 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Refining Video Sampling
Jan 26, 2026Modern video generators still struggle with complex physical dynamics, often falling short of physical realism. Existing approaches address this using external verifiers or additional training on augmented data, which is computationally expensive and still limited in capturing fine-grained motion. In this work, we present self-refining video sampling, a simple method that uses a pre-trained video generator trained on large-scale datasets as its own self-refiner. By interpreting the generator as a denoising autoencoder, we enable iterative inner-loop refinement at inference time without any external verifier or additional training. We further introduce an uncertainty-aware refinement strategy that selectively refines regions based on self-consistency, which prevents artifacts caused by over-refinement. Experiments on state-of-the-art video generators demonstrate significant improvements in motion coherence and physics alignment, achieving over 70\% human preference compared to the default sampler and guidance-based sampler.
Avatar Forcing: Real-Time Interactive Head Avatar Generation for Natural Conversation
Jan 02, 2026Talking head generation creates lifelike avatars from static portraits for virtual communication and content creation. However, current models do not yet convey the feeling of truly interactive communication, often generating one-way responses that lack emotional engagement. We identify two key challenges toward truly interactive avatars: generating motion in real-time under causal constraints and learning expressive, vibrant reactions without additional labeled data. To address these challenges, we propose Avatar Forcing, a new framework for interactive head avatar generation that models real-time user-avatar interactions through diffusion forcing. This design allows the avatar to process real-time multimodal inputs, including the user's audio and motion, with low latency for instant reactions to both verbal and non-verbal cues such as speech, nods, and laughter. Furthermore, we introduce a direct preference optimization method that leverages synthetic losing samples constructed by dropping user conditions, enabling label-free learning of expressive interaction. Experimental results demonstrate that our framework enables real-time interaction with low latency (approximately 500ms), achieving 6.8X speedup compared to the baseline, and produces reactive and expressive avatar motion, which is preferred over 80% against the baseline.
Frame Guidance: Training-Free Guidance for Frame-Level Control in Video Diffusion Models
Jun 08, 2025Advancements in diffusion models have significantly improved video quality, directing attention to fine-grained controllability. However, many existing methods depend on fine-tuning large-scale video models for specific tasks, which becomes increasingly impractical as model sizes continue to grow. In this work, we present Frame Guidance, a training-free guidance for controllable video generation based on frame-level signals, such as keyframes, style reference images, sketches, or depth maps. For practical training-free guidance, we propose a simple latent processing method that dramatically reduces memory usage, and apply a novel latent optimization strategy designed for globally coherent video generation. Frame Guidance enables effective control across diverse tasks, including keyframe guidance, stylization, and looping, without any training, compatible with any video models. Experimental results show that Frame Guidance can produce high-quality controlled videos for a wide range of tasks and input signals.
FLOAT: Generative Motion Latent Flow Matching for Audio-driven Talking Portrait
Dec 02, 2024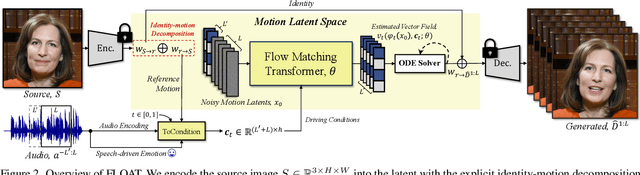
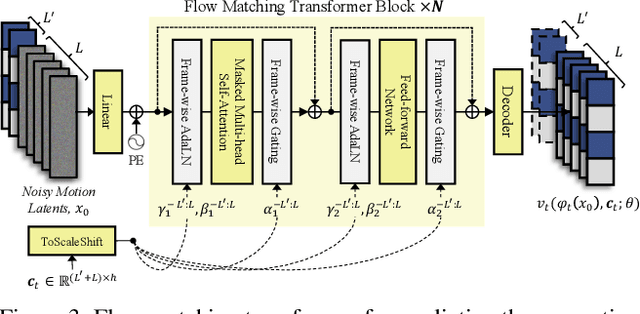

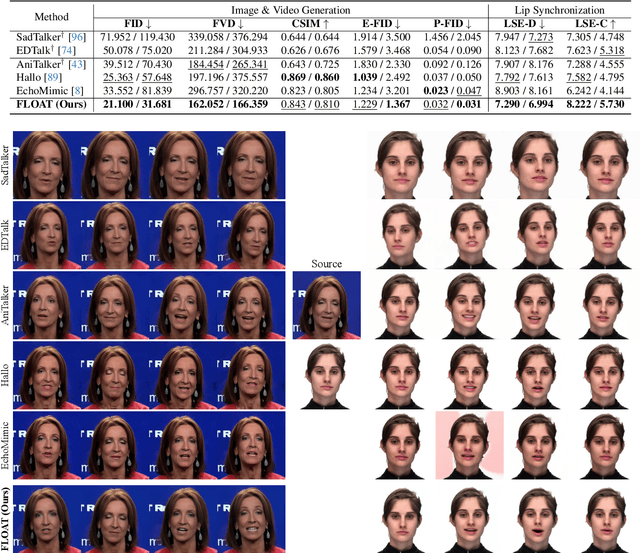
With the rapid advancement of diffusion-based generative models, portrait image animation has achieved remarkable results. However, it still faces challenges in temporally consistent video generation and fast sampling due to its iterative sampling nature. This paper presents FLOAT, an audio-driven talking portrait video generation method based on flow matching generative model. We shift the generative modeling from the pixel-based latent space to a learned motion latent space, enabling efficient design of temporally consistent motion. To achieve this, we introduce a transformer-based vector field predictor with a simple yet effective frame-wise conditioning mechanism. Additionally, our method supports speech-driven emotion enhancement, enabling a natural incorporation of expressive motions. Extensive experiments demonstrate that our method outperforms state-of-the-art audio-driven talking portrait methods in terms of visual quality, motion fidelity, and efficiency.
Learning to Generate Conditional Tri-plane for 3D-aware Expression Controllable Portrait Animation
Apr 02, 2024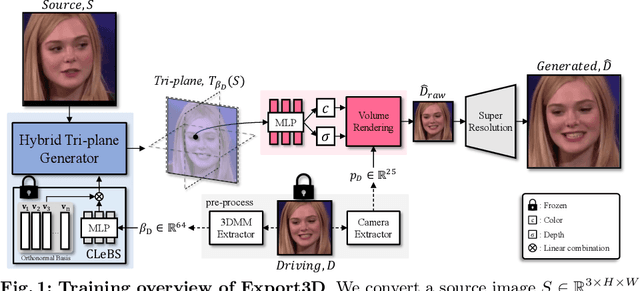
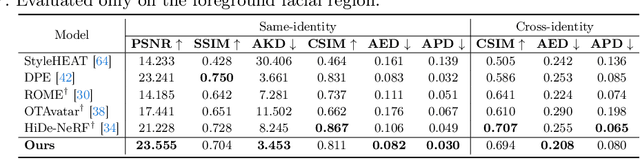
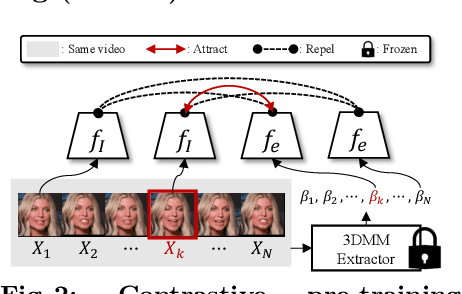
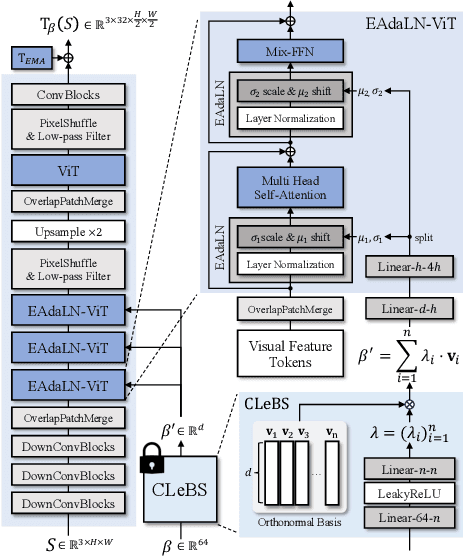
In this paper, we present Export3D, a one-shot 3D-aware portrait animation method that is able to control the facial expression and camera view of a given portrait image. To achieve this, we introduce a tri-plane generator that directly generates a tri-plane of 3D prior by transferring the expression parameter of 3DMM into the source image. The tri-plane is then decoded into the image of different view through a differentiable volume rendering. Existing portrait animation methods heavily rely on image warping to transfer the expression in the motion space, challenging on disentanglement of appearance and expression. In contrast, we propose a contrastive pre-training framework for appearance-free expression parameter, eliminating undesirable appearance swap when transferring a cross-identity expression. Extensive experiments show that our pre-training framework can learn the appearance-free expression representation hidden in 3DMM, and our model can generate 3D-aware expression controllable portrait image without appearance swap in the cross-identity manner.
StyleLipSync: Style-based Personalized Lip-sync Video Generation
Apr 30, 2023In this paper, we present StyleLipSync, a style-based personalized lip-sync video generative model that can generate identity-agnostic lip-synchronizing video from arbitrary audio. To generate a video of arbitrary identities, we leverage expressive lip prior from the semantically rich latent space of a pre-trained StyleGAN, where we can also design a video consistency with a linear transformation. In contrast to the previous lip-sync methods, we introduce pose-aware masking that dynamically locates the mask to improve the naturalness over frames by utilizing a 3D parametric mesh predictor frame by frame. Moreover, we propose a few-shot lip-sync adaptation method for an arbitrary person by introducing a sync regularizer that preserves lips-sync generalization while enhancing the person-specific visual information. Extensive experiments demonstrate that our model can generate accurate lip-sync videos even with the zero-shot setting and enhance characteristics of an unseen face using a few seconds of target video through the proposed adaptation method. Please refer to our project page.