 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTextGuider: Training-Free Guidance for Text Rendering via Attention Alignment
Dec 13, 2025
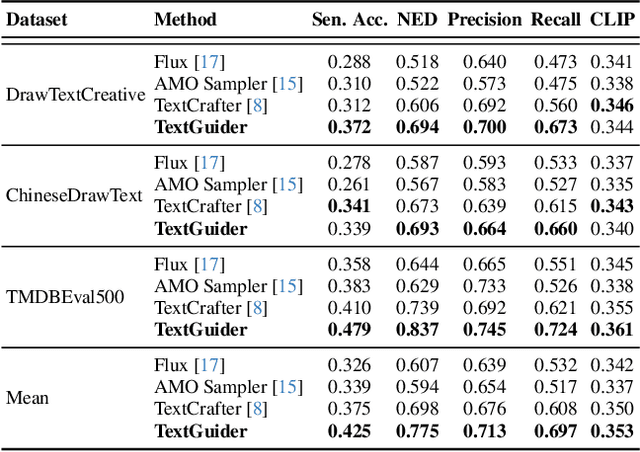
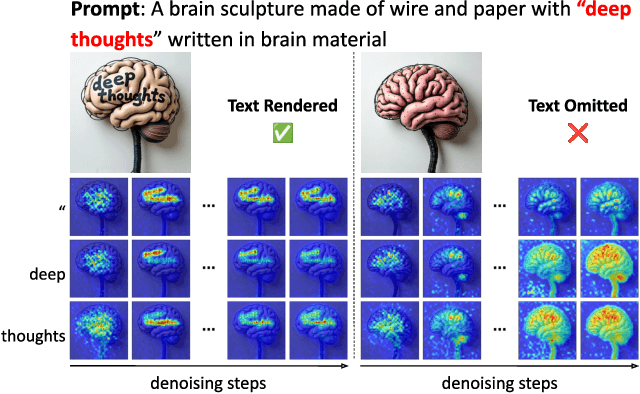
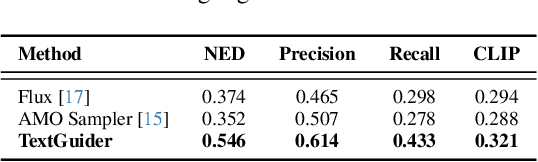
Despite recent advances, diffusion-based text-to-image models still struggle with accurate text rendering. Several studies have proposed fine-tuning or training-free refinement methods for accurate text rendering. However, the critical issue of text omission, where the desired text is partially or entirely missing, remains largely overlooked. In this work, we propose TextGuider, a novel training-free method that encourages accurate and complete text appearance by aligning textual content tokens and text regions in the image. Specifically, we analyze attention patterns in Multi-Modal Diffusion Transformer(MM-DiT) models, particularly for text-related tokens intended to be rendered in the image. Leveraging this observation, we apply latent guidance during the early stage of denoising steps based on two loss functions that we introduce. Our method achieves state-of-the-art performance in test-time text rendering, with significant gains in recall and strong results in OCR accuracy and CLIP score.
Guiding What Not to Generate: Automated Negative Prompting for Text-Image Alignment
Dec 11, 2025Despite substantial progress in text-to-image generation, achieving precise text-image alignment remains challenging, particularly for prompts with rich compositional structure or imaginative elements. To address this, we introduce Negative Prompting for Image Correction (NPC), an automated pipeline that improves alignment by identifying and applying negative prompts that suppress unintended content. We begin by analyzing cross-attention patterns to explain why both targeted negatives-those directly tied to the prompt's alignment error-and untargeted negatives-tokens unrelated to the prompt but present in the generated image-can enhance alignment. To discover useful negatives, NPC generates candidate prompts using a verifier-captioner-proposer framework and ranks them with a salient text-space score, enabling effective selection without requiring additional image synthesis. On GenEval++ and Imagine-Bench, NPC outperforms strong baselines, achieving 0.571 vs. 0.371 on GenEval++ and the best overall performance on Imagine-Bench. By guiding what not to generate, NPC provides a principled, fully automated route to stronger text-image alignment in diffusion models. Code is released at https://github.com/wiarae/NPC.
LG-ANNA-Embedding technical report
Jun 09, 2025This report presents a unified instruction-based framework for learning generalized text embeddings optimized for both information retrieval (IR) and non-IR tasks. Built upon a decoder-only large language model (Mistral-7B), our approach combines in-context learning, soft supervision, and adaptive hard-negative mining to generate context-aware embeddings without task-specific fine-tuning. Structured instructions and few-shot examples are used to guide the model across diverse tasks, enabling strong performance on classification, semantic similarity, clustering, and reranking benchmarks. To improve semantic discrimination, we employ a soft labeling framework where continuous relevance scores, distilled from a high-performance dense retriever and reranker, serve as fine-grained supervision signals. In addition, we introduce adaptive margin-based hard-negative mining, which filters out semantically ambiguous negatives based on their similarity to positive examples, thereby enhancing training stability and retrieval robustness. Our model is evaluated on the newly introduced MTEB (English, v2) benchmark, covering 41 tasks across seven categories. Results show that our method achieves strong generalization and ranks among the top-performing models by Borda score, outperforming several larger or fully fine-tuned baselines. These findings highlight the effectiveness of combining in-context prompting, soft supervision, and adaptive sampling for scalable, high-quality embedding generation.
DefectFill: Realistic Defect Generation with Inpainting Diffusion Model for Visual Inspection
Mar 18, 2025Developing effective visual inspection models remains challenging due to the scarcity of defect data. While image generation models have been used to synthesize defect images, producing highly realistic defects remains difficult. We propose DefectFill, a novel method for realistic defect generation that requires only a few reference defect images. It leverages a fine-tuned inpainting diffusion model, optimized with our custom loss functions incorporating defect, object, and attention terms. It enables precise capture of detailed, localized defect features and their seamless integration into defect-free objects. Additionally, our Low-Fidelity Selection method further enhances the defect sample quality. Experiments show that DefectFill generates high-quality defect images, enabling visual inspection models to achieve state-of-the-art performance on the MVTec AD dataset.
Improving Geometry in Sparse-View 3DGS via Reprojection-based DoF Separation
Dec 19, 2024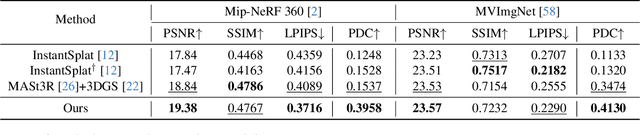

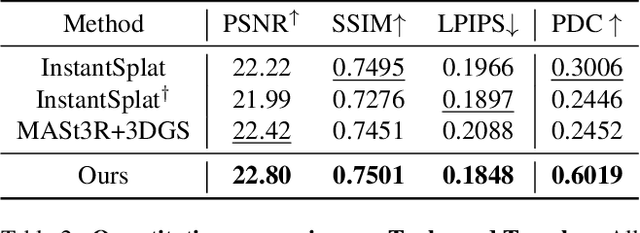
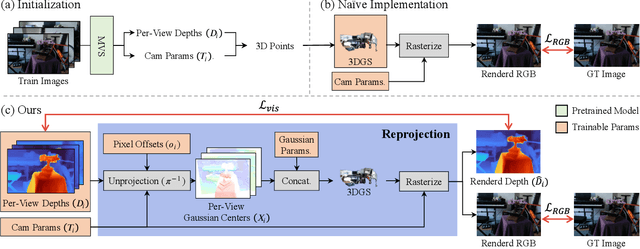
Recent learning-based Multi-View Stereo models have demonstrated state-of-the-art performance in sparse-view 3D reconstruction. However, directly applying 3D Gaussian Splatting (3DGS) as a refinement step following these models presents challenges. We hypothesize that the excessive positional degrees of freedom (DoFs) in Gaussians induce geometry distortion, fitting color patterns at the cost of structural fidelity. To address this, we propose reprojection-based DoF separation, a method distinguishing positional DoFs in terms of uncertainty: image-plane-parallel DoFs and ray-aligned DoF. To independently manage each DoF, we introduce a reprojection process along with tailored constraints for each DoF. Through experiments across various datasets, we confirm that separating the positional DoFs of Gaussians and applying targeted constraints effectively suppresses geometric artifacts, producing reconstruction results that are both visually and geometrically plausible.
Large-Scale Text-to-Image Model with Inpainting is a Zero-Shot Subject-Driven Image Generator
Nov 23, 2024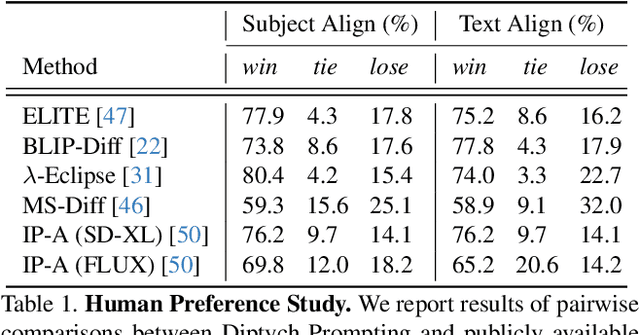

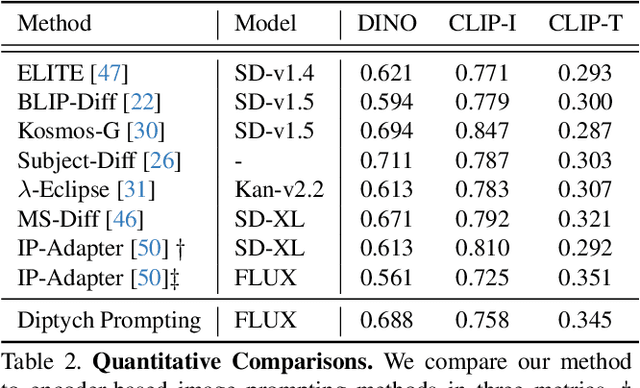
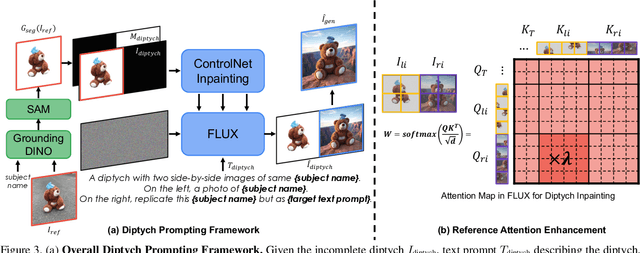
Subject-driven text-to-image generation aims to produce images of a new subject within a desired context by accurately capturing both the visual characteristics of the subject and the semantic content of a text prompt. Traditional methods rely on time- and resource-intensive fine-tuning for subject alignment, while recent zero-shot approaches leverage on-the-fly image prompting, often sacrificing subject alignment. In this paper, we introduce Diptych Prompting, a novel zero-shot approach that reinterprets as an inpainting task with precise subject alignment by leveraging the emergent property of diptych generation in large-scale text-to-image models. Diptych Prompting arranges an incomplete diptych with the reference image in the left panel, and performs text-conditioned inpainting on the right panel. We further prevent unwanted content leakage by removing the background in the reference image and improve fine-grained details in the generated subject by enhancing attention weights between the panels during inpainting. Experimental results confirm that our approach significantly outperforms zero-shot image prompting methods, resulting in images that are visually preferred by users. Additionally, our method supports not only subject-driven generation but also stylized image generation and subject-driven image editing, demonstrating versatility across diverse image generation applications. Project page: https://diptychprompting.github.io/
Style-Friendly SNR Sampler for Style-Driven Generation
Nov 22, 2024



Recent large-scale diffusion models generate high-quality images but struggle to learn new, personalized artistic styles, which limits the creation of unique style templates. Fine-tuning with reference images is the most promising approach, but it often blindly utilizes objectives and noise level distributions used for pre-training, leading to suboptimal style alignment. We propose the Style-friendly SNR sampler, which aggressively shifts the signal-to-noise ratio (SNR) distribution toward higher noise levels during fine-tuning to focus on noise levels where stylistic features emerge. This enables models to better capture unique styles and generate images with higher style alignment. Our method allows diffusion models to learn and share new "style templates", enhancing personalized content creation. We demonstrate the ability to generate styles such as personal watercolor paintings, minimal flat cartoons, 3D renderings, multi-panel images, and memes with text, thereby broadening the scope of style-driven generation.
NanoVoice: Efficient Speaker-Adaptive Text-to-Speech for Multiple Speakers
Sep 24, 2024



We present NanoVoice, a personalized text-to-speech model that efficiently constructs voice adapters for multiple speakers simultaneously. NanoVoice introduces a batch-wise speaker adaptation technique capable of fine-tuning multiple references in parallel, significantly reducing training time. Beyond building separate adapters for each speaker, we also propose a parameter sharing technique that reduces the number of parameters used for speaker adaptation. By incorporating a novel trainable scale matrix, NanoVoice mitigates potential performance degradation during parameter sharing. NanoVoice achieves performance comparable to the baselines, while training 4 times faster and using 45 percent fewer parameters for speaker adaptation with 40 reference voices. Extensive ablation studies and analysis further validate the efficiency of our model.
VoiceGuider: Enhancing Out-of-Domain Performance in Parameter-Efficient Speaker-Adaptive Text-to-Speech via Autoguidance
Sep 24, 2024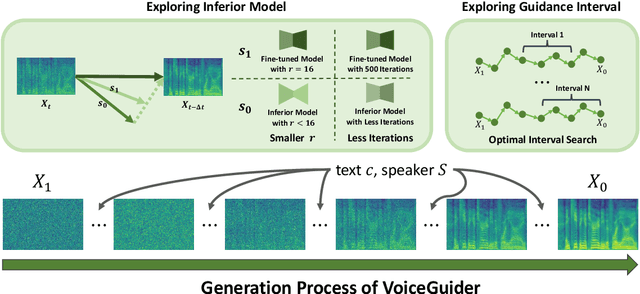
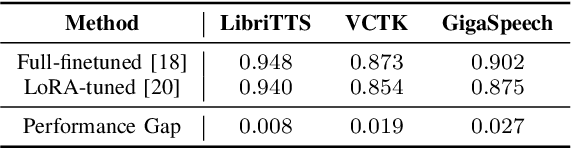
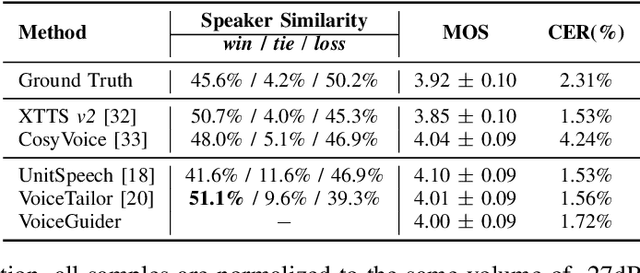
When applying parameter-efficient finetuning via LoRA onto speaker adaptive text-to-speech models, adaptation performance may decline compared to full-finetuned counterparts, especially for out-of-domain speakers. Here, we propose VoiceGuider, a parameter-efficient speaker adaptive text-to-speech system reinforced with autoguidance to enhance the speaker adaptation performance, reducing the gap against full-finetuned models. We carefully explore various ways of strengthening autoguidance, ultimately finding the optimal strategy. VoiceGuider as a result shows robust adaptation performance especially on extreme out-of-domain speech data. We provide audible samples in our demo page.
Disentangled Motion Modeling for Video Frame Interpolation
Jun 25, 2024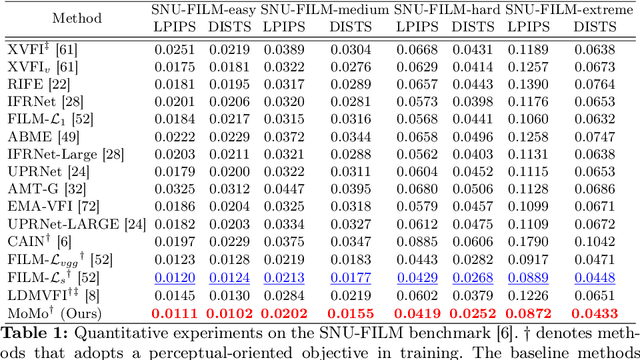
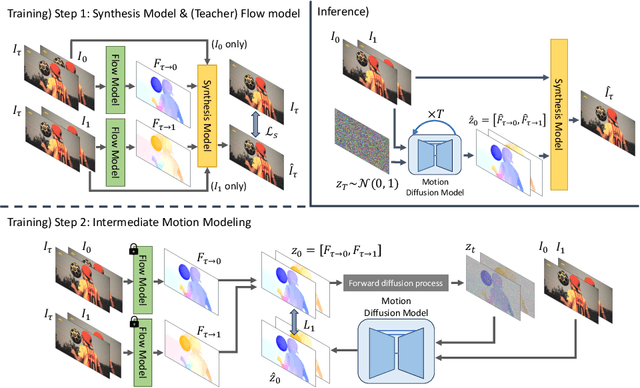

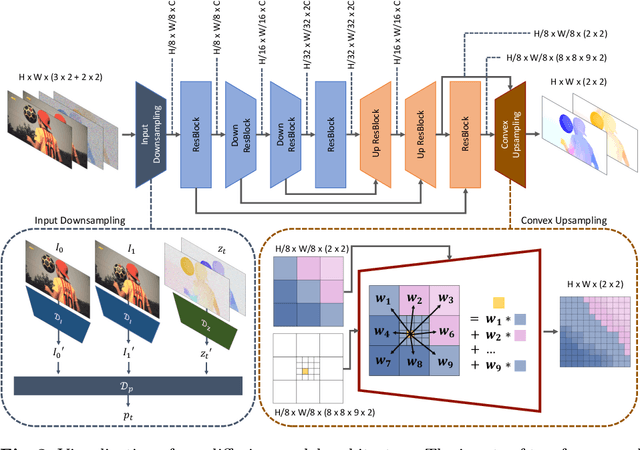
Video frame interpolation (VFI) aims to synthesize intermediate frames in between existing frames to enhance visual smoothness and quality. Beyond the conventional methods based on the reconstruction loss, recent works employ the high quality generative models for perceptual quality. However, they require complex training and large computational cost for modeling on the pixel space. In this paper, we introduce disentangled Motion Modeling (MoMo), a diffusion-based approach for VFI that enhances visual quality by focusing on intermediate motion modeling. We propose disentangled two-stage training process, initially training a frame synthesis model to generate frames from input pairs and their optical flows. Subsequently, we propose a motion diffusion model, equipped with our novel diffusion U-Net architecture designed for optical flow, to produce bi-directional flows between frames. This method, by leveraging the simpler low-frequency representation of motions, achieves superior perceptual quality with reduced computational demands compared to generative modeling methods on the pixel space. Our method surpasses state-of-the-art methods in perceptual metrics across various benchmarks, demonstrating its efficacy and efficiency in VFI. Our code is available at: https://github.com/JHLew/MoMo