 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData-driven development of cycle prediction models for lithium metal batteries using multi modal mining
Nov 26, 2024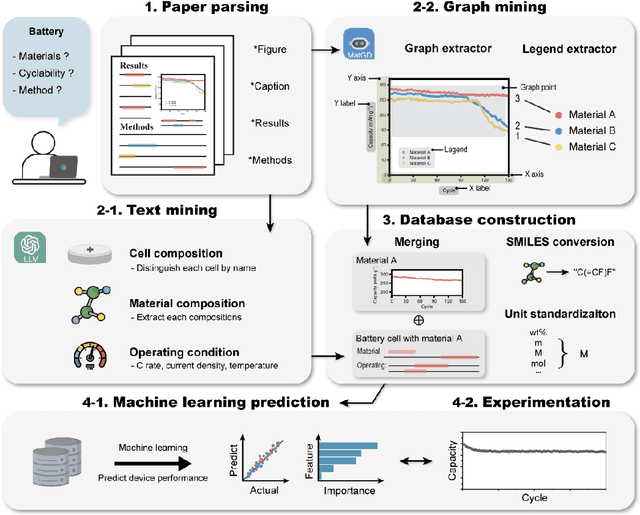
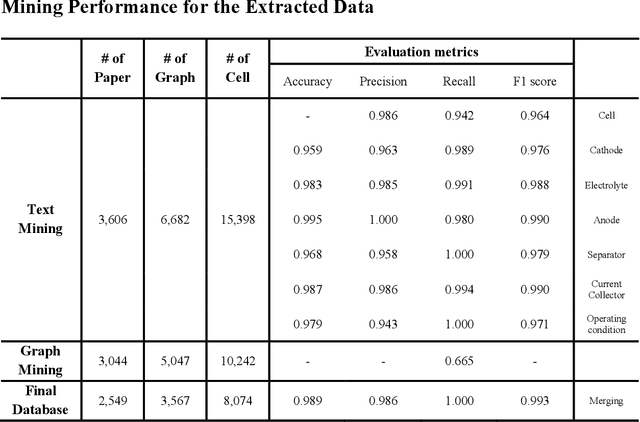
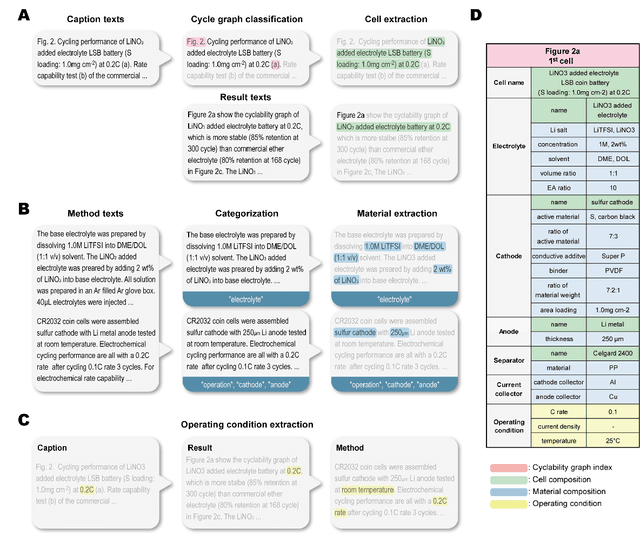
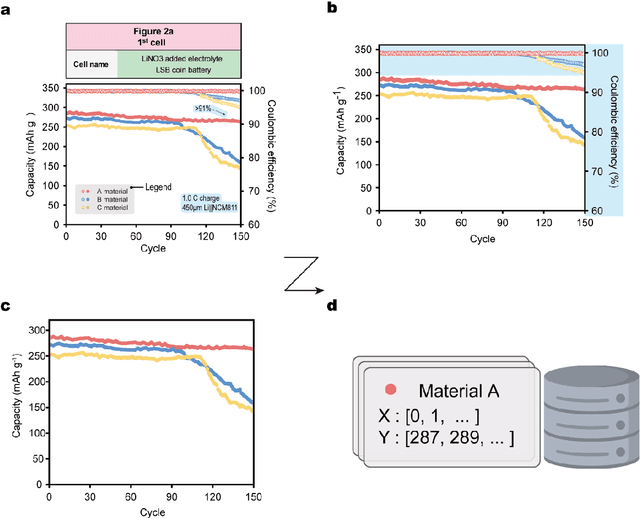
Recent advances in data-driven research have shown great potential in understanding the intricate relationships between materials and their performances. Herein, we introduce a novel multi modal data-driven approach employing an Automatic Battery data Collector (ABC) that integrates a large language model (LLM) with an automatic graph mining tool, Material Graph Digitizer (MatGD). This platform enables state-of-the-art accurate extraction of battery material data and cyclability performance metrics from diverse textual and graphical data sources. From the database derived through the ABC platform, we developed machine learning models that can accurately predict the capacity and stability of lithium metal batteries, which is the first-ever model developed to achieve such predictions. Our models were also experimentally validated, confirming practical applicability and reliability of our data-driven approach.
Text-Conditioned Sampling Framework for Text-to-Image Generation with Masked Generative Models
Apr 04, 2023Token-based masked generative models are gaining popularity for their fast inference time with parallel decoding. While recent token-based approaches achieve competitive performance to diffusion-based models, their generation performance is still suboptimal as they sample multiple tokens simultaneously without considering the dependence among them. We empirically investigate this problem and propose a learnable sampling model, Text-Conditioned Token Selection (TCTS), to select optimal tokens via localized supervision with text information. TCTS improves not only the image quality but also the semantic alignment of the generated images with the given texts. To further improve the image quality, we introduce a cohesive sampling strategy, Frequency Adaptive Sampling (FAS), to each group of tokens divided according to the self-attention maps. We validate the efficacy of TCTS combined with FAS with various generative tasks, demonstrating that it significantly outperforms the baselines in image-text alignment and image quality. Our text-conditioned sampling framework further reduces the original inference time by more than 50% without modifying the original generative model.