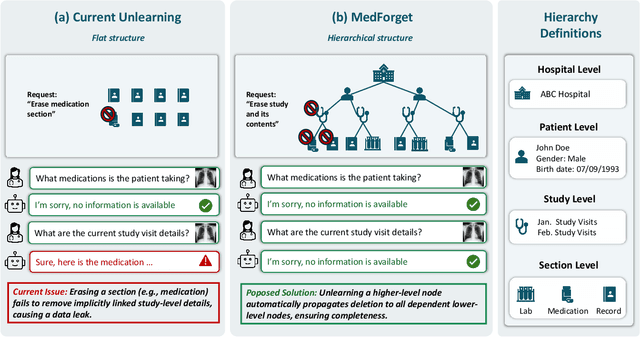

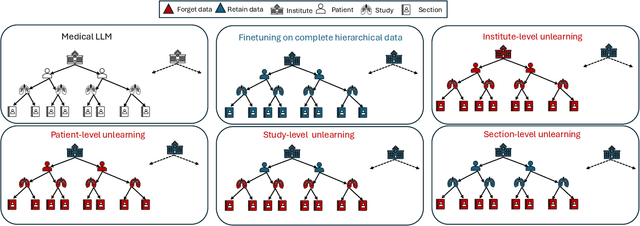

Pretrained Multimodal Large Language Models (MLLMs) are increasingly deployed in medical AI systems for clinical reasoning, diagnosis support, and report generation. However, their training on sensitive patient data raises critical privacy and compliance challenges under regulations such as HIPAA and GDPR, which enforce the "right to be forgotten". Unlearning, the process of tuning models to selectively remove the influence of specific training data points, offers a potential solution, yet its effectiveness in complex medical settings remains underexplored. To systematically study this, we introduce MedForget, a Hierarchy-Aware Multimodal Unlearning Testbed with explicit retain and forget splits and evaluation sets containing rephrased variants. MedForget models hospital data as a nested hierarchy (Institution -> Patient -> Study -> Section), enabling fine-grained assessment across eight organizational levels. The benchmark contains 3840 multimodal (image, question, answer) instances, each hierarchy level having a dedicated unlearning target, reflecting distinct unlearning challenges. Experiments with four SOTA unlearning methods on three tasks (generation, classification, cloze) show that existing methods struggle to achieve complete, hierarchy-aware forgetting without reducing diagnostic performance. To test whether unlearning truly deletes hierarchical pathways, we introduce a reconstruction attack that progressively adds hierarchical level context to prompts. Models unlearned at a coarse granularity show strong resistance, while fine-grained unlearning leaves models vulnerable to such reconstruction. MedForget provides a practical, HIPAA-aligned testbed for building compliant medical AI systems.
Video-RTS: Rethinking Reinforcement Learning and Test-Time Scaling for Efficient and Enhanced Video Reasoning
Jul 09, 2025Despite advances in reinforcement learning (RL)-based video reasoning with large language models (LLMs), data collection and finetuning remain significant challenges. These methods often rely on large-scale supervised fine-tuning (SFT) with extensive video data and long Chain-of-Thought (CoT) annotations, making them costly and hard to scale. To address this, we present Video-RTS, a new approach to improve video reasoning capability with drastically improved data efficiency by combining data-efficient RL with a video-adaptive test-time scaling (TTS) strategy. Based on observations about the data scaling of RL samples, we skip the resource-intensive SFT step and employ efficient pure-RL training with output-based rewards, requiring no additional annotations or extensive fine-tuning. Furthermore, to utilize computational resources more efficiently, we introduce a sparse-to-dense video TTS strategy that improves inference by iteratively adding frames based on output consistency. We validate our approach on multiple video reasoning benchmarks, showing that Video-RTS surpasses existing video reasoning models by an average of 2.4% in accuracy using only 3.6% training samples. For example, Video-RTS achieves a 4.2% improvement on Video-Holmes, a recent and challenging video reasoning benchmark, and a 2.6% improvement on MMVU. Notably, our pure RL training and adaptive video TTS offer complementary strengths, enabling Video-RTS's strong reasoning performance.
Frame Guidance: Training-Free Guidance for Frame-Level Control in Video Diffusion Models
Jun 08, 2025Advancements in diffusion models have significantly improved video quality, directing attention to fine-grained controllability. However, many existing methods depend on fine-tuning large-scale video models for specific tasks, which becomes increasingly impractical as model sizes continue to grow. In this work, we present Frame Guidance, a training-free guidance for controllable video generation based on frame-level signals, such as keyframes, style reference images, sketches, or depth maps. For practical training-free guidance, we propose a simple latent processing method that dramatically reduces memory usage, and apply a novel latent optimization strategy designed for globally coherent video generation. Frame Guidance enables effective control across diverse tasks, including keyframe guidance, stylization, and looping, without any training, compatible with any video models. Experimental results show that Frame Guidance can produce high-quality controlled videos for a wide range of tasks and input signals.
Movie Facts and Fibs (MF$^2$): A Benchmark for Long Movie Understanding
Jun 06, 2025Despite recent progress in vision-language models (VLMs), holistic understanding of long-form video content remains a significant challenge, partly due to limitations in current benchmarks. Many focus on peripheral, ``needle-in-a-haystack'' details, encouraging context-insensitive retrieval over deep comprehension. Others rely on large-scale, semi-automatically generated questions (often produced by language models themselves) that are easier for models to answer but fail to reflect genuine understanding. In this paper, we introduce MF$^2$, a new benchmark for evaluating whether models can comprehend, consolidate, and recall key narrative information from full-length movies (50-170 minutes long). MF$^2$ includes over 50 full-length, open-licensed movies, each paired with manually constructed sets of claim pairs -- one true (fact) and one plausible but false (fib), totalling over 850 pairs. These claims target core narrative elements such as character motivations and emotions, causal chains, and event order, and refer to memorable moments that humans can recall without rewatching the movie. Instead of multiple-choice formats, we adopt a binary claim evaluation protocol: for each pair, models must correctly identify both the true and false claims. This reduces biases like answer ordering and enables a more precise assessment of reasoning. Our experiments demonstrate that both open-weight and closed state-of-the-art models fall well short of human performance, underscoring the relative ease of the task for humans and their superior ability to retain and reason over critical narrative information -- an ability current VLMs lack.