 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSGuard-v1: Safety Guardrail for Large Language Models
Nov 16, 2025We present SGuard-v1, a lightweight safety guardrail for Large Language Models (LLMs), which comprises two specialized models to detect harmful content and screen adversarial prompts in human-AI conversational settings. The first component, ContentFilter, is trained to identify safety risks in LLM prompts and responses in accordance with the MLCommons hazard taxonomy, a comprehensive framework for trust and safety assessment of AI. The second component, JailbreakFilter, is trained with a carefully designed curriculum over integrated datasets and findings from prior work on adversarial prompting, covering 60 major attack types while mitigating false-unsafe classification. SGuard-v1 is built on the 2B-parameter Granite-3.3-2B-Instruct model that supports 12 languages. We curate approximately 1.4 million training instances from both collected and synthesized data and perform instruction tuning on the base model, distributing the curated data across the two component according to their designated functions. Through extensive evaluation on public and proprietary safety benchmarks, SGuard-v1 achieves state-of-the-art safety performance while remaining lightweight, thereby reducing deployment overhead. SGuard-v1 also improves interpretability for downstream use by providing multi-class safety predictions and their binary confidence scores. We release the SGuard-v1 under the Apache-2.0 License to enable further research and practical deployment in AI safety.
Less for More: Enhancing Preference Learning in Generative Language Models with Automated Self-Curation of Training Corpora
Aug 23, 2024



Ambiguity in language presents challenges in developing more enhanced language models, particularly in preference learning, where variability among annotators results in inconsistently annotated datasets used for model alignment. To address this issue, we introduce a self-curation method that preprocesses annotated datasets by leveraging proxy models trained directly on these datasets. Our method enhances preference learning by automatically detecting and removing ambiguous annotations within the dataset. The proposed approach is validated through extensive experiments, demonstrating a marked improvement in performance across various instruction-following tasks. Our work provides a straightforward and reliable method to overcome annotation inconsistencies, serving as an initial step towards the development of more advanced preference learning techniques.
Improving Instruction Following in Language Models through Proxy-Based Uncertainty Estimation
May 10, 2024



Assessing response quality to instructions in language models is vital but challenging due to the complexity of human language across different contexts. This complexity often results in ambiguous or inconsistent interpretations, making accurate assessment difficult. To address this issue, we propose a novel Uncertainty-aware Reward Model (URM) that introduces a robust uncertainty estimation for the quality of paired responses based on Bayesian approximation. Trained with preference datasets, our uncertainty-enabled proxy not only scores rewards for responses but also evaluates their inherent uncertainty. Empirical results demonstrate significant benefits of incorporating the proposed proxy into language model training. Our method boosts the instruction following capability of language models by refining data curation for training and improving policy optimization objectives, thereby surpassing existing methods by a large margin on benchmarks such as Vicuna and MT-bench. These findings highlight that our proposed approach substantially advances language model training and paves a new way of harnessing uncertainty within language models.
V-STRONG: Visual Self-Supervised Traversability Learning for Off-road Navigation
Dec 26, 2023



Reliable estimation of terrain traversability is critical for the successful deployment of autonomous systems in wild, outdoor environments. Given the lack of large-scale annotated datasets for off-road navigation, strictly-supervised learning approaches remain limited in their generalization ability. To this end, we introduce a novel, image-based self-supervised learning method for traversability prediction, leveraging a state-of-the-art vision foundation model for improved out-of-distribution performance. Our method employs contrastive representation learning using both human driving data and instance-based segmentation masks during training. We show that this simple, yet effective, technique drastically outperforms recent methods in predicting traversability for both on- and off-trail driving scenarios. We compare our method with recent baselines on both a common benchmark as well as our own datasets, covering a diverse range of outdoor environments and varied terrain types. We also demonstrate the compatibility of resulting costmap predictions with a model-predictive controller. Finally, we evaluate our approach on zero- and few-shot tasks, demonstrating unprecedented performance for generalization to new environments. Videos and additional material can be found here: \url{https://sites.google.com/view/visual-traversability-learning}.
LiDAR-UDA: Self-ensembling Through Time for Unsupervised LiDAR Domain Adaptation
Sep 24, 2023We introduce LiDAR-UDA, a novel two-stage self-training-based Unsupervised Domain Adaptation (UDA) method for LiDAR segmentation. Existing self-training methods use a model trained on labeled source data to generate pseudo labels for target data and refine the predictions via fine-tuning the network on the pseudo labels. These methods suffer from domain shifts caused by different LiDAR sensor configurations in the source and target domains. We propose two techniques to reduce sensor discrepancy and improve pseudo label quality: 1) LiDAR beam subsampling, which simulates different LiDAR scanning patterns by randomly dropping beams; 2) cross-frame ensembling, which exploits temporal consistency of consecutive frames to generate more reliable pseudo labels. Our method is simple, generalizable, and does not incur any extra inference cost. We evaluate our method on several public LiDAR datasets and show that it outperforms the state-of-the-art methods by more than $3.9\%$ mIoU on average for all scenarios. Code will be available at https://github.com/JHLee0513/LiDARUDA.
Unsupervised Accuracy Estimation of Deep Visual Models using Domain-Adaptive Adversarial Perturbation without Source Samples
Jul 19, 2023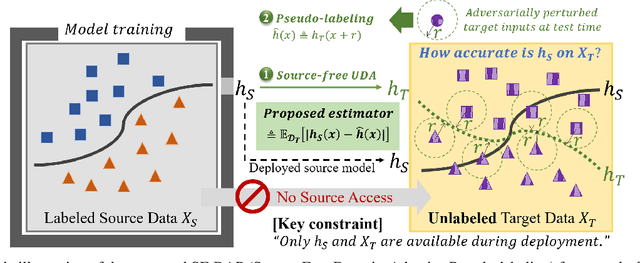



Deploying deep visual models can lead to performance drops due to the discrepancies between source and target distributions. Several approaches leverage labeled source data to estimate target domain accuracy, but accessing labeled source data is often prohibitively difficult due to data confidentiality or resource limitations on serving devices. Our work proposes a new framework to estimate model accuracy on unlabeled target data without access to source data. We investigate the feasibility of using pseudo-labels for accuracy estimation and evolve this idea into adopting recent advances in source-free domain adaptation algorithms. Our approach measures the disagreement rate between the source hypothesis and the target pseudo-labeling function, adapted from the source hypothesis. We mitigate the impact of erroneous pseudo-labels that may arise due to a high ideal joint hypothesis risk by employing adaptive adversarial perturbation on the input of the target model. Our proposed source-free framework effectively addresses the challenging distribution shift scenarios and outperforms existing methods requiring source data and labels for training.
TerrainNet: Visual Modeling of Complex Terrain for High-speed, Off-road Navigation
Mar 28, 2023



Effective use of camera-based vision systems is essential for robust performance in autonomous off-road driving, particularly in the high-speed regime. Despite success in structured, on-road settings, current end-to-end approaches for scene prediction have yet to be successfully adapted for complex outdoor terrain. To this end, we present TerrainNet, a vision-based terrain perception system for semantic and geometric terrain prediction for aggressive, off-road navigation. The approach relies on several key insights and practical considerations for achieving reliable terrain modeling. The network includes a multi-headed output representation to capture fine- and coarse-grained terrain features necessary for estimating traversability. Accurate depth estimation is achieved using self-supervised depth completion with multi-view RGB and stereo inputs. Requirements for real-time performance and fast inference speeds are met using efficient, learned image feature projections. Furthermore, the model is trained on a large-scale, real-world off-road dataset collected across a variety of diverse outdoor environments. We show how TerrainNet can also be used for costmap prediction and provide a detailed framework for integration into a planning module. We demonstrate the performance of TerrainNet through extensive comparison to current state-of-the-art baselines for camera-only scene prediction. Finally, we showcase the effectiveness of integrating TerrainNet within a complete autonomous-driving stack by conducting a real-world vehicle test in a challenging off-road scenario.
Unsupervised Domain Adaptation Based on the Predictive Uncertainty of Models
Nov 16, 2022Unsupervised domain adaptation (UDA) aims to improve the prediction performance in the target domain under distribution shifts from the source domain. The key principle of UDA is to minimize the divergence between the source and the target domains. To follow this principle, many methods employ a domain discriminator to match the feature distributions. Some recent methods evaluate the discrepancy between two predictions on target samples to detect those that deviate from the source distribution. However, their performance is limited because they either match the marginal distributions or measure the divergence conservatively. In this paper, we present a novel UDA method that learns domain-invariant features that minimize the domain divergence. We propose model uncertainty as a measure of the domain divergence. Our UDA method based on model uncertainty (MUDA) adopts a Bayesian framework and provides an efficient way to evaluate model uncertainty by means of Monte Carlo dropout sampling. Empirical results on image recognition tasks show that our method is superior to existing state-of-the-art methods. We also extend MUDA to multi-source domain adaptation problems.
Feature Alignment by Uncertainty and Self-Training for Source-Free Unsupervised Domain Adaptation
Aug 31, 2022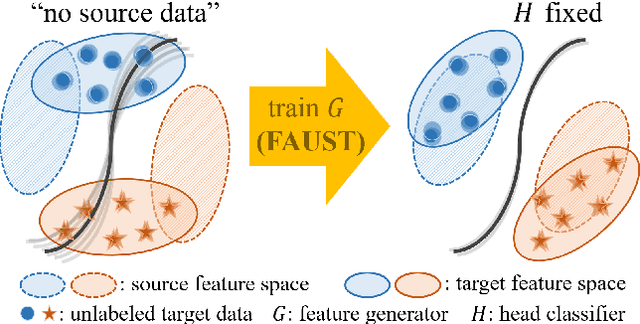
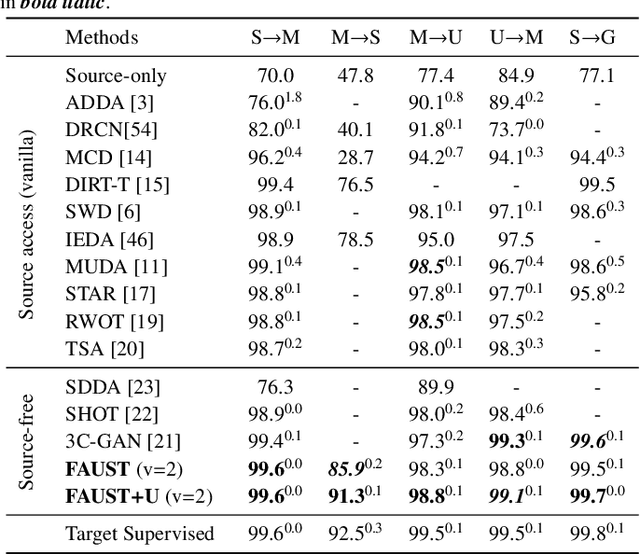
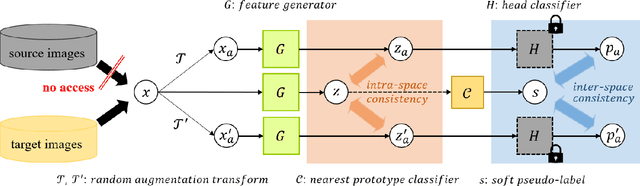
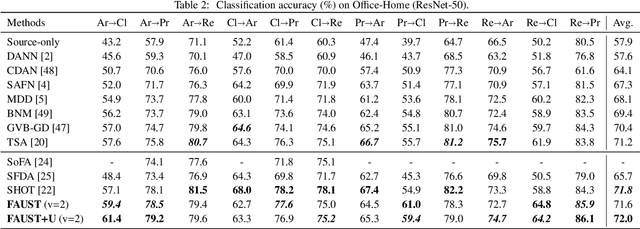
Most unsupervised domain adaptation (UDA) methods assume that labeled source images are available during model adaptation. However, this assumption is often infeasible owing to confidentiality issues or memory constraints on mobile devices. To address these problems, we propose a simple yet effective source-free UDA method that uses only a pre-trained source model and unlabeled target images. Our method captures the aleatoric uncertainty by incorporating data augmentation and trains the feature generator with two consistency objectives. The feature generator is encouraged to learn consistent visual features away from the decision boundaries of the head classifier. Inspired by self-supervised learning, our method promotes inter-space alignment between the prediction space and the feature space while incorporating intra-space consistency within the feature space to reduce the domain gap between the source and target domains. We also consider epistemic uncertainty to boost the model adaptation performance. Extensive experiments on popular UDA benchmarks demonstrate that the performance of our approach is comparable or even superior to vanilla UDA methods without using source images or network modifications.
REFUGE Challenge: A Unified Framework for Evaluating Automated Methods for Glaucoma Assessment from Fundus Photographs
Oct 08, 2019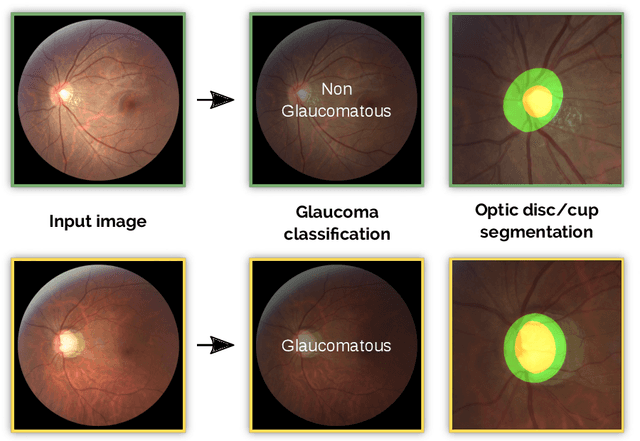
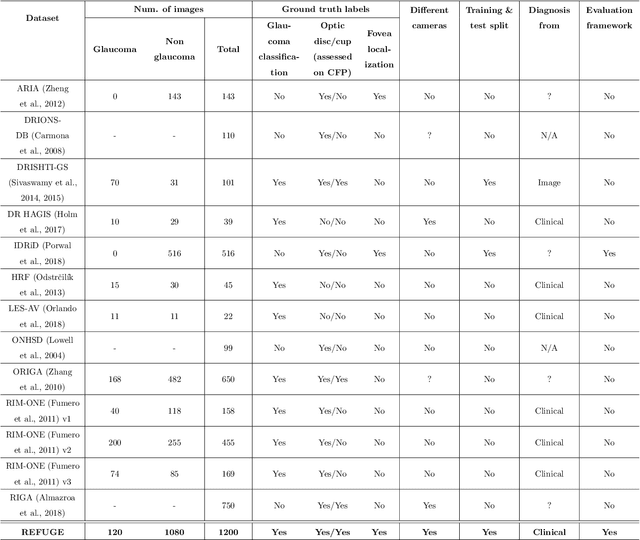

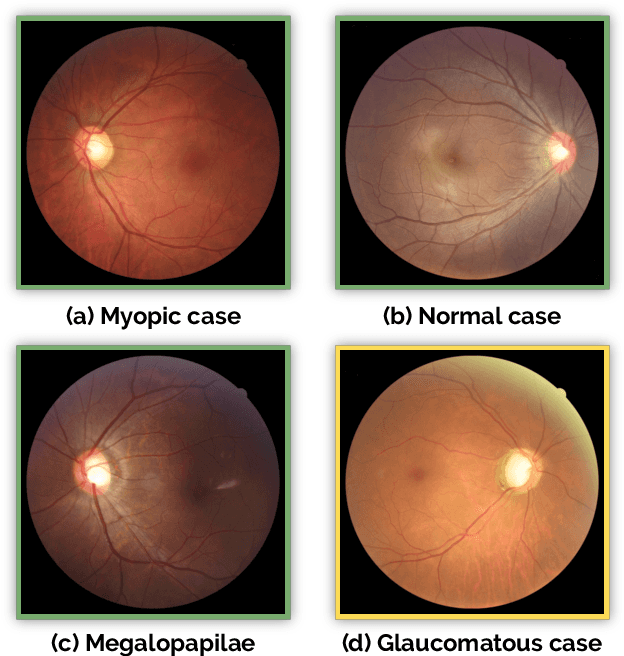
Glaucoma is one of the leading causes of irreversible but preventable blindness in working age populations. Color fundus photography (CFP) is the most cost-effective imaging modality to screen for retinal disorders. However, its application to glaucoma has been limited to the computation of a few related biomarkers such as the vertical cup-to-disc ratio. Deep learning approaches, although widely applied for medical image analysis, have not been extensively used for glaucoma assessment due to the limited size of the available data sets. Furthermore, the lack of a standardize benchmark strategy makes difficult to compare existing methods in a uniform way. In order to overcome these issues we set up the Retinal Fundus Glaucoma Challenge, REFUGE (\url{https://refuge.grand-challenge.org}), held in conjunction with MICCAI 2018. The challenge consisted of two primary tasks, namely optic disc/cup segmentation and glaucoma classification. As part of REFUGE, we have publicly released a data set of 1200 fundus images with ground truth segmentations and clinical glaucoma labels, currently the largest existing one. We have also built an evaluation framework to ease and ensure fairness in the comparison of different models, encouraging the development of novel techniques in the field. 12 teams qualified and participated in the online challenge. This paper summarizes their methods and analyzes their corresponding results. In particular, we observed that two of the top-ranked teams outperformed two human experts in the glaucoma classification task. Furthermore, the segmentation results were in general consistent with the ground truth annotations, with complementary outcomes that can be further exploited by ensembling the results.