 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Domain Adaptation Based on the Predictive Uncertainty of Models
Nov 16, 2022Unsupervised domain adaptation (UDA) aims to improve the prediction performance in the target domain under distribution shifts from the source domain. The key principle of UDA is to minimize the divergence between the source and the target domains. To follow this principle, many methods employ a domain discriminator to match the feature distributions. Some recent methods evaluate the discrepancy between two predictions on target samples to detect those that deviate from the source distribution. However, their performance is limited because they either match the marginal distributions or measure the divergence conservatively. In this paper, we present a novel UDA method that learns domain-invariant features that minimize the domain divergence. We propose model uncertainty as a measure of the domain divergence. Our UDA method based on model uncertainty (MUDA) adopts a Bayesian framework and provides an efficient way to evaluate model uncertainty by means of Monte Carlo dropout sampling. Empirical results on image recognition tasks show that our method is superior to existing state-of-the-art methods. We also extend MUDA to multi-source domain adaptation problems.
Feature Alignment by Uncertainty and Self-Training for Source-Free Unsupervised Domain Adaptation
Aug 31, 2022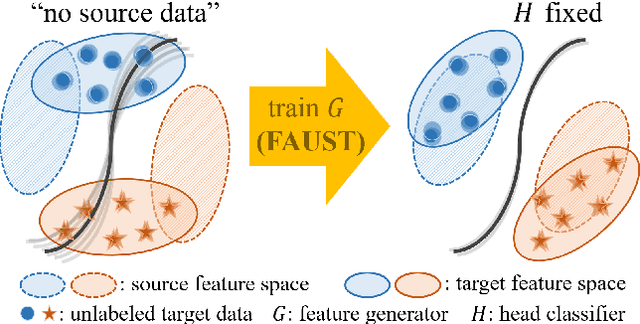
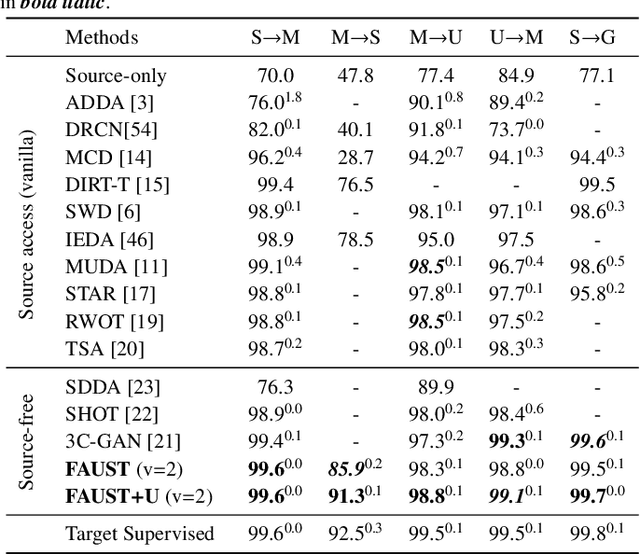
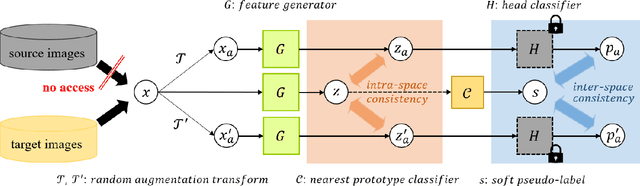
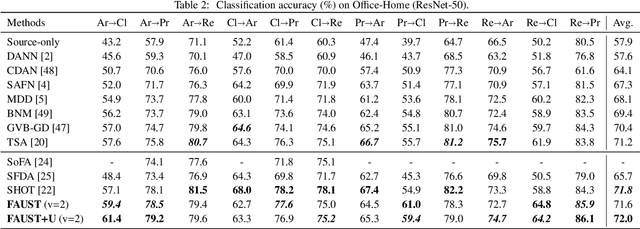
Most unsupervised domain adaptation (UDA) methods assume that labeled source images are available during model adaptation. However, this assumption is often infeasible owing to confidentiality issues or memory constraints on mobile devices. To address these problems, we propose a simple yet effective source-free UDA method that uses only a pre-trained source model and unlabeled target images. Our method captures the aleatoric uncertainty by incorporating data augmentation and trains the feature generator with two consistency objectives. The feature generator is encouraged to learn consistent visual features away from the decision boundaries of the head classifier. Inspired by self-supervised learning, our method promotes inter-space alignment between the prediction space and the feature space while incorporating intra-space consistency within the feature space to reduce the domain gap between the source and target domains. We also consider epistemic uncertainty to boost the model adaptation performance. Extensive experiments on popular UDA benchmarks demonstrate that the performance of our approach is comparable or even superior to vanilla UDA methods without using source images or network modifications.
Domain Generalization by Marginal Transfer Learning
Nov 21, 2017



Domain generalization is the problem of assigning class labels to an unlabeled test data set, given several labeled training data sets drawn from similar distributions. This problem arises in several applications where data distributions fluctuate because of biological, technical, or other sources of variation. We develop a distribution-free, kernel-based approach that predicts a classifier from the marginal distribution of features, by leveraging the trends present in related classification tasks. This approach involves identifying an appropriate reproducing kernel Hilbert space and optimizing a regularized empirical risk over the space. We present generalization error analysis, describe universal kernels, and establish universal consistency of the proposed methodology. Experimental results on synthetic data and three real data applications demonstrate the superiority of the method with respect to a pooling strategy.