 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Instruction Following in Language Models through Proxy-Based Uncertainty Estimation
May 10, 2024



Assessing response quality to instructions in language models is vital but challenging due to the complexity of human language across different contexts. This complexity often results in ambiguous or inconsistent interpretations, making accurate assessment difficult. To address this issue, we propose a novel Uncertainty-aware Reward Model (URM) that introduces a robust uncertainty estimation for the quality of paired responses based on Bayesian approximation. Trained with preference datasets, our uncertainty-enabled proxy not only scores rewards for responses but also evaluates their inherent uncertainty. Empirical results demonstrate significant benefits of incorporating the proposed proxy into language model training. Our method boosts the instruction following capability of language models by refining data curation for training and improving policy optimization objectives, thereby surpassing existing methods by a large margin on benchmarks such as Vicuna and MT-bench. These findings highlight that our proposed approach substantially advances language model training and paves a new way of harnessing uncertainty within language models.
Near-Optimal Fair Resource Allocation for Strategic Agents without Money: A Data-Driven Approach
Nov 18, 2023


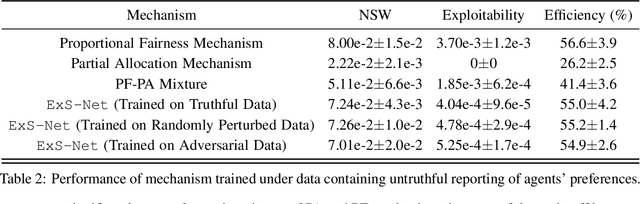
We study learning-based design of fair allocation mechanisms for divisible resources, using proportional fairness (PF) as a benchmark. The learning setting is a significant departure from the classic mechanism design literature, in that, we need to learn fair mechanisms solely from data. In particular, we consider the challenging problem of learning one-shot allocation mechanisms -- without the use of money -- that incentivize strategic agents to be truthful when reporting their valuations. It is well-known that the mechanism that directly seeks to optimize PF is not incentive compatible, meaning that the agents can potentially misreport their preferences to gain increased allocations. We introduce the notion of "exploitability" of a mechanism to measure the relative gain in utility from misreport, and make the following important contributions in the paper: (i) Using sophisticated techniques inspired by differentiable convex programming literature, we design a numerically efficient approach for computing the exploitability of the PF mechanism. This novel contribution enables us to quantify the gap that needs to be bridged to approximate PF via incentive compatible mechanisms. (ii) Next, we modify the PF mechanism to introduce a trade-off between fairness and exploitability. By properly controlling this trade-off using data, we show that our proposed mechanism, ExPF-Net, provides a strong approximation to the PF mechanism while maintaining low exploitability. This mechanism, however, comes with a high computational cost. (iii) To address the computational challenges, we propose another mechanism ExS-Net, which is end-to-end parameterized by a neural network. ExS-Net enjoys similar (slightly inferior) performance and significantly accelerated training and inference time performance. (iv) Extensive numerical simulations demonstrate the robustness and efficacy of the proposed mechanisms.
Sequential Fair Resource Allocation under a Markov Decision Process Framework
Jan 10, 2023



We study the sequential decision-making problem of allocating a limited resource to agents that reveal their stochastic demands on arrival over a finite horizon. Our goal is to design fair allocation algorithms that exhaust the available resource budget. This is challenging in sequential settings where information on future demands is not available at the time of decision-making. We formulate the problem as a discrete time Markov decision process (MDP). We propose a new algorithm, SAFFE, that makes fair allocations with respect to the entire demands revealed over the horizon by accounting for expected future demands at each arrival time. The algorithm introduces regularization which enables the prioritization of current revealed demands over future potential demands depending on the uncertainty in agents' future demands. Using the MDP formulation, we show that SAFFE optimizes allocations based on an upper bound on the Nash Social Welfare fairness objective, and we bound its gap to optimality with the use of concentration bounds on total future demands. Using synthetic and real data, we compare the performance of SAFFE against existing approaches and a reinforcement learning policy trained on the MDP. We show that SAFFE leads to more fair and efficient allocations and achieves close-to-optimal performance in settings with dense arrivals.
Certifiably Robust Policy Learning against Adversarial Communication in Multi-agent Systems
Jul 02, 2022
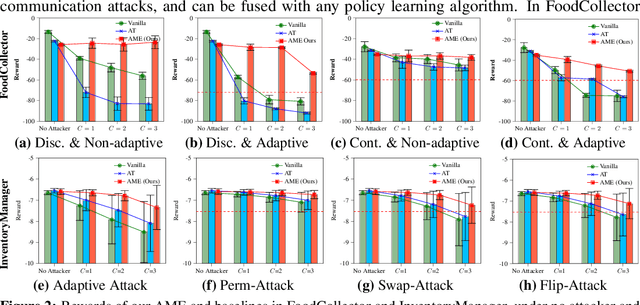
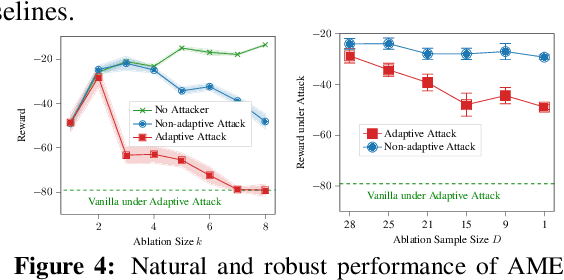
Communication is important in many multi-agent reinforcement learning (MARL) problems for agents to share information and make good decisions. However, when deploying trained communicative agents in a real-world application where noise and potential attackers exist, the safety of communication-based policies becomes a severe issue that is underexplored. Specifically, if communication messages are manipulated by malicious attackers, agents relying on untrustworthy communication may take unsafe actions that lead to catastrophic consequences. Therefore, it is crucial to ensure that agents will not be misled by corrupted communication, while still benefiting from benign communication. In this work, we consider an environment with $N$ agents, where the attacker may arbitrarily change the communication from any $C<\frac{N-1}{2}$ agents to a victim agent. For this strong threat model, we propose a certifiable defense by constructing a message-ensemble policy that aggregates multiple randomly ablated message sets. Theoretical analysis shows that this message-ensemble policy can utilize benign communication while being certifiably robust to adversarial communication, regardless of the attacking algorithm. Experiments in multiple environments verify that our defense significantly improves the robustness of trained policies against various types of attacks.
Generative Models with Information-Theoretic Protection Against Membership Inference Attacks
May 31, 2022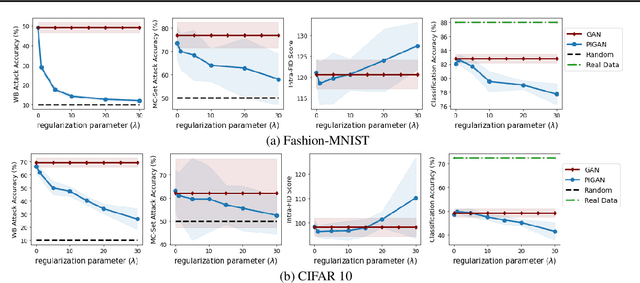

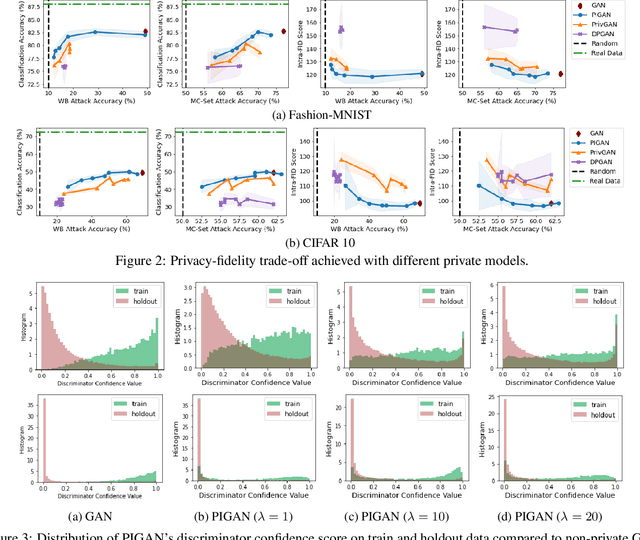

Deep generative models, such as Generative Adversarial Networks (GANs), synthesize diverse high-fidelity data samples by estimating the underlying distribution of high dimensional data. Despite their success, GANs may disclose private information from the data they are trained on, making them susceptible to adversarial attacks such as membership inference attacks, in which an adversary aims to determine if a record was part of the training set. We propose an information theoretically motivated regularization term that prevents the generative model from overfitting to training data and encourages generalizability. We show that this penalty minimizes the JensenShannon divergence between components of the generator trained on data with different membership, and that it can be implemented at low cost using an additional classifier. Our experiments on image datasets demonstrate that with the proposed regularization, which comes at only a small added computational cost, GANs are able to preserve privacy and generate high-quality samples that achieve better downstream classification performance compared to non-private and differentially private generative models.
Optimal Admission Control for Multiclass Queues with Time-Varying Arrival Rates via State Abstraction
Mar 14, 2022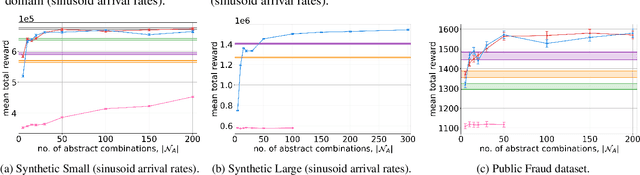
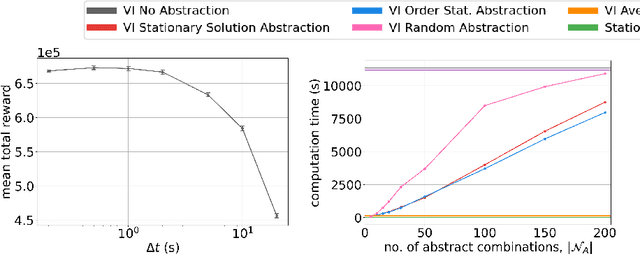
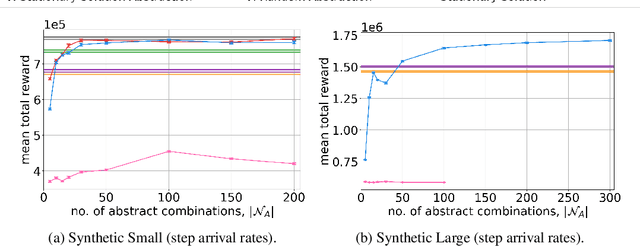
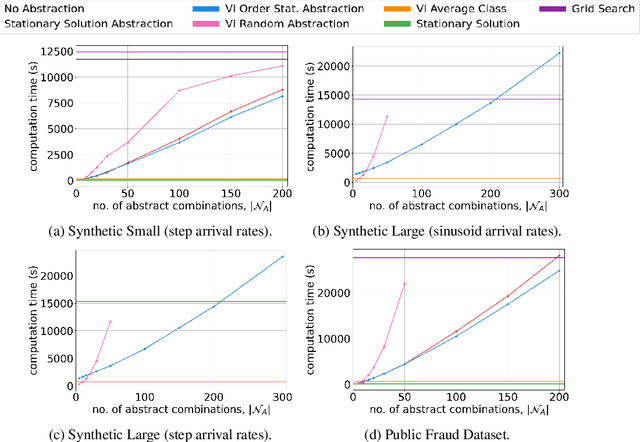
We consider a novel queuing problem where the decision-maker must choose to accept or reject randomly arriving tasks into a no buffer queue which are processed by $N$ identical servers. Each task has a price, which is a positive real number, and a class. Each class of task has a different price distribution and service rate, and arrives according to an inhomogenous Poisson process. The objective is to decide which tasks to accept so that the total price of tasks processed is maximised over a finite horizon. We formulate the problem as a discrete time Markov Decision Process (MDP) with a hybrid state space. We show that the optimal value function has a specific structure, which enables us to solve the hybrid MDP exactly. Moreover, we prove that as the time step is reduced, the discrete time solution approaches the optimal solution to the original continuous time problem. To improve the scalability of our approach to a greater number of task classes, we present an approximation based on state abstraction. We validate our approach on synthetic data, as well as a real financial fraud data set, which is the motivating application for this work.
Tradeoffs in Streaming Binary Classification under Limited Inspection Resources
Oct 05, 2021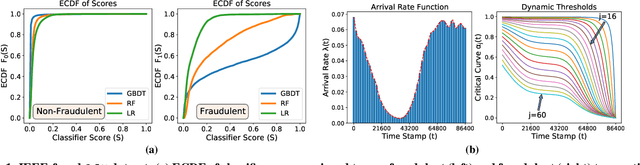
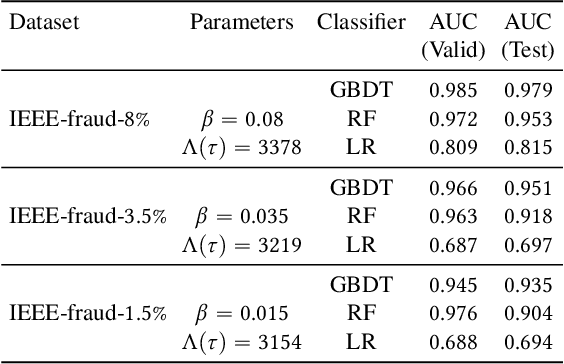
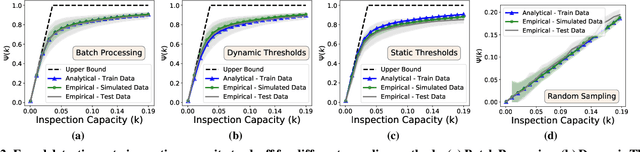
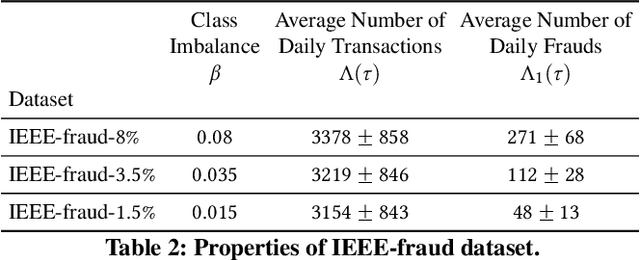
Institutions are increasingly relying on machine learning models to identify and alert on abnormal events, such as fraud, cyber attacks and system failures. These alerts often need to be manually investigated by specialists. Given the operational cost of manual inspections, the suspicious events are selected by alerting systems with carefully designed thresholds. In this paper, we consider an imbalanced binary classification problem, where events arrive sequentially and only a limited number of suspicious events can be inspected. We model the event arrivals as a non-homogeneous Poisson process, and compare various suspicious event selection methods including those based on static and adaptive thresholds. For each method, we analytically characterize the tradeoff between the minority-class detection rate and the inspection capacity as a function of the data class imbalance and the classifier confidence score densities. We implement the selection methods on a real public fraud detection dataset and compare the empirical results with analytical bounds. Finally, we investigate how class imbalance and the choice of classifier impact the tradeoff.
Non-Parametric Stochastic Sequential Assignment With Random Arrival Times
Jun 09, 2021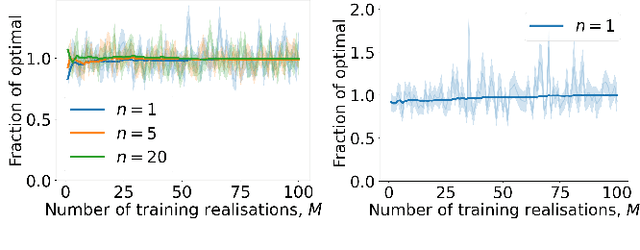

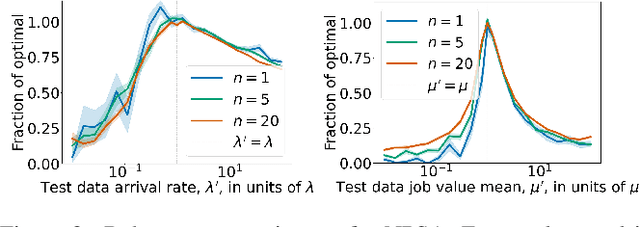

We consider a problem wherein jobs arrive at random times and assume random values. Upon each job arrival, the decision-maker must decide immediately whether or not to accept the job and gain the value on offer as a reward, with the constraint that they may only accept at most $n$ jobs over some reference time period. The decision-maker only has access to $M$ independent realisations of the job arrival process. We propose an algorithm, Non-Parametric Sequential Allocation (NPSA), for solving this problem. Moreover, we prove that the expected reward returned by the NPSA algorithm converges in probability to optimality as $M$ grows large. We demonstrate the effectiveness of the algorithm empirically on synthetic data and on public fraud-detection datasets, from where the motivation for this work is derived.