 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRead, Watch and Scream! Sound Generation from Text and Video
Jul 08, 2024
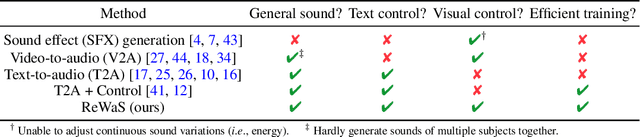


Multimodal generative models have shown impressive advances with the help of powerful diffusion models. Despite the progress, generating sound solely from text poses challenges in ensuring comprehensive scene depiction and temporal alignment. Meanwhile, video-to-sound generation limits the flexibility to prioritize sound synthesis for specific objects within the scene. To tackle these challenges, we propose a novel video-and-text-to-sound generation method, called ReWaS, where video serves as a conditional control for a text-to-audio generation model. Our method estimates the structural information of audio (namely, energy) from the video while receiving key content cues from a user prompt. We employ a well-performing text-to-sound model to consolidate the video control, which is much more efficient for training multimodal diffusion models with massive triplet-paired (audio-video-text) data. In addition, by separating the generative components of audio, it becomes a more flexible system that allows users to freely adjust the energy, surrounding environment, and primary sound source according to their preferences. Experimental results demonstrate that our method shows superiority in terms of quality, controllability, and training efficiency. Our demo is available at https://naver-ai.github.io/rewas
Lifelong Audio-video Masked Autoencoder with Forget-robust Localized Alignments
Oct 12, 2023We present a lifelong audio-video masked autoencoder that continually learns the multimodal representations from a video stream containing audio-video pairs, while its distribution continually shifts over time. Specifically, we propose two novel ideas to tackle the problem: (1) Localized Alignment: We introduce a small trainable multimodal encoder that predicts the audio and video tokens that are well-aligned with each other. This allows the model to learn only the highly correlated audiovisual patches with accurate multimodal relationships. (2) Forget-robust multimodal patch selection: We compare the relative importance of each audio-video patch between the current and past data pair to mitigate unintended drift of the previously learned audio-video representations. Our proposed method, FLAVA (Forget-robust Localized Audio-Video Alignment), therefore, captures the complex relationships between the audio and video modalities during training on a sequence of pre-training tasks while alleviating the forgetting of learned audiovisual correlations. Our experiments validate that FLAVA outperforms the state-of-the-art continual learning methods on several benchmark datasets under continual audio-video representation learning scenarios.
Dense Text-to-Image Generation with Attention Modulation
Aug 24, 2023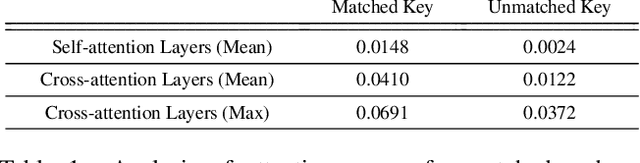



Existing text-to-image diffusion models struggle to synthesize realistic images given dense captions, where each text prompt provides a detailed description for a specific image region. To address this, we propose DenseDiffusion, a training-free method that adapts a pre-trained text-to-image model to handle such dense captions while offering control over the scene layout. We first analyze the relationship between generated images' layouts and the pre-trained model's intermediate attention maps. Next, we develop an attention modulation method that guides objects to appear in specific regions according to layout guidance. Without requiring additional fine-tuning or datasets, we improve image generation performance given dense captions regarding both automatic and human evaluation scores. In addition, we achieve similar-quality visual results with models specifically trained with layout conditions.
Context-Preserving Two-Stage Video Domain Translation for Portrait Stylization
May 30, 2023



Portrait stylization, which translates a real human face image into an artistically stylized image, has attracted considerable interest and many prior works have shown impressive quality in recent years. However, despite their remarkable performances in the image-level translation tasks, prior methods show unsatisfactory results when they are applied to the video domain. To address the issue, we propose a novel two-stage video translation framework with an objective function which enforces a model to generate a temporally coherent stylized video while preserving context in the source video. Furthermore, our model runs in real-time with the latency of 0.011 seconds per frame and requires only 5.6M parameters, and thus is widely applicable to practical real-world applications.
Custom-Edit: Text-Guided Image Editing with Customized Diffusion Models
May 25, 2023Text-to-image diffusion models can generate diverse, high-fidelity images based on user-provided text prompts. Recent research has extended these models to support text-guided image editing. While text guidance is an intuitive editing interface for users, it often fails to ensure the precise concept conveyed by users. To address this issue, we propose Custom-Edit, in which we (i) customize a diffusion model with a few reference images and then (ii) perform text-guided editing. Our key discovery is that customizing only language-relevant parameters with augmented prompts improves reference similarity significantly while maintaining source similarity. Moreover, we provide our recipe for each customization and editing process. We compare popular customization methods and validate our findings on two editing methods using various datasets.
Text-Conditioned Sampling Framework for Text-to-Image Generation with Masked Generative Models
Apr 04, 2023Token-based masked generative models are gaining popularity for their fast inference time with parallel decoding. While recent token-based approaches achieve competitive performance to diffusion-based models, their generation performance is still suboptimal as they sample multiple tokens simultaneously without considering the dependence among them. We empirically investigate this problem and propose a learnable sampling model, Text-Conditioned Token Selection (TCTS), to select optimal tokens via localized supervision with text information. TCTS improves not only the image quality but also the semantic alignment of the generated images with the given texts. To further improve the image quality, we introduce a cohesive sampling strategy, Frequency Adaptive Sampling (FAS), to each group of tokens divided according to the self-attention maps. We validate the efficacy of TCTS combined with FAS with various generative tasks, demonstrating that it significantly outperforms the baselines in image-text alignment and image quality. Our text-conditioned sampling framework further reduces the original inference time by more than 50% without modifying the original generative model.
Mutual Information Divergence: A Unified Metric for Multimodal Generative Models
May 25, 2022
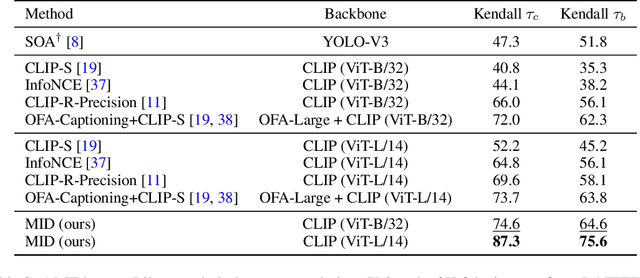
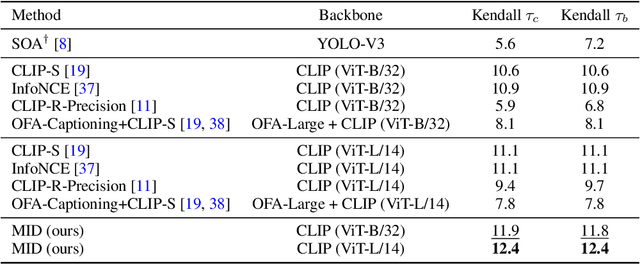
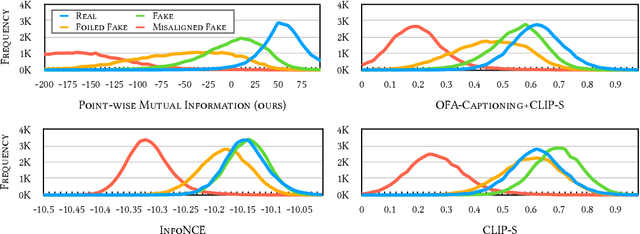
Text-to-image generation and image captioning are recently emerged as a new experimental paradigm to assess machine intelligence. They predict continuous quantity accompanied by their sampling techniques in the generation, making evaluation complicated and intractable to get marginal distributions. Based on a recent trend that multimodal generative evaluations exploit a vison-and-language pre-trained model, we propose the negative Gaussian cross-mutual information using the CLIP features as a unified metric, coined by Mutual Information Divergence (MID). To validate, we extensively compare it with competing metrics using carefully-generated or human-annotated judgments in text-to-image generation and image captioning tasks. The proposed MID significantly outperforms the competitive methods by having consistency across benchmarks, sample parsimony, and robustness toward the exploited CLIP model. We look forward to seeing the underrepresented implications of the Gaussian cross-mutual information in multimodal representation learning and the future works based on this novel proposition.
Contrastive Fine-grained Class Clustering via Generative Adversarial Networks
Dec 30, 2021
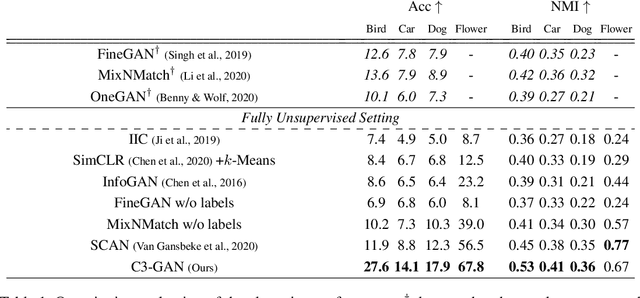
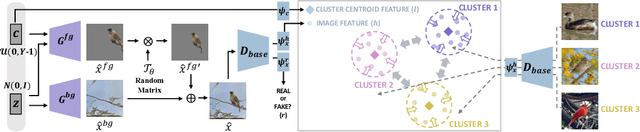

Unsupervised fine-grained class clustering is practical yet challenging task due to the difficulty of feature representations learning of subtle object details. We introduce C3-GAN, a method that leverages the categorical inference power of InfoGAN by applying contrastive learning. We aim to learn feature representations that encourage the data to form distinct cluster boundaries in the embedding space, while also maximizing the mutual information between the latent code and its observation. Our approach is to train the discriminator, which is used for inferring clusters, to optimize the contrastive loss, where the image-latent pairs that maximize the mutual information are considered as positive pairs and the rest as negative pairs. Specifically, we map the input of the generator, which has sampled from the categorical distribution, to the embedding space of the discriminator and let them act as a cluster centroid. In this way, C3-GAN achieved to learn a clustering-friendly embedding space where each cluster is distinctively separable. Experimental results show that C3-GAN achieved state-of-the-art clustering performance on four fine-grained benchmark datasets, while also alleviating the mode collapse phenomenon.
Unsupervised Keypoint Learning for Guiding Class-Conditional Video Prediction
Oct 04, 2019

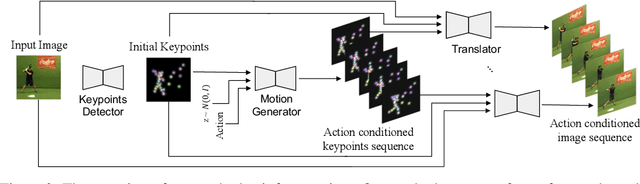
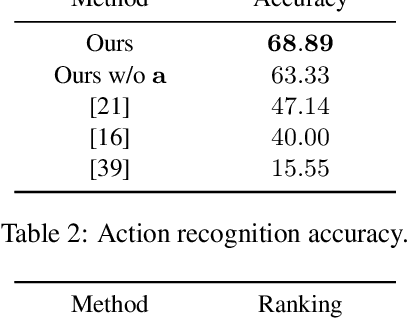
We propose a deep video prediction model conditioned on a single image and an action class. To generate future frames, we first detect keypoints of a moving object and predict future motion as a sequence of keypoints. The input image is then translated following the predicted keypoints sequence to compose future frames. Detecting the keypoints is central to our algorithm, and our method is trained to detect the keypoints of arbitrary objects in an unsupervised manner. Moreover, the detected keypoints of the original videos are used as pseudo-labels to learn the motion of objects. Experimental results show that our method is successfully applied to various datasets without the cost of labeling keypoints in videos. The detected keypoints are similar to human-annotated labels, and prediction results are more realistic compared to the previous methods.
Text-Adaptive Generative Adversarial Networks: Manipulating Images with Natural Language
Oct 29, 2018
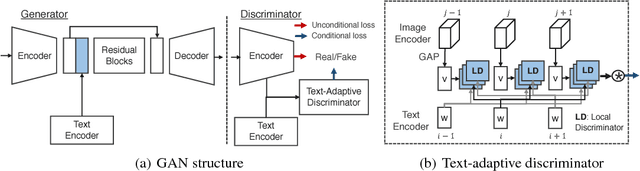

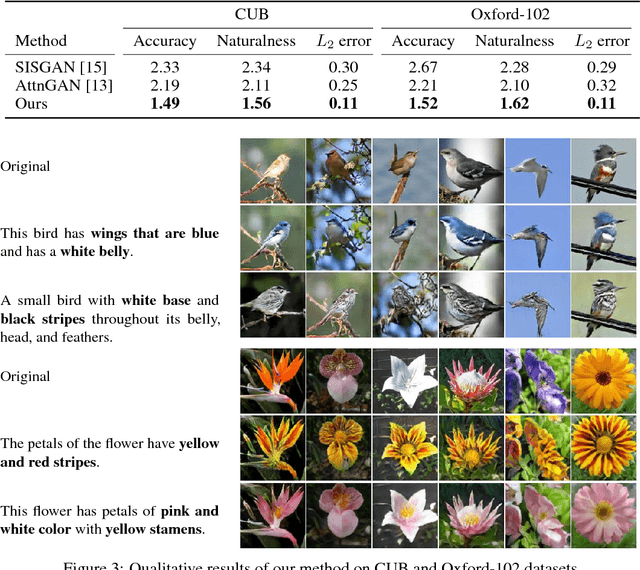
This paper addresses the problem of manipulating images using natural language description. Our task aims to semantically modify visual attributes of an object in an image according to the text describing the new visual appearance. Although existing methods synthesize images having new attributes, they do not fully preserve text-irrelevant contents of the original image. In this paper, we propose the text-adaptive generative adversarial network (TAGAN) to generate semantically manipulated images while preserving text-irrelevant contents. The key to our method is the text-adaptive discriminator that creates word-level local discriminators according to input text to classify fine-grained attributes independently. With this discriminator, the generator learns to generate images where only regions that correspond to the given text are modified. Experimental results show that our method outperforms existing methods on CUB and Oxford-102 datasets, and our results were mostly preferred on a user study. Extensive analysis shows that our method is able to effectively disentangle visual attributes and produce pleasing outputs.