 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDoes Your Voice Assistant Remember? Analyzing Conversational Context Recall and Utilization in Voice Interaction Models
Feb 27, 2025Recent advancements in multi-turn voice interaction models have improved user-model communication. However, while closed-source models effectively retain and recall past utterances, whether open-source models share this ability remains unexplored. To fill this gap, we systematically evaluate how well open-source interaction models utilize past utterances using ContextDialog, a benchmark we proposed for this purpose. Our findings show that speech-based models have more difficulty than text-based ones, especially when recalling information conveyed in speech, and even with retrieval-augmented generation, models still struggle with questions about past utterances. These insights highlight key limitations in open-source models and suggest ways to improve memory retention and retrieval robustness.
EdiText: Controllable Coarse-to-Fine Text Editing with Diffusion Language Models
Feb 27, 2025We propose EdiText, a controllable text editing method that modify the reference text to desired attributes at various scales. We integrate an SDEdit-based editing technique that allows for broad adjustments in the degree of text editing. Additionally, we introduce a novel fine-level editing method based on self-conditioning, which allows subtle control of reference text. While being capable of editing on its own, this fine-grained method, integrated with the SDEdit approach, enables EdiText to make precise adjustments within the desired range. EdiText demonstrates its controllability to robustly adjust reference text at broad range of levels across various tasks, including toxicity control and sentiment control.
NanoVoice: Efficient Speaker-Adaptive Text-to-Speech for Multiple Speakers
Sep 24, 2024



We present NanoVoice, a personalized text-to-speech model that efficiently constructs voice adapters for multiple speakers simultaneously. NanoVoice introduces a batch-wise speaker adaptation technique capable of fine-tuning multiple references in parallel, significantly reducing training time. Beyond building separate adapters for each speaker, we also propose a parameter sharing technique that reduces the number of parameters used for speaker adaptation. By incorporating a novel trainable scale matrix, NanoVoice mitigates potential performance degradation during parameter sharing. NanoVoice achieves performance comparable to the baselines, while training 4 times faster and using 45 percent fewer parameters for speaker adaptation with 40 reference voices. Extensive ablation studies and analysis further validate the efficiency of our model.
VoiceGuider: Enhancing Out-of-Domain Performance in Parameter-Efficient Speaker-Adaptive Text-to-Speech via Autoguidance
Sep 24, 2024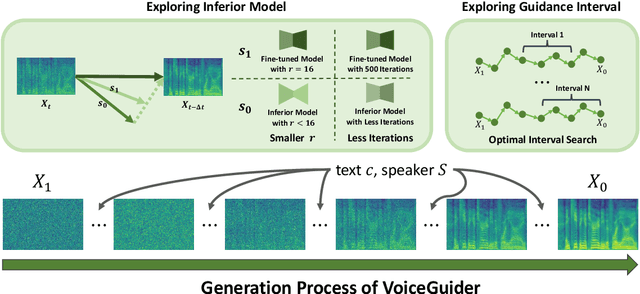
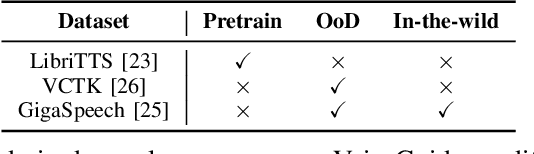
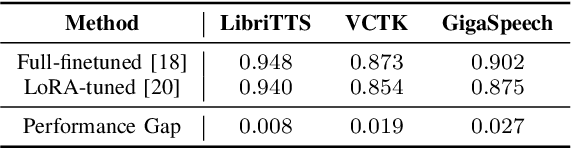
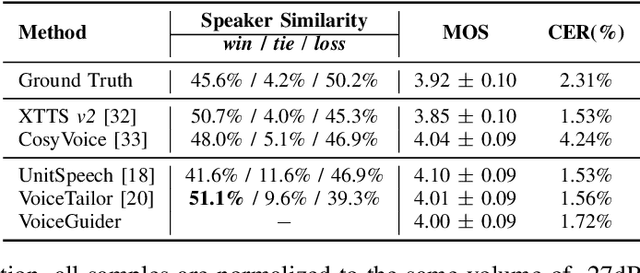
When applying parameter-efficient finetuning via LoRA onto speaker adaptive text-to-speech models, adaptation performance may decline compared to full-finetuned counterparts, especially for out-of-domain speakers. Here, we propose VoiceGuider, a parameter-efficient speaker adaptive text-to-speech system reinforced with autoguidance to enhance the speaker adaptation performance, reducing the gap against full-finetuned models. We carefully explore various ways of strengthening autoguidance, ultimately finding the optimal strategy. VoiceGuider as a result shows robust adaptation performance especially on extreme out-of-domain speech data. We provide audible samples in our demo page.
VoiceTailor: Lightweight Plug-In Adapter for Diffusion-Based Personalized Text-to-Speech
Aug 27, 2024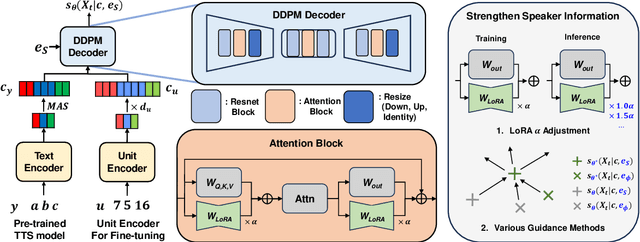
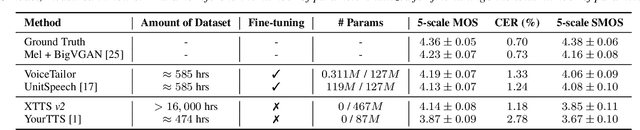
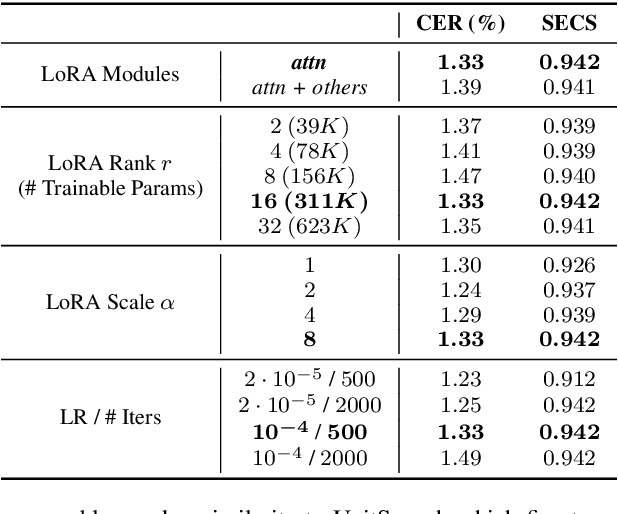
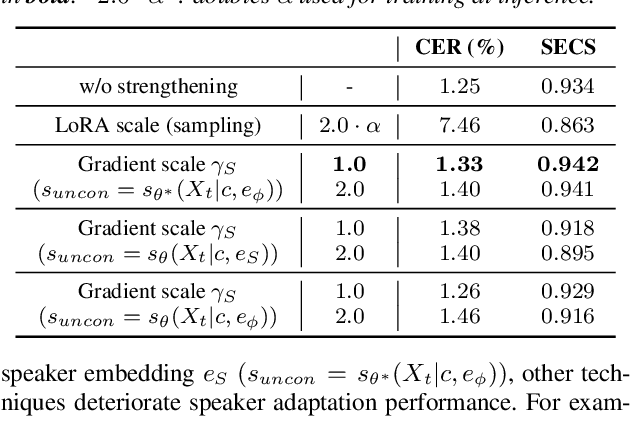
We propose VoiceTailor, a parameter-efficient speaker-adaptive text-to-speech (TTS) system, by equipping a pre-trained diffusion-based TTS model with a personalized adapter. VoiceTailor identifies pivotal modules that benefit from the adapter based on a weight change ratio analysis. We utilize Low-Rank Adaptation (LoRA) as a parameter-efficient adaptation method and incorporate the adapter into pivotal modules of the pre-trained diffusion decoder. To achieve powerful adaptation performance with few parameters, we explore various guidance techniques for speaker adaptation and investigate the best strategies to strengthen speaker information. VoiceTailor demonstrates comparable speaker adaptation performance to existing adaptive TTS models by fine-tuning only 0.25\% of the total parameters. VoiceTailor shows strong robustness when adapting to a wide range of real-world speakers, as shown in the demo.
Edit-A-Video: Single Video Editing with Object-Aware Consistency
Apr 01, 2023
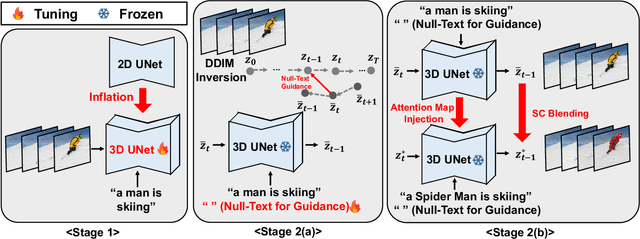
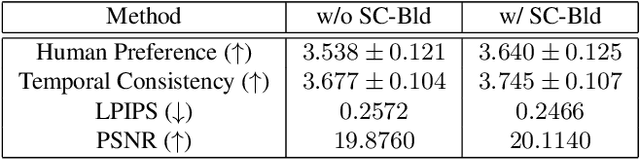

Despite the fact that text-to-video (TTV) model has recently achieved remarkable success, there have been few approaches on TTV for its extension to video editing. Motivated by approaches on TTV models adapting from diffusion-based text-to-image (TTI) models, we suggest the video editing framework given only a pretrained TTI model and a single <text, video> pair, which we term Edit-A-Video. The framework consists of two stages: (1) inflating the 2D model into the 3D model by appending temporal modules and tuning on the source video (2) inverting the source video into the noise and editing with target text prompt and attention map injection. Each stage enables the temporal modeling and preservation of semantic attributes of the source video. One of the key challenges for video editing include a background inconsistency problem, where the regions not included for the edit suffer from undesirable and inconsistent temporal alterations. To mitigate this issue, we also introduce a novel mask blending method, termed as sparse-causal blending (SC Blending). We improve previous mask blending methods to reflect the temporal consistency so that the area where the editing is applied exhibits smooth transition while also achieving spatio-temporal consistency of the unedited regions. We present extensive experimental results over various types of text and videos, and demonstrate the superiority of the proposed method compared to baselines in terms of background consistency, text alignment, and video editing quality.