 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContextualized Visual Personalization in Vision-Language Models
Feb 03, 2026Despite recent progress in vision-language models (VLMs), existing approaches often fail to generate personalized responses based on the user's specific experiences, as they lack the ability to associate visual inputs with a user's accumulated visual-textual context. We newly formalize this challenge as contextualized visual personalization, which requires the visual recognition and textual retrieval of personalized visual experiences by VLMs when interpreting new images. To address this issue, we propose CoViP, a unified framework that treats personalized image captioning as a core task for contextualized visual personalization and improves this capability through reinforcement-learning-based post-training and caption-augmented generation. We further introduce diagnostic evaluations that explicitly rule out textual shortcut solutions and verify whether VLMs truly leverage visual context. Extensive experiments demonstrate that existing open-source and proprietary VLMs exhibit substantial limitations, while CoViP not only improves personalized image captioning but also yields holistic gains across downstream personalization tasks. These results highlight CoViP as a crucial stage for enabling robust and generalizable contextualized visual personalization.
A Multifaceted Analysis of Negative Bias in Large Language Models through the Lens of Parametric Knowledge
Nov 14, 2025
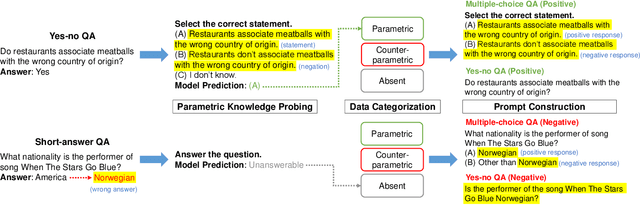


Negative bias refers to the tendency of large language models (LLMs) to excessively generate negative responses in binary decision tasks (e.g., yes-no question answering). Previous research has focused on detecting and addressing negative attention heads that induce negative bias. However, the underlying detailed factors influencing negative bias remain underexplored. In this paper, we demonstrate that LLMs exhibit format-level negative bias, meaning the prompt format more influences their responses than the semantics of the negative response. For the fine-grained study of the negative bias, we introduce a pipeline for constructing the evaluation set, which systematically categorizes the dataset into three subsets based on the model's parametric knowledge: correct, incorrect, and insufficient relevant knowledge. Through analysis of this evaluation set, we identify a shortcut behavior in which models tend to generate negative responses when they lack sufficient knowledge to answer a yes-no question, leading to negative bias. We further examine how negative bias changes under various prompting scenarios related to parametric knowledge. We observe that providing relevant context and offering an "I don't know" option generally reduces negative bias, whereas chain-of-thought prompting tends to amplify the bias. Finally, we demonstrate that the degree of negative bias can vary depending on the type of prompt, which influences the direction of the response. Our work reveals the various factors that influence negative bias, providing critical insights for mitigating it in LLMs.
Does Your Voice Assistant Remember? Analyzing Conversational Context Recall and Utilization in Voice Interaction Models
Feb 27, 2025Recent advancements in multi-turn voice interaction models have improved user-model communication. However, while closed-source models effectively retain and recall past utterances, whether open-source models share this ability remains unexplored. To fill this gap, we systematically evaluate how well open-source interaction models utilize past utterances using ContextDialog, a benchmark we proposed for this purpose. Our findings show that speech-based models have more difficulty than text-based ones, especially when recalling information conveyed in speech, and even with retrieval-augmented generation, models still struggle with questions about past utterances. These insights highlight key limitations in open-source models and suggest ways to improve memory retention and retrieval robustness.
Know "No" Better: A Data-Driven Approach for Enhancing Negation Awareness in CLIP
Jan 19, 2025While CLIP has significantly advanced multimodal understanding by bridging vision and language, the inability to grasp negation - such as failing to differentiate concepts like "parking" from "no parking" - poses substantial challenges. By analyzing the data used in the public CLIP model's pre-training, we posit this limitation stems from a lack of negation-inclusive data. To address this, we introduce data generation pipelines that employ a large language model (LLM) and a multimodal LLM to produce negation-inclusive captions. Fine-tuning CLIP with data generated from our pipelines, we develop NegationCLIP, which enhances negation awareness while preserving the generality. Moreover, to enable a comprehensive evaluation of negation understanding, we propose NegRefCOCOg-a benchmark tailored to test VLMs' ability to interpret negation across diverse expressions and positions within a sentence. Experiments on various CLIP architectures validate the effectiveness of our data generation pipelines in enhancing CLIP's ability to perceive negation accurately. Additionally, NegationCLIP's enhanced negation awareness has practical applications across various multimodal tasks, demonstrated by performance gains in text-to-image generation and referring image segmentation.
Unleashing Multi-Hop Reasoning Potential in Large Language Models through Repetition of Misordered Context
Oct 09, 2024



Multi-hop reasoning, which requires multi-step reasoning based on the supporting documents within a given context, remains challenging for large language models (LLMs). LLMs often struggle to filter out irrelevant documents within the context, and their performance is sensitive to the position of supporting documents within that context. In this paper, we identify an additional challenge: LLMs' performance is also sensitive to the order in which the supporting documents are presented. We refer to this as the misordered context problem. To address this issue, we propose a simple yet effective method called context repetition (CoRe), which involves prompting the model by repeatedly presenting the context to ensure the supporting documents are presented in the optimal order for the model. Using CoRe, we improve the F1 score by up to 30%p on multi-hop QA tasks and increase accuracy by up to 70%p on a synthetic task. Additionally, CoRe helps mitigate the well-known "lost-in-the-middle" problem in LLMs and can be effectively combined with retrieval-based approaches utilizing Chain-of-Thought (CoT) reasoning.
Correcting Negative Bias in Large Language Models through Negative Attention Score Alignment
Jul 31, 2024



A binary decision task, like yes-no questions or answer verification, reflects a significant real-world scenario such as where users look for confirmation about the correctness of their decisions on specific issues. In this work, we observe that language models exhibit a negative bias in the binary decisions of complex reasoning tasks. Based on our observations and the rationale about attention-based model dynamics, we propose a negative attention score (NAS) to systematically and quantitatively formulate negative bias. Based on NAS, we identify attention heads that attend to negative tokens provided in the instructions as answer candidate of binary decisions, regardless of the question in the prompt, and validate their association with the negative bias. Additionally, we propose the negative attention score alignment (NASA) method, which is a parameter-efficient fine-tuning technique to address the extracted negatively biased attention heads. Experimental results from various domains of reasoning tasks and large model search space demonstrate that NASA significantly reduces the gap between precision and recall caused by negative bias while preserving their generalization abilities. Our codes are available at \url{https://github.com/ysw1021/NASA}.
Large Language Models are Skeptics: False Negative Problem of Input-conflicting Hallucination
Jun 20, 2024In this paper, we identify a new category of bias that induces input-conflicting hallucinations, where large language models (LLMs) generate responses inconsistent with the content of the input context. This issue we have termed the false negative problem refers to the phenomenon where LLMs are predisposed to return negative judgments when assessing the correctness of a statement given the context. In experiments involving pairs of statements that contain the same information but have contradictory factual directions, we observe that LLMs exhibit a bias toward false negatives. Specifically, the model presents greater overconfidence when responding with False. Furthermore, we analyze the relationship between the false negative problem and context and query rewriting and observe that both effectively tackle false negatives in LLMs.
Interactive Text-to-Image Retrieval with Large Language Models: A Plug-and-Play Approach
Jun 05, 2024
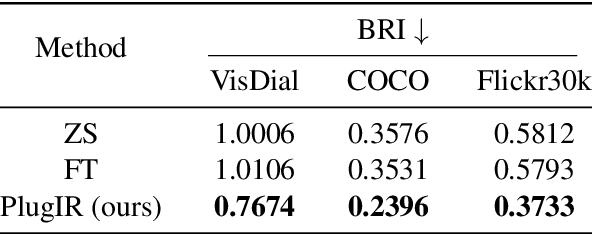
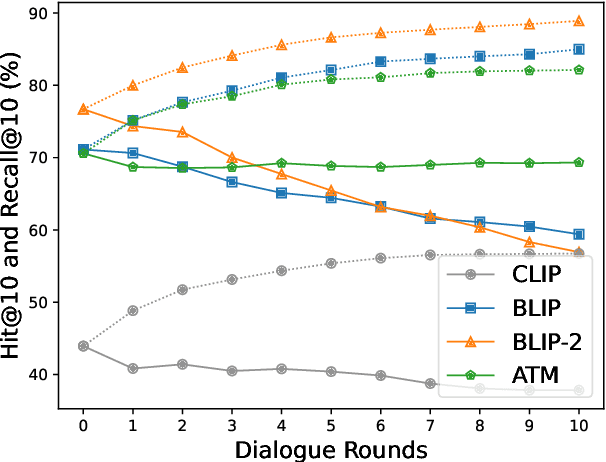

In this paper, we primarily address the issue of dialogue-form context query within the interactive text-to-image retrieval task. Our methodology, PlugIR, actively utilizes the general instruction-following capability of LLMs in two ways. First, by reformulating the dialogue-form context, we eliminate the necessity of fine-tuning a retrieval model on existing visual dialogue data, thereby enabling the use of any arbitrary black-box model. Second, we construct the LLM questioner to generate non-redundant questions about the attributes of the target image, based on the information of retrieval candidate images in the current context. This approach mitigates the issues of noisiness and redundancy in the generated questions. Beyond our methodology, we propose a novel evaluation metric, Best log Rank Integral (BRI), for a comprehensive assessment of the interactive retrieval system. PlugIR demonstrates superior performance compared to both zero-shot and fine-tuned baselines in various benchmarks. Additionally, the two methodologies comprising PlugIR can be flexibly applied together or separately in various situations. Our codes are available at https://github.com/Saehyung-Lee/PlugIR.
Controlled Text Generation for Black-box Language Models via Score-based Progressive Editor
Nov 13, 2023Despite recent progress in language models, generating constrained text for specific domains remains a challenge, particularly when utilizing black-box models that lack domain-specific knowledge. In this paper, we introduce ScoPE (Score-based Progressive Editor) generation, a novel approach for controlled text generation for black-box language models. We employ ScoPE to facilitate text generation in the target domain by integrating it with language models through a cascading approach. Trained to enhance the target domain score of the edited text, ScoPE progressively edits intermediate output discrete tokens to align with the target attributes throughout the auto-regressive generation process of the language model. This iterative process guides subsequent steps to produce desired output texts for the target domain. Our experimental results on diverse controlled generations demonstrate that ScoPE effectively facilitates controlled text generation for black-box language models in both in-domain and out-of-domain conditions, which is challenging for existing methods.
Rare Words Degenerate All Words
Sep 07, 2021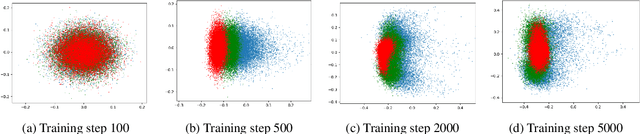

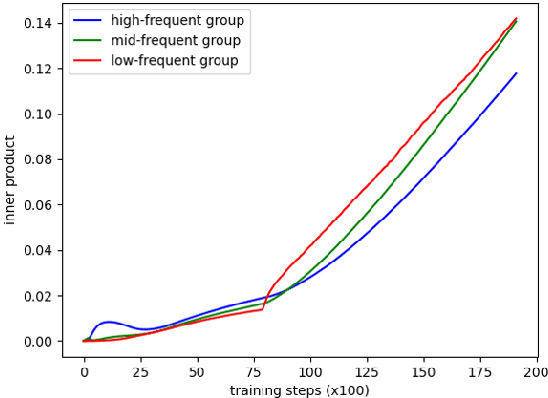
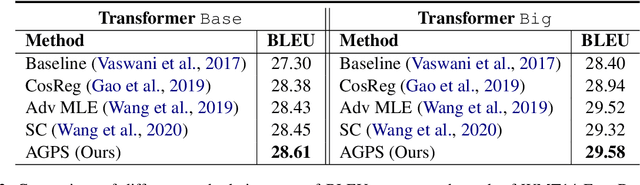
Despite advances in neural network language model, the representation degeneration problem of embeddings is still challenging. Recent studies have found that the learned output embeddings are degenerated into a narrow-cone distribution which makes the similarity between each embeddings positive. They analyzed the cause of the degeneration problem has been demonstrated as common to most embeddings. However, we found that the degeneration problem is especially originated from the training of embeddings of rare words. In this study, we analyze the intrinsic mechanism of the degeneration of rare word embeddings with respect of their gradient about the negative log-likelihood loss function. Furthermore, we theoretically and empirically demonstrate that the degeneration of rare word embeddings causes the degeneration of non-rare word embeddings, and that the overall degeneration problem can be alleviated by preventing the degeneration of rare word embeddings. Based on our analyses, we propose a novel method, Adaptive Gradient Partial Scaling(AGPS), to address the degeneration problem. Experimental results demonstrate the effectiveness of the proposed method qualitatively and quantitatively.