 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding LoRA as Knowledge Memory: An Empirical Analysis
Mar 01, 2026Continuous knowledge updating for pre-trained large language models (LLMs) is increasingly necessary yet remains challenging. Although inference-time methods like In-Context Learning (ICL) and Retrieval-Augmented Generation (RAG) are popular, they face constraints in context budgets, costs, and retrieval fragmentation. Departing from these context-dependent paradigms, this work investigates a parametric approach using Low-Rank Adaptation (LoRA) as a modular knowledge memory. Although few recent works examine this concept, the fundamental mechanics governing its capacity and composability remain largely unexplored. We bridge this gap through the first systematic empirical study mapping the design space of LoRA-based memory, ranging from characterizing storage capacity and optimizing internalization to scaling multi-module systems and evaluating long-context reasoning. Rather than proposing a single architecture, we provide practical guidance on the operational boundaries of LoRA memory. Overall, our findings position LoRA as the complementary axis of memory alongside RAG and ICL, offering distinct advantages.
Knowledge Integration Decay in Search-Augmented Reasoning of Large Language Models
Feb 10, 2026Modern Large Language Models (LLMs) have demonstrated remarkable capabilities in complex tasks by employing search-augmented reasoning to incorporate external knowledge into long chains of thought. However, we identify a critical yet underexplored bottleneck in this paradigm, termed Knowledge Integration Decay (KID). Specifically, we observe that as the length of reasoning generated before search grows, models increasingly fail to integrate retrieved evidence into subsequent reasoning steps, limiting performance even when relevant information is available. To address this, we propose Self-Anchored Knowledge Encoding (SAKE), a training-free inference-time strategy designed to stabilize knowledge utilization. By anchoring retrieved knowledge at both the beginning and end of the reasoning process, SAKE prevents it from being overshadowed by prior context, thereby preserving its semantic integrity. Extensive experiments on multi-hop QA and complex reasoning benchmarks demonstrate that SAKE significantly mitigates KID and improves performance, offering a lightweight yet effective solution for knowledge integration in agentic LLMs.
Text Change Detection in Multilingual Documents Using Image Comparison
Dec 05, 2024Document comparison typically relies on optical character recognition (OCR) as its core technology. However, OCR requires the selection of appropriate language models for each document and the performance of multilingual or hybrid models remains limited. To overcome these challenges, we propose text change detection (TCD) using an image comparison model tailored for multilingual documents. Unlike OCR-based approaches, our method employs word-level text image-to-image comparison to detect changes. Our model generates bidirectional change segmentation maps between the source and target documents. To enhance performance without requiring explicit text alignment or scaling preprocessing, we employ correlations among multi-scale attention features. We also construct a benchmark dataset comprising actual printed and scanned word pairs in various languages to evaluate our model. We validate our approach using our benchmark dataset and public benchmarks Distorted Document Images and the LRDE Document Binarization Dataset. We compare our model against state-of-the-art semantic segmentation and change detection models, as well as to conventional OCR-based models.
Correcting Negative Bias in Large Language Models through Negative Attention Score Alignment
Jul 31, 2024



A binary decision task, like yes-no questions or answer verification, reflects a significant real-world scenario such as where users look for confirmation about the correctness of their decisions on specific issues. In this work, we observe that language models exhibit a negative bias in the binary decisions of complex reasoning tasks. Based on our observations and the rationale about attention-based model dynamics, we propose a negative attention score (NAS) to systematically and quantitatively formulate negative bias. Based on NAS, we identify attention heads that attend to negative tokens provided in the instructions as answer candidate of binary decisions, regardless of the question in the prompt, and validate their association with the negative bias. Additionally, we propose the negative attention score alignment (NASA) method, which is a parameter-efficient fine-tuning technique to address the extracted negatively biased attention heads. Experimental results from various domains of reasoning tasks and large model search space demonstrate that NASA significantly reduces the gap between precision and recall caused by negative bias while preserving their generalization abilities. Our codes are available at \url{https://github.com/ysw1021/NASA}.
Improving Instruction Following in Language Models through Proxy-Based Uncertainty Estimation
May 10, 2024



Assessing response quality to instructions in language models is vital but challenging due to the complexity of human language across different contexts. This complexity often results in ambiguous or inconsistent interpretations, making accurate assessment difficult. To address this issue, we propose a novel Uncertainty-aware Reward Model (URM) that introduces a robust uncertainty estimation for the quality of paired responses based on Bayesian approximation. Trained with preference datasets, our uncertainty-enabled proxy not only scores rewards for responses but also evaluates their inherent uncertainty. Empirical results demonstrate significant benefits of incorporating the proposed proxy into language model training. Our method boosts the instruction following capability of language models by refining data curation for training and improving policy optimization objectives, thereby surpassing existing methods by a large margin on benchmarks such as Vicuna and MT-bench. These findings highlight that our proposed approach substantially advances language model training and paves a new way of harnessing uncertainty within language models.
Multi-Response Heteroscedastic Gaussian Process Models and Their Inference
Aug 30, 2023Despite the widespread utilization of Gaussian process models for versatile nonparametric modeling, they exhibit limitations in effectively capturing abrupt changes in function smoothness and accommodating relationships with heteroscedastic errors. Addressing these shortcomings, the heteroscedastic Gaussian process (HeGP) regression seeks to introduce flexibility by acknowledging the variability of residual variances across covariates in the regression model. In this work, we extend the HeGP concept, expanding its scope beyond regression tasks to encompass classification and state-space models. To achieve this, we propose a novel framework where the Gaussian process is coupled with a covariate-induced precision matrix process, adopting a mixture formulation. This approach enables the modeling of heteroscedastic covariance functions across covariates. To mitigate the computational challenges posed by sampling, we employ variational inference to approximate the posterior and facilitate posterior predictive modeling. Additionally, our training process leverages an EM algorithm featuring closed-form M-step updates to efficiently evaluate the heteroscedastic covariance function. A notable feature of our model is its consistent performance on multivariate responses, accommodating various types (continuous or categorical) seamlessly. Through a combination of simulations and real-world applications in climatology, we illustrate the model's prowess and advantages. By overcoming the limitations of traditional Gaussian process models, our proposed framework offers a robust and versatile tool for a wide array of applications.
Heteroscedastic Gaussian Process Regression on the Alkenone over Sea Surface Temperatures
Dec 18, 2019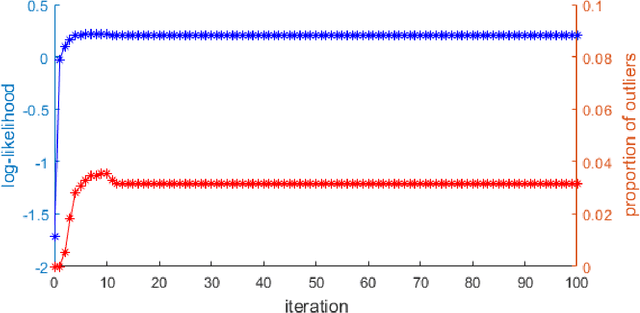
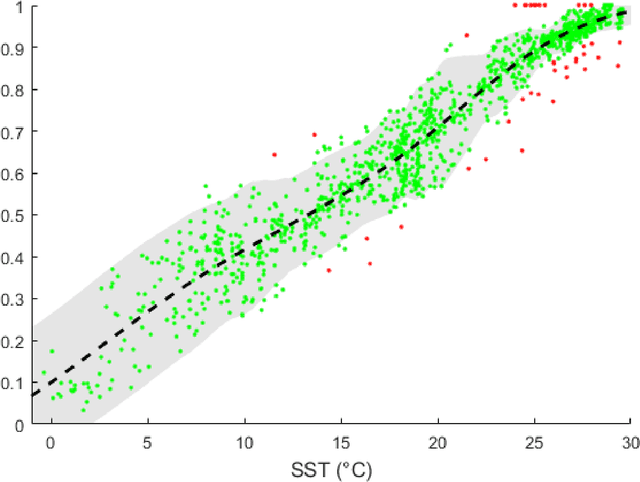

To restore the historical sea surface temperatures (SSTs) better, it is important to construct a good calibration model for the associated proxies. In this paper, we introduce a new model for alkenone (${\rm{U}}_{37}^{\rm{K}'}$) based on the heteroscedastic Gaussian process (GP) regression method. Our nonparametric approach not only deals with the variable pattern of noises over SSTs but also contains a Bayesian method of classifying potential outliers.
Dual Proxy Gaussian Process Stack: Integrating Benthic $δ^{18}{\rm{O}}$ and Radiocarbon Proxies for Inferring Ages on Ocean Sediment Cores
Jul 20, 2019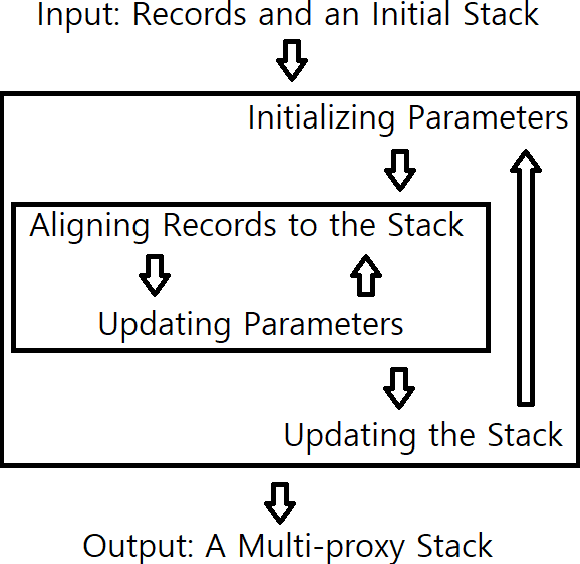
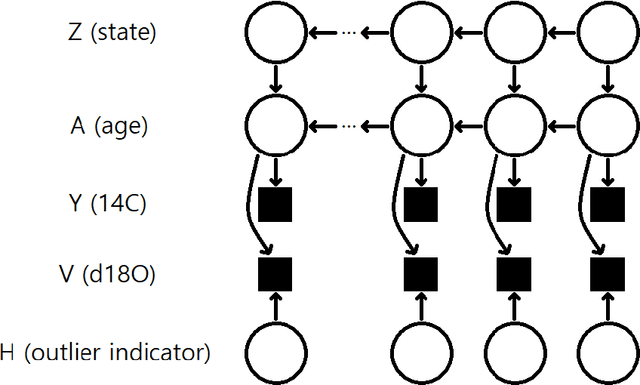

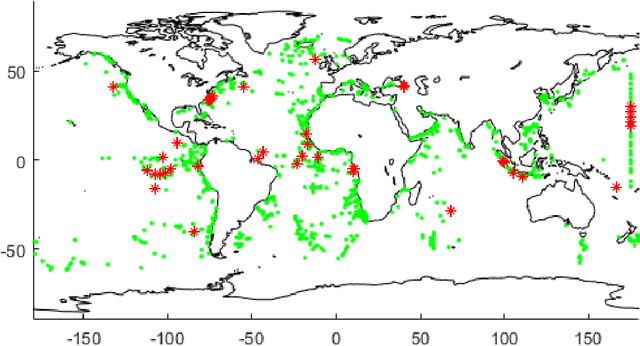
Ages in ocean sediment cores are often inferred using either benthic ${\delta}^{18}{\rm{O}}$ or planktonic ${}^{14}{\rm{C}}$ of foraminiferal calcite. Existing probabilistic dating methods infer ages in two distinct approaches: ages are either inferred directly using radionuclides, e.g. Bacon [Blaauw and Christen (2011)]; or indirectly based on the alignment of records, e.g. HMM-Match [Lin et al. (2014)]. In this paper, we introduce a novel algorithm for integrating these two approaches by constructing Dual Proxy Gaussian Process (DPGP) stacks, which represent a probabilistic model of benthic ${\delta}^{18}{\rm{O}}$ change (and its timing) based on a set of cores. While a previous stack construction algorithm, HMM-Match, uses a discrete age inference model based on Hidden Markov models (HMMs) [Durbin et al. (1998)] and requires a number of records enough to sufficiently cover all its ages, DPGP stacks with time-varying variances are constructed with continuous ages obtained by particle smoothing [Doucet et al. (2001); Klaas et al. (2006)] and Markov-chain Monte Carlo (MCMC) [Peters (2008)] algorithms, and can be derived from a small number of records by applying the Gaussian process regression [Rasmussen and Williams (2005)]. As an example of the stacking method, we construct a local stack from 6 cores in the deep northeastern Atlantic Ocean and compare it to a deterministically constructed ${\delta}^{18}{\rm{O}}$ stack of 58 cores from the deep North Atlantic [Lisiecki and Stern (2016)]. We also provide two examples of how dual proxy alignment ages can be inferred by aligning additional cores to the stack.