 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAxial-Centric Cross-Plane Attention for 3D Medical Image Classification
Feb 25, 2026Clinicians commonly interpret three-dimensional (3D) medical images, such as computed tomography (CT) scans, using multiple anatomical planes rather than as a single volumetric representation. In this multi-planar approach, the axial plane typically serves as the primary acquisition and diagnostic reference, while the coronal and sagittal planes provide complementary spatial information to increase diagnostic confidence. However, many existing 3D deep learning methods either process volumetric data holistically or assign equal importance to all planes, failing to reflect the axial-centric clinical interpretation workflow. To address this gap, we propose an axial-centric cross-plane attention architecture for 3D medical image classification that captures the inherent asymmetric dependencies between different anatomical planes. Our architecture incorporates MedDINOv3, a medical vision foundation model pretrained via self-supervised learning on large-scale axial CT images, as a frozen feature extractor for the axial, coronal, and sagittal planes. RICA blocks and intra-plane transformer encoders capture plane-specific positional and contextual information within each anatomical plane, while axial-centric cross-plane transformer encoders condition axial features on complementary information from auxiliary planes. Experimental results on six datasets from the MedMNIST3D benchmark demonstrate that the proposed architecture consistently outperforms existing 3D and multi-plane models in terms of accuracy and AUC. Ablation studies further confirm the importance of axial-centric query-key-value allocation and directional cross-plane fusion. These results highlight the importance of aligning architectural design with clinical interpretation workflows for robust and data-efficient 3D medical image analysis.
Text Change Detection in Multilingual Documents Using Image Comparison
Dec 05, 2024Document comparison typically relies on optical character recognition (OCR) as its core technology. However, OCR requires the selection of appropriate language models for each document and the performance of multilingual or hybrid models remains limited. To overcome these challenges, we propose text change detection (TCD) using an image comparison model tailored for multilingual documents. Unlike OCR-based approaches, our method employs word-level text image-to-image comparison to detect changes. Our model generates bidirectional change segmentation maps between the source and target documents. To enhance performance without requiring explicit text alignment or scaling preprocessing, we employ correlations among multi-scale attention features. We also construct a benchmark dataset comprising actual printed and scanned word pairs in various languages to evaluate our model. We validate our approach using our benchmark dataset and public benchmarks Distorted Document Images and the LRDE Document Binarization Dataset. We compare our model against state-of-the-art semantic segmentation and change detection models, as well as to conventional OCR-based models.
RICAU-Net: Residual-block Inspired Coordinate Attention U-Net for Segmentation of Small and Sparse Calcium Lesions in Cardiac CT
Sep 11, 2024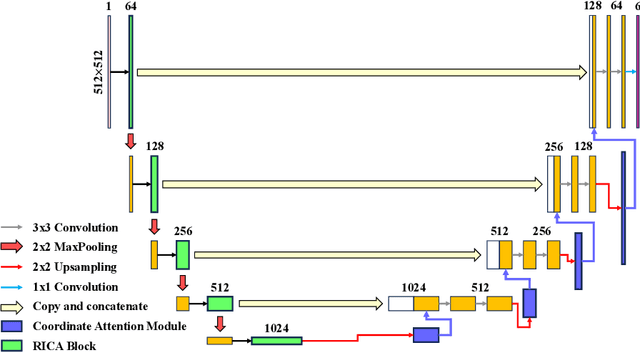
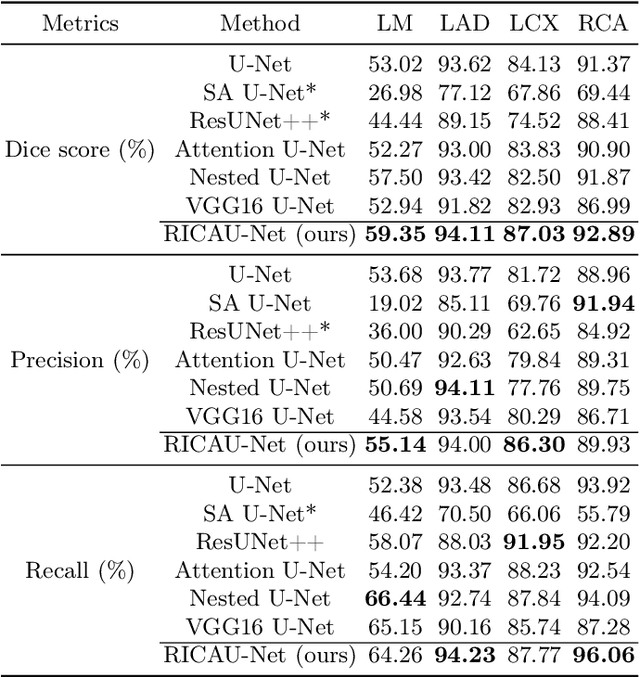
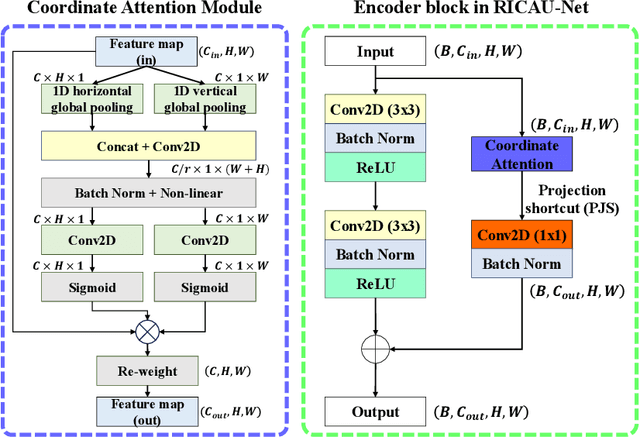
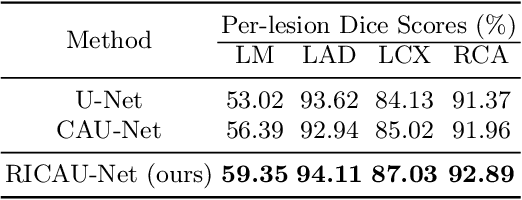
The Agatston score, which is the sum of the calcification in the four main coronary arteries, has been widely used in the diagnosis of coronary artery disease (CAD). However, many studies have emphasized the importance of the vessel-specific Agatston score, as calcification in a specific vessel is significantly correlated with the occurrence of coronary heart disease (CHD). In this paper, we propose the Residual-block Inspired Coordinate Attention U-Net (RICAU-Net), which incorporates coordinate attention in two distinct manners and a customized combo loss function for lesion-specific coronary artery calcium (CAC) segmentation. This approach aims to tackle the high class-imbalance issue associated with small and sparse lesions, particularly for CAC in the left main coronary artery (LM) which is generally small and the scarcest in the dataset due to its anatomical structure. The proposed method was compared with six different methods using Dice score, precision, and recall. Our approach achieved the highest per-lesion Dice scores for all four lesions, especially for CAC in LM compared to other methods. The ablation studies demonstrated the significance of positional information from the coordinate attention and the customized loss function in segmenting small and sparse lesions with a high class-imbalance problem.
D-Score: A Synapse-Inspired Approach for Filter Pruning
Aug 08, 2023This paper introduces a new aspect for determining the rank of the unimportant filters for filter pruning on convolutional neural networks (CNNs). In the human synaptic system, there are two important channels known as excitatory and inhibitory neurotransmitters that transmit a signal from a neuron to a cell. Adopting the neuroscientific perspective, we propose a synapse-inspired filter pruning method, namely Dynamic Score (D-Score). D-Score analyzes the independent importance of positive and negative weights in the filters and ranks the independent importance by assigning scores. Filters having low overall scores, and thus low impact on the accuracy of neural networks are pruned. The experimental results on CIFAR-10 and ImageNet datasets demonstrate the effectiveness of our proposed method by reducing notable amounts of FLOPs and Params without significant Acc. Drop.