 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFLOAT: Generative Motion Latent Flow Matching for Audio-driven Talking Portrait
Dec 02, 2024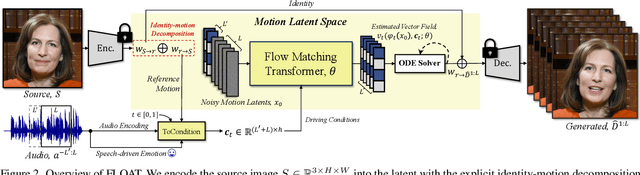
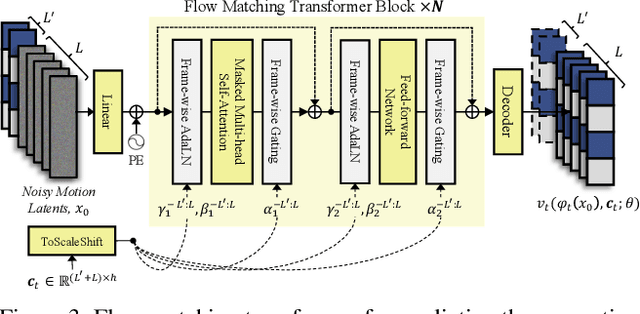

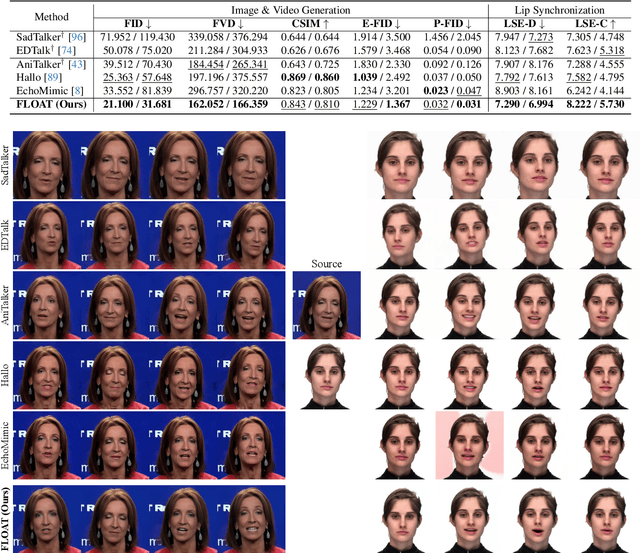
With the rapid advancement of diffusion-based generative models, portrait image animation has achieved remarkable results. However, it still faces challenges in temporally consistent video generation and fast sampling due to its iterative sampling nature. This paper presents FLOAT, an audio-driven talking portrait video generation method based on flow matching generative model. We shift the generative modeling from the pixel-based latent space to a learned motion latent space, enabling efficient design of temporally consistent motion. To achieve this, we introduce a transformer-based vector field predictor with a simple yet effective frame-wise conditioning mechanism. Additionally, our method supports speech-driven emotion enhancement, enabling a natural incorporation of expressive motions. Extensive experiments demonstrate that our method outperforms state-of-the-art audio-driven talking portrait methods in terms of visual quality, motion fidelity, and efficiency.
Learning to Generate Conditional Tri-plane for 3D-aware Expression Controllable Portrait Animation
Apr 02, 2024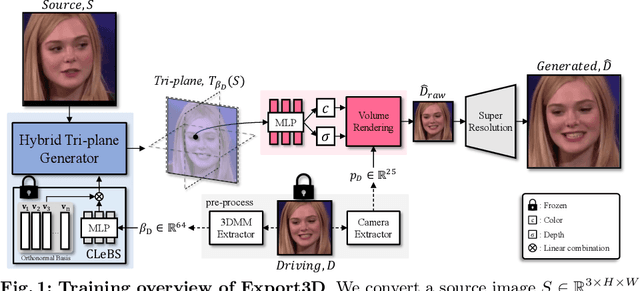
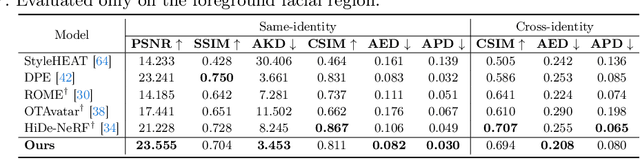
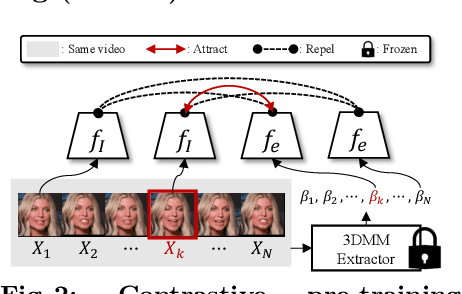
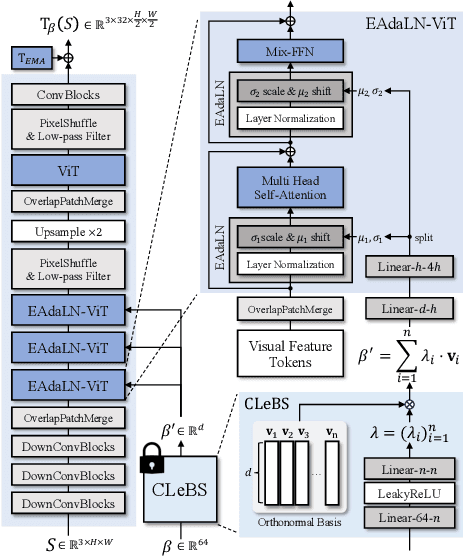
In this paper, we present Export3D, a one-shot 3D-aware portrait animation method that is able to control the facial expression and camera view of a given portrait image. To achieve this, we introduce a tri-plane generator that directly generates a tri-plane of 3D prior by transferring the expression parameter of 3DMM into the source image. The tri-plane is then decoded into the image of different view through a differentiable volume rendering. Existing portrait animation methods heavily rely on image warping to transfer the expression in the motion space, challenging on disentanglement of appearance and expression. In contrast, we propose a contrastive pre-training framework for appearance-free expression parameter, eliminating undesirable appearance swap when transferring a cross-identity expression. Extensive experiments show that our pre-training framework can learn the appearance-free expression representation hidden in 3DMM, and our model can generate 3D-aware expression controllable portrait image without appearance swap in the cross-identity manner.
Context-Preserving Two-Stage Video Domain Translation for Portrait Stylization
May 30, 2023



Portrait stylization, which translates a real human face image into an artistically stylized image, has attracted considerable interest and many prior works have shown impressive quality in recent years. However, despite their remarkable performances in the image-level translation tasks, prior methods show unsatisfactory results when they are applied to the video domain. To address the issue, we propose a novel two-stage video translation framework with an objective function which enforces a model to generate a temporally coherent stylized video while preserving context in the source video. Furthermore, our model runs in real-time with the latency of 0.011 seconds per frame and requires only 5.6M parameters, and thus is widely applicable to practical real-world applications.
StyleLipSync: Style-based Personalized Lip-sync Video Generation
Apr 30, 2023In this paper, we present StyleLipSync, a style-based personalized lip-sync video generative model that can generate identity-agnostic lip-synchronizing video from arbitrary audio. To generate a video of arbitrary identities, we leverage expressive lip prior from the semantically rich latent space of a pre-trained StyleGAN, where we can also design a video consistency with a linear transformation. In contrast to the previous lip-sync methods, we introduce pose-aware masking that dynamically locates the mask to improve the naturalness over frames by utilizing a 3D parametric mesh predictor frame by frame. Moreover, we propose a few-shot lip-sync adaptation method for an arbitrary person by introducing a sync regularizer that preserves lips-sync generalization while enhancing the person-specific visual information. Extensive experiments demonstrate that our model can generate accurate lip-sync videos even with the zero-shot setting and enhance characteristics of an unseen face using a few seconds of target video through the proposed adaptation method. Please refer to our project page.
Any-speaker Adaptive Text-To-Speech Synthesis with Diffusion Models
Nov 17, 2022There has been a significant progress in Text-To-Speech (TTS) synthesis technology in recent years, thanks to the advancement in neural generative modeling. However, existing methods on any-speaker adaptive TTS have achieved unsatisfactory performance, due to their suboptimal accuracy in mimicking the target speakers' styles. In this work, we present Grad-StyleSpeech, which is an any-speaker adaptive TTS framework that is based on a diffusion model that can generate highly natural speech with extremely high similarity to target speakers' voice, given a few seconds of reference speech. Grad-StyleSpeech significantly outperforms recent speaker-adaptive TTS baselines on English benchmarks. Audio samples are available at https://nardien.github.io/grad-stylespeech-demo.
StyleTalker: One-shot Style-based Audio-driven Talking Head Video Generation
Aug 23, 2022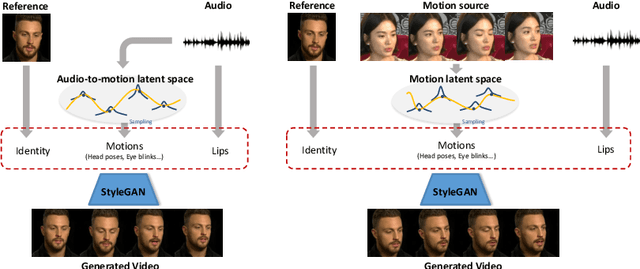

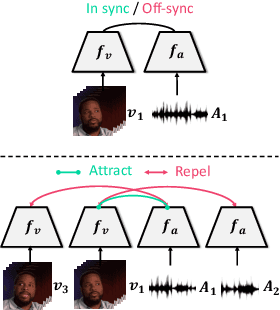

We propose StyleTalker, a novel audio-driven talking head generation model that can synthesize a video of a talking person from a single reference image with accurately audio-synced lip shapes, realistic head poses, and eye blinks. Specifically, by leveraging a pretrained image generator and an image encoder, we estimate the latent codes of the talking head video that faithfully reflects the given audio. This is made possible with several newly devised components: 1) A contrastive lip-sync discriminator for accurate lip synchronization, 2) A conditional sequential variational autoencoder that learns the latent motion space disentangled from the lip movements, such that we can independently manipulate the motions and lip movements while preserving the identity. 3) An auto-regressive prior augmented with normalizing flow to learn a complex audio-to-motion multi-modal latent space. Equipped with these components, StyleTalker can generate talking head videos not only in a motion-controllable way when another motion source video is given but also in a completely audio-driven manner by inferring realistic motions from the input audio. Through extensive experiments and user studies, we show that our model is able to synthesize talking head videos with impressive perceptual quality which are accurately lip-synced with the input audios, largely outperforming state-of-the-art baselines.
Distortion-Aware Network Pruning and Feature Reuse for Real-time Video Segmentation
Jun 20, 2022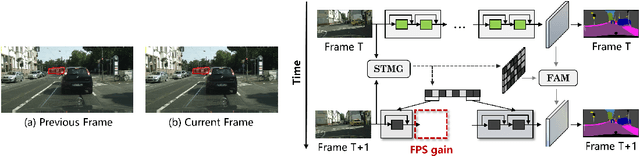
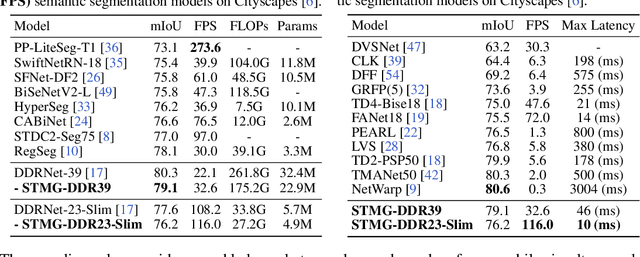
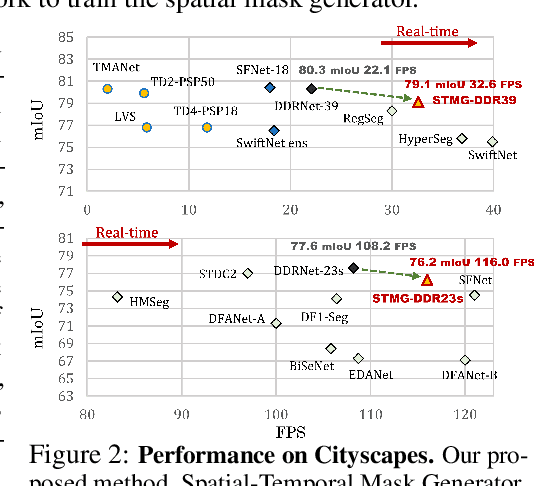
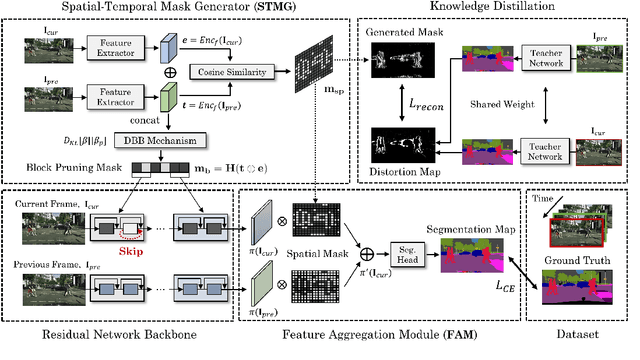
Real-time video segmentation is a crucial task for many real-world applications such as autonomous driving and robot control. Since state-of-the-art semantic segmentation models are often too heavy for real-time applications despite their impressive performance, researchers have proposed lightweight architectures with speed-accuracy trade-offs, achieving real-time speed at the expense of reduced accuracy. In this paper, we propose a novel framework to speed up any architecture with skip-connections for real-time vision tasks by exploiting the temporal locality in videos. Specifically, at the arrival of each frame, we transform the features from the previous frame to reuse them at specific spatial bins. We then perform partial computation of the backbone network on the regions of the current frame that captures temporal differences between the current and previous frame. This is done by dynamically dropping out residual blocks using a gating mechanism which decides which blocks to drop based on inter-frame distortion. We validate our Spatial-Temporal Mask Generator (STMG) on video semantic segmentation benchmarks with multiple backbone networks, and show that our method largely speeds up inference with minimal loss of accuracy.
Meta-StyleSpeech : Multi-Speaker Adaptive Text-to-Speech Generation
Jun 16, 2021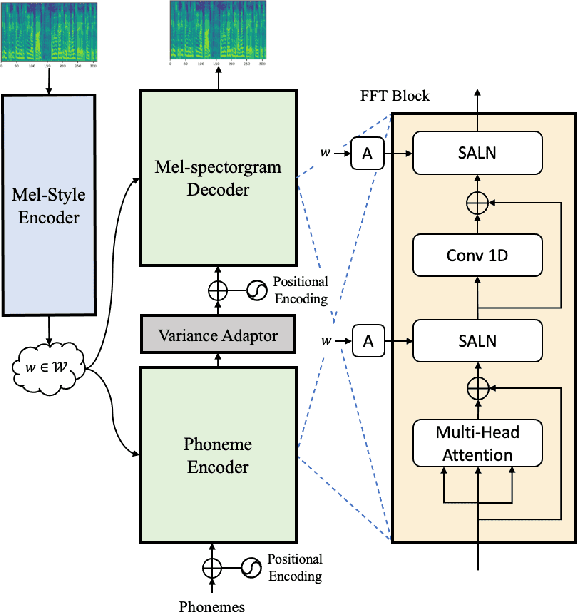
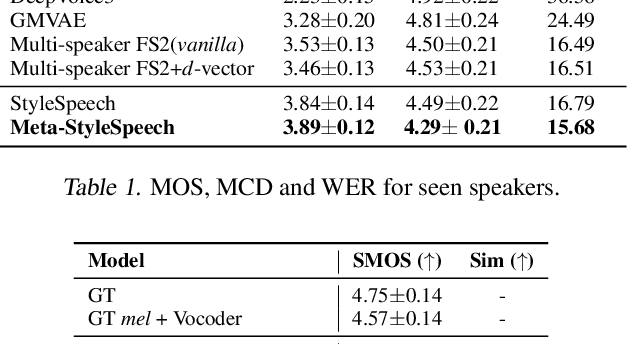
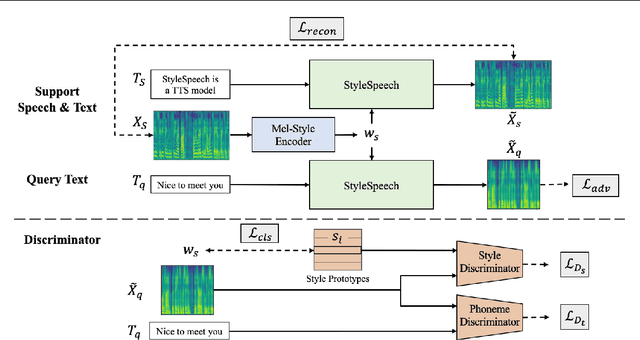

With rapid progress in neural text-to-speech (TTS) models, personalized speech generation is now in high demand for many applications. For practical applicability, a TTS model should generate high-quality speech with only a few audio samples from the given speaker, that are also short in length. However, existing methods either require to fine-tune the model or achieve low adaptation quality without fine-tuning. In this work, we propose StyleSpeech, a new TTS model which not only synthesizes high-quality speech but also effectively adapts to new speakers. Specifically, we propose Style-Adaptive Layer Normalization (SALN) which aligns gain and bias of the text input according to the style extracted from a reference speech audio. With SALN, our model effectively synthesizes speech in the style of the target speaker even from single speech audio. Furthermore, to enhance StyleSpeech's adaptation to speech from new speakers, we extend it to Meta-StyleSpeech by introducing two discriminators trained with style prototypes, and performing episodic training. The experimental results show that our models generate high-quality speech which accurately follows the speaker's voice with single short-duration (1-3 sec) speech audio, significantly outperforming baselines.