 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Refining Video Sampling
Jan 26, 2026Modern video generators still struggle with complex physical dynamics, often falling short of physical realism. Existing approaches address this using external verifiers or additional training on augmented data, which is computationally expensive and still limited in capturing fine-grained motion. In this work, we present self-refining video sampling, a simple method that uses a pre-trained video generator trained on large-scale datasets as its own self-refiner. By interpreting the generator as a denoising autoencoder, we enable iterative inner-loop refinement at inference time without any external verifier or additional training. We further introduce an uncertainty-aware refinement strategy that selectively refines regions based on self-consistency, which prevents artifacts caused by over-refinement. Experiments on state-of-the-art video generators demonstrate significant improvements in motion coherence and physics alignment, achieving over 70\% human preference compared to the default sampler and guidance-based sampler.
Avatar Forcing: Real-Time Interactive Head Avatar Generation for Natural Conversation
Jan 02, 2026Talking head generation creates lifelike avatars from static portraits for virtual communication and content creation. However, current models do not yet convey the feeling of truly interactive communication, often generating one-way responses that lack emotional engagement. We identify two key challenges toward truly interactive avatars: generating motion in real-time under causal constraints and learning expressive, vibrant reactions without additional labeled data. To address these challenges, we propose Avatar Forcing, a new framework for interactive head avatar generation that models real-time user-avatar interactions through diffusion forcing. This design allows the avatar to process real-time multimodal inputs, including the user's audio and motion, with low latency for instant reactions to both verbal and non-verbal cues such as speech, nods, and laughter. Furthermore, we introduce a direct preference optimization method that leverages synthetic losing samples constructed by dropping user conditions, enabling label-free learning of expressive interaction. Experimental results demonstrate that our framework enables real-time interaction with low latency (approximately 500ms), achieving 6.8X speedup compared to the baseline, and produces reactive and expressive avatar motion, which is preferred over 80% against the baseline.
Frame Guidance: Training-Free Guidance for Frame-Level Control in Video Diffusion Models
Jun 08, 2025Advancements in diffusion models have significantly improved video quality, directing attention to fine-grained controllability. However, many existing methods depend on fine-tuning large-scale video models for specific tasks, which becomes increasingly impractical as model sizes continue to grow. In this work, we present Frame Guidance, a training-free guidance for controllable video generation based on frame-level signals, such as keyframes, style reference images, sketches, or depth maps. For practical training-free guidance, we propose a simple latent processing method that dramatically reduces memory usage, and apply a novel latent optimization strategy designed for globally coherent video generation. Frame Guidance enables effective control across diverse tasks, including keyframe guidance, stylization, and looping, without any training, compatible with any video models. Experimental results show that Frame Guidance can produce high-quality controlled videos for a wide range of tasks and input signals.
Enhancing Variational Autoencoders with Smooth Robust Latent Encoding
Apr 24, 2025
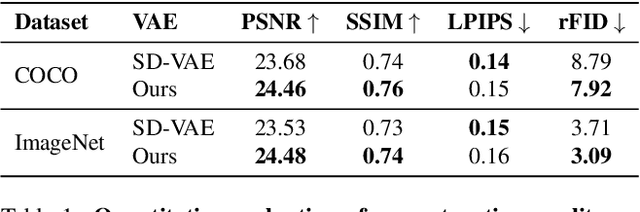
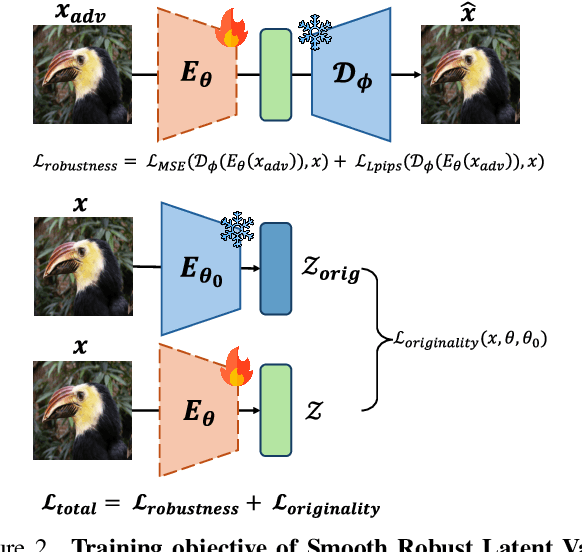
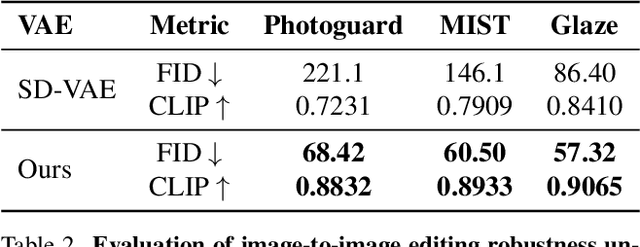
Variational Autoencoders (VAEs) have played a key role in scaling up diffusion-based generative models, as in Stable Diffusion, yet questions regarding their robustness remain largely underexplored. Although adversarial training has been an established technique for enhancing robustness in predictive models, it has been overlooked for generative models due to concerns about potential fidelity degradation by the nature of trade-offs between performance and robustness. In this work, we challenge this presumption, introducing Smooth Robust Latent VAE (SRL-VAE), a novel adversarial training framework that boosts both generation quality and robustness. In contrast to conventional adversarial training, which focuses on robustness only, our approach smooths the latent space via adversarial perturbations, promoting more generalizable representations while regularizing with originality representation to sustain original fidelity. Applied as a post-training step on pre-trained VAEs, SRL-VAE improves image robustness and fidelity with minimal computational overhead. Experiments show that SRL-VAE improves both generation quality, in image reconstruction and text-guided image editing, and robustness, against Nightshade attacks and image editing attacks. These results establish a new paradigm, showing that adversarial training, once thought to be detrimental to generative models, can instead enhance both fidelity and robustness.
Silent Branding Attack: Trigger-free Data Poisoning Attack on Text-to-Image Diffusion Models
Mar 12, 2025



Text-to-image diffusion models have achieved remarkable success in generating high-quality contents from text prompts. However, their reliance on publicly available data and the growing trend of data sharing for fine-tuning make these models particularly vulnerable to data poisoning attacks. In this work, we introduce the Silent Branding Attack, a novel data poisoning method that manipulates text-to-image diffusion models to generate images containing specific brand logos or symbols without any text triggers. We find that when certain visual patterns are repeatedly in the training data, the model learns to reproduce them naturally in its outputs, even without prompt mentions. Leveraging this, we develop an automated data poisoning algorithm that unobtrusively injects logos into original images, ensuring they blend naturally and remain undetected. Models trained on this poisoned dataset generate images containing logos without degrading image quality or text alignment. We experimentally validate our silent branding attack across two realistic settings on large-scale high-quality image datasets and style personalization datasets, achieving high success rates even without a specific text trigger. Human evaluation and quantitative metrics including logo detection show that our method can stealthily embed logos.
Identity Decoupling for Multi-Subject Personalization of Text-to-Image Models
Apr 05, 2024Text-to-image diffusion models have shown remarkable success in generating a personalized subject based on a few reference images. However, current methods struggle with handling multiple subjects simultaneously, often resulting in mixed identities with combined attributes from different subjects. In this work, we present MuDI, a novel framework that enables multi-subject personalization by effectively decoupling identities from multiple subjects. Our main idea is to utilize segmented subjects generated by the Segment Anything Model for both training and inference, as a form of data augmentation for training and initialization for the generation process. Our experiments demonstrate that MuDI can produce high-quality personalized images without identity mixing, even for highly similar subjects as shown in Figure 1. In human evaluation, MuDI shows twice as many successes for personalizing multiple subjects without identity mixing over existing baselines and is preferred over 70% compared to the strongest baseline. More results are available at https://mudi-t2i.github.io/.
Text-Conditioned Sampling Framework for Text-to-Image Generation with Masked Generative Models
Apr 04, 2023Token-based masked generative models are gaining popularity for their fast inference time with parallel decoding. While recent token-based approaches achieve competitive performance to diffusion-based models, their generation performance is still suboptimal as they sample multiple tokens simultaneously without considering the dependence among them. We empirically investigate this problem and propose a learnable sampling model, Text-Conditioned Token Selection (TCTS), to select optimal tokens via localized supervision with text information. TCTS improves not only the image quality but also the semantic alignment of the generated images with the given texts. To further improve the image quality, we introduce a cohesive sampling strategy, Frequency Adaptive Sampling (FAS), to each group of tokens divided according to the self-attention maps. We validate the efficacy of TCTS combined with FAS with various generative tasks, demonstrating that it significantly outperforms the baselines in image-text alignment and image quality. Our text-conditioned sampling framework further reduces the original inference time by more than 50% without modifying the original generative model.